
Dans le cadre de ma formation continue de Data Analyst chez DataScientest, j’ai découvert le concept et les atouts des bases de données graphiques. Ayant entrevu les avantages qu’on pouvait en obtenir, j’ai entrepris de m’autoformer à Neo4J.
Il y a quelques années, j’avais voulu mettre au point un outil capable de trouver le meilleur trajet en métro. J’y étais parvenu, mais l’exécution de la requête SQL était relativement longue : plus de 3 secondes.
J’ai donc entrepris de retenter l’expérience en utilisant Neo4J. Je tiens à préciser que je suis débutant en langage Cypher. Il existe probablement d’autres méthodes plus efficaces ou plus élégantes pour traiter ce sujet que celle que j’ai employée.
1) Intégration des données dans une base Neo4J
Pour construire ma base de données graphique, j’ai utilisé les données disponibles sur l’open data de la RATP. Je n’entrerai pas dans le détail du pré traitement (qui pourrait constituer à lui seul un sujet d’article).
Dans un premier temps, j’ai déclaré chaque station de métro en tant que nœud. Le but était d’avoir un seul identifiant par station afin qu’une station desservie par plusieurs lignes puisse être identifiée comme susceptible d’assurer les correspondances.
Exemple : CREATE (chanes :Station {nom: ‘Château de Vincennes’}) .
Dans cette ligne, je crée la station « Château de Vincennes » avec l’identifiant unique « chanes » que j’ai généré en amont.
Par la suite, à partir des trajets contenus dans les données de la RATP, j’ai déclaré les relations entre les nœuds afin de reconstituer les différentes lignes.
Examinons les 3 lignes suivantes :
Les identifiants chanes, berult, sainde et pornes correspondent aux stations Château de Vincenne, Berault, St Mandé et Porte de Vincennes. Ainsi se dessine le début de la ligne 1 du métro.
Pour la recherche du meilleur trajet entre deux stations, on peut se contenter de définir le parcours d’une ligne dans une seule direction (dans le cas de la ligne 1, en direction de La Défense).
Dans ce fichier, vous trouverez le script complet pour incorporer les données. L’ensemble des lignes principales du métro y figurent (hors lignes bis), mais les stations les plus récemment ouvertes ne sont pas forcément intégrées.

2) Trouver le meilleur trajet entre deux stations de métro avec Neo4J. Un jeu d’enfant ?
L’un des principaux atouts de Neo4J est de permettre de trouver facilement le plus court chemin séparant deux nœuds. Dans notre cas, deux stations de métro.
En théorie, il suffit d’écrire 4 lignes pour résoudre notre problème.
Tout d’abord, déclarer les stations de départ et d’arrivée :
Ensuite, utiliser la commande SHORTESTPATH pour identifier le plus court trajet :
Lorsque on lance ce script, on obtient le résultat suivant :

