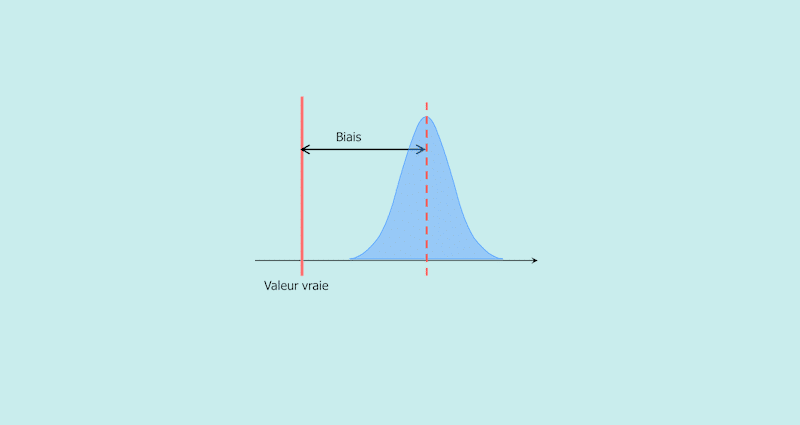
Le biais statistique peut être défini comme tout ce qui conduit à une différence systématique entre les vrais paramètres d'une population et les statistiques utilisées pour estimer ces paramètres. Il existe une longue liste de types de biais de statistique.
Nous avons décidé de vous présenter ces quatre types, car ce sont ceux que nous voyons le plus affecter le quotidien des Data Scientists et Analystes.
Nous allons vous les décrire et vous en donner un exemple concret.
1) Biais de sélection
Le biais de sélection a lieu lorsque, comme son nom l’indique, la sélection de données est fausse. Cela signifie en général, que vous travaillez avec un sous-ensemble spécifique de votre groupe et non un sous-ensemble aléatoire.
Si vous souhaitez par exemple déployer un nouveau produit, avant de dépenser du temps et de l’argent, il vous faut savoir si votre audience est intéressée par celui-ci. Vous réalisez donc une enquête que vous envoyez à vos clients existants. C’est bien sûr une part importante de votre audience, mais elle ne représente absolument pas l’entièreté de votre audience. Vous venez de réaliser un biais de sélection qui peut vous coûter très cher !
2) Biais de rappel
Le biais de rappel est une autre erreur courante dans des situations d’enquête, et notamment de feedback. Il apparaît lorsque les participants ne se souviennent pas d’évènements, de souvenirs ou de détails antérieurs. La mémoire humaine étant sélective par défaut, c’est un phénomène normal mais qui rend plus difficile la recherche.
Le cerveau humain a tendance à se rappeler davantage des bons souvenirs plutôt que des mauvais. Si vous réalisez une enquête à la suite d’une conférence par exemple, il est préférable d’envoyer le formulaire rapidement, si vous voulez qu’il soit plus exact.
3) Biais des survivants
Le biais des survivants est une autre forme de biais de sélections ou le chercheur se concentre uniquement sur le sous-ensemble du groupe ayant déjà été soumis à un processus de présélection.
On retrouve de nombreux cas de biais des survivants dans le secteur militaire. On peut citer par exemple le statisticien Abraham Wald qui a été consulté au cours de la Seconde Guerre mondiale et qui a proposé une idée allant à contre-courant. Il recommande de renforcer les avions revenus de leur missions aux endroits montrant le moins de dommages. En effet, seuls les avions revenus de leur mission ont été étudié.

4) Biais de variable omise
Il s’agit d’un biais qui découle de l’absence de variables pertinentes dans un modèle. En Machine Learning, la suppression de variables pertinentes et/ou d’un trop grand nombre de variables peut rendre ce modèle inutilisable.
Un exemple plus concret serait l’achat d’une voiture en fonction de certains critères mais pas d’autres. Par exemple, imaginez une Bentley Continental 2021 à 20 000 euros, cela semble être une affaire en or, jusqu’à ce que vous découvriez qu’elle a 600 000 km au compteur.
Nous vous avons dressé une liste non exhaustive des principaux biais statistiques que l’on retrouve le plus souvent en Data Science mais aussi dans notre quotidien.
Il nous semble important de conclure sur le fait que les statistiques biaisées sont de mauvaises statistiques. Il faut toujours chercher à minimiser au maximum les biais. Une technique très efficace pour éviter les biais est la randomisation par exemple. Faire en sorte que l’échantillon de l’étude soit tiré au hasard.








