
Vous avez peut-être remarqué que les ordinateurs peuvent désormais apprendre automatiquement à jouer aux jeux ATARI. Ils battent les champions du monde au jeu de Go, les quadrupèdes simulés apprennent à courir et à sauter, et les robots à effectuer des tâches de manipulation complexes défiant l'état de l'art. Toutes ses avancées sont dues à l'éventail des possibilités du Reinforcement Learning.
Reinforcement Learning
Le cœur de l’apprentissage par renforcement est un agent, c’est-à-dire un algorithme capable de prendre des décisions, évoluant dans un environnement. L’agent (IA) recherche à prendre les décisions qui maximisent sa récompense future.
L’apprentissage par renforcement diffère de l’apprentissage supervisé. Dans l’apprentissage supervisé, les données de formation ont le corrigé avec lui, de sorte que le modèle est entraîné avec la bonne réponse elle-même tandis que dans l’apprentissage par renforcement, il n’y a pas de réponse mais l’IA décide quoi faire pour effectuer la tâche donnée. En l’absence de jeu de données d’entraînement, l’intelligence artificielle est donc livrée à elle-même. Elle commencera par prendre des décisions totalement aléatoires et, de récompense en récompense, développera sa propre méthode pour accomplir systématiquement la tâche qui lui est confiée.
Ainsi, cette méthode d’apprentissage présente l’avantage fascinant de laisser la machine faire preuve de « créativité ».
Exemple illustratif
Pour mieux comprendre ce qu’est l’apprentissage par renforcement, il convient de l’illustrer par un exemple simple. Nous avons un agent (rouge), une récompense (jaune) et de nombreux obstacles entre les deux. L’agent est censé trouver le meilleur chemin possible pour atteindre la récompense.
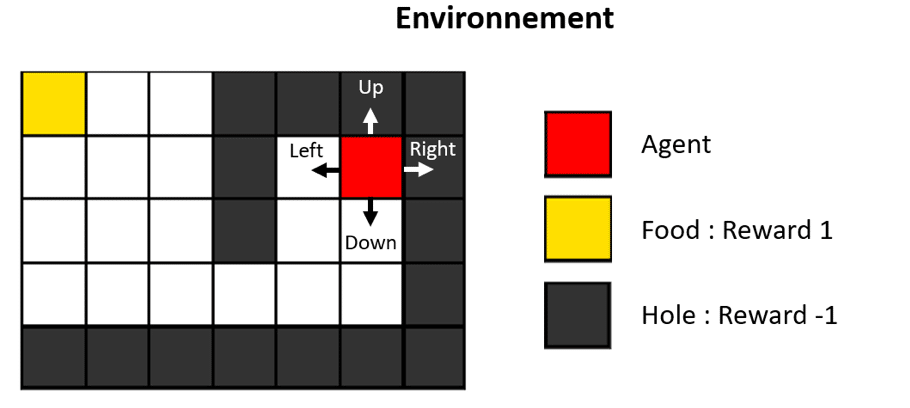
Le but de l’agent est d’obtenir la récompense (la food) et d’éviter de passer sur les obstacles (les trous). Si l’agent passe sur un obstacle, il obtient une récompense de -1 et le jeu est terminé. Si l’agent passe sur la récompense, il obtient une récompense de +1 et le jeu est également terminé.
Définitions
Étant donné un problème d’apprentissage par renforcement avec un environnement et un agent, nous allons utiliser les notations suivantes :
- Un épisode : Une partie de jeu. Chaque pas de temps d’un épisode est indexé par t: 𝑡∈[0,𝑇] (T représente le nombre de mouvement que l’agent a effectué durant la partie).
- Un état (state) : l’ensemble des états possibles s’écrit S = {s∈S} (position de l’agent, position de la récompense …)
- Une action : l’ensemble des actions possibles A={a∈A} (gauche, droite, haut, bas)
- La politique : la politique suivie par l’agent s’écrit 𝜋.
Q-learning
Pour rappel, l’objectif de l’agent est trouver les actions qui maximisent sa récompense future. Nous définissons la fonction de valeur Q mesurant la somme (actualisé) des récompenses futures en fonction de son état st et son action at.