On obtient très certainement le trajet le plus court, à savoir celui comportant le moins d’arrêts en station, mais certainement pas le plus pratique ! En effet, Ce trajet fait emprunter quatre lignes de métro différentes alors qu’en changeant à Sèvres Babylone on obtiendrait un trajet certes plus long mais avec un seul changement.
Il va donc falloir ruser.
3) Enrichissement du code pour permettre de trouver un trajet à la fois court et pratique
Afin de limiter les correspondances, j’ai choisi de procéder par étapes :
- recherche de l’existence d’un trajet direct ou avec une seule correspondance ;
- recherche d’un trajet impliquant plus de correspondances ;
- arbitrage entre ces 2 alternatives pour obtenir le trajet le plus pratique.
Les deux premières lignes du script restent inchangées. J’ai déclaré les lignes de départ et d’arrivée :
Ensuite, j’ai récupéré les numéros de lignes connectées aux stations de départ et d’arrivée pour limiter la recherche d’un trajet uniquement sur ces lignes. J’ai ainsi évité le recours à d’autres lignes de métro qui pourraient raccourcir le nombre de stations empruntées mais qui augmenteraient le nombre de correspondances.
Vous noterez que j’ai utilisé la clause OPTIONAL MATCH pour rechercher un trajet. En effet, si les stations de départ et d’arrivée n’étaient reliées par aucune ligne commune, ma requête finale ne retournerait aucun résultat.
Il me restait maintenant à coder la recherche d’un trajet ne se limitant pas aux seules lignes reliant les stations de départ et d’arrivée. A première vue, on pourrait penser qu’il suffisait de reprendre l’utilisation de SHORTESTPATH, mais les choses ne sont malheureusement pas si simples. En effet, le métro parisien est si dense que sur certains trajets, Neo4J peut proposer un itinéraire impliquant une correspondance supplémentaire pour économiser seulement un ou deux passages en station au prix d’une correspondance qui prend finalement plus de temps.
Pour contourner ce problème, je suis parti du postulat suivant : au vu des caractéristiques du métro parisien, il est inutile de rechercher des trajets impliquant plus de deux correspondances. En conséquence, j’ai laissé Neo4J rechercher librement le plus court chemin en stockant les différentes lignes de correspondances empruntées.
Par la suite, j’ai créé une nouvelle requête forçant Neo4J à se limiter à 2 correspondances en lui faisant uniquement retenir les lignes connectant les stations de départ et d’arrivée plus une seule des autres lignes de correspondance éventuellement empruntées lors de la recherche du trajet le plus court.
En terme de codage, cela donne ceci :
Si nous nous arrêtions à ce stade et que nous affichions les résultats de ces requêtes, nous obtiendrions le résultat suivant pour le trajet Convention — Cardinal Lemoine :
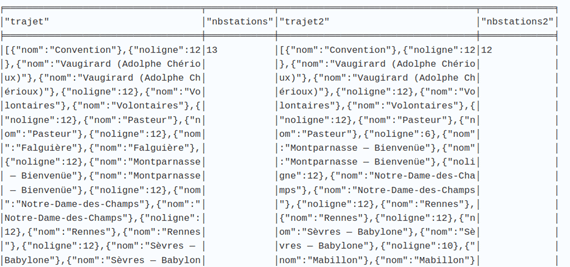
La seule différence est une brève incursion sur la ligne 6 pour éviter la station Falguière. Dans le cas présent, le différentiel de stations n’est pas très spectaculaire, mais cela pourrait le devenir en prenant un autre exemple comme le trajet entre les stations Balard et Alésia.
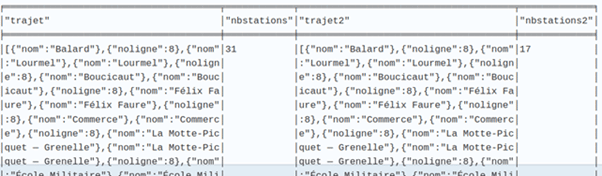
Dans ce cas, le différentiel entre les 2 trajets est beaucoup plus important.
Dernière étape : faire le meilleur choix entre ces 2 possibilités en utilisant CASE. Le trajet final est celui qui comporte le moins de stations empruntées. Cependant, pour compenser le temps pris pour emprunter une correspondance, j’ai ajouté un handicap de 5 stations (ce qui correspond plus ou moins à 5 minutes) pour favoriser le trajet comportant le moins de correspondances.
En exécutant le code complet, voici ce qu’on obtient pour le trajet Convention — Cardinal Lemoine :

Il s’agit effectivement du trajet le plus pratique entre les deux stations.
4) Conclusion
Lorsque j’avais travaillé sur le même projet en SQL, le code était relativement lourd et les temps d’exécution longs (plus de 3 secondes). Grâce aux caractéristiques de Neo4J le code est plus léger et les temps d’exécution beaucoup plus courts : moins d’une demi seconde.
Neo4J a donc bien tenu ses promesses pour déterminer plus facilement et rapidement le trajet le plus commode entre deux stations de métro, moyennant quelques aménagements pour limiter le nombre de correspondances.
Pour finir, je dois souligner l’apport de ma formation chez DataScientest dans ma démarche d’autoformation. En effet, bien que nous bénéficions de toute l’aide dont nous avions besoin, notre formation nous a entrainés à être le plus autonome possible. De ce fait, il nous est beaucoup plus facile, par la suite, de nous autoformer. C’est crucial dans la data, où la veille technologique constitue une activité de fond dans ce domaine qui évolue très rapidement.
Retrouvez le code complet du projet