Dans notre exemple, nous choisissons st comme la position de l’agent dans le monde (initialement : [5,1]), et les actions sont « droite », « gauche », « haut », « bas ».
Q-Table
Un Q-Table est une matrice contenant récompense future estimé Q en fonction de l’ensemble des états et des 4 actions possibles. Lorsque l’agent explore l’environnement, la table est mise à jour. L’action avec la plus grande valeur est considérée comme la meilleure action à effectuer.
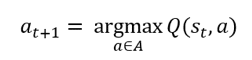
L’implémentation de notre agent s’écrira alors :
La nouvelle Q-Table pour l’action accomplie est donnée par la formule suivante :

L’étape 𝑡 d’un épisode va se composer alors selon les mécanismes suivants :
- L’agent observe l’état de l’environnement st (ex : position de l’agent).
- L’agent effectue une action at+1 en suivant une politique 𝜋 (ex : aller vers le bas). at+1= π(st, st-1… at, at-1)
- L’environnement réagit à cette action et génère une récompense rt pour l’agent : déplace l’agent et retourne la récompense associée à cette action [-1(hole), +1(food), 0(case blanche)].
- L’entraînement : actualisation de la Q-Table
L’entraînement de notre modèle donne :
En entraînant le modèle sur 100 épisodes (parties) on obtient :
Exemple 2 : ROOM MAP
Dans l’exemple introductif, nous étions dans un monde où la position initiale de l’agent ainsi que celle de la récompense étaient identiques à chaque épisode. Nous avons également supposer aucune réapparition de la récompense (food).
Dans le monde ROOMS MAP, nous allons faire abstraction de ses hypothèses. L’agent ainsi que la récompense auront une position initiale aléatoire. À chaque fois que l’agent atteint une récompense, il reçoit une récompense +1 et la food réapparaît sur une position aléatoire.
Dans le premier exemple, la position de l’agent suffisait à distinguer la situation de l’agent dans l’environnement. Dans notre nouveau monde, la position de l’agent ne suffit plus à distinguer la situation de l’agent puisque la position initiale de la food est choisie aléatoirement. Une façon de résoudre le problème est d’ajouter la position de la food dans nos états.
En choisissant comme états la position de l’agent ainsi que la position de la récompense, nous pouvons résoudre ce problème de la même manière :
Le Snake
Dans le monde précédent, l’agent ne s’agrandit pas quand il mange une récompense. Dans cette partie, nous allons faire abstraction de cette hypothèse, ce qui revient à jouer au jeu Snake.
Prendre toutes les positions du serpent (tête, parties du corps) comme états peut fonctionner, mais il est nécessaire d’entraîner le modèle très longtemps en raison du nombre élevé d’états. Étant donné que cette formation est destinée à donner une explication rapide et à afficher un résultat rapide à l’utilisateur, cette façon de sauvegarder les états n’était pas la meilleure approche.
Pour contourner cette limitation, nous pouvons baser nos états uniquement sur la position relative de la récompense (par rapport à la tête du serpent) et la position relative de la section de queue (par rapport à la tête du serpent).
De cette façon, les états S utilisés par l’agent pour prédire l’action suivante seront représentés comme suivant :
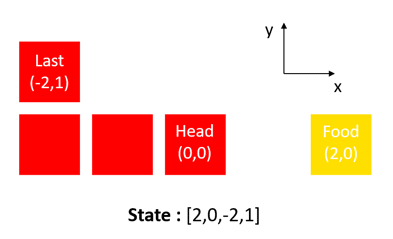
En choisissant ces états, nous pouvons résoudre le problème du Snake de la même manière que dans les deux premiers exemples.
En rajoutant des états de proximité (danger à gauche…), nous pouvons ajouter plusieurs agents dans le même monde :
Dans cet article, nous avons entrouvert les possibilités du Reinforcement Learning.
L’algorithme Q Learning donne très bon résultat quand le nombre d’états n’est pas trop élevé.
Ici, nous avons un peu aiguillé notre agent en choisissant une structure d’états qui semble être pertinente. Mais est-ce qu’elle l’est vraiment ? Est-ce qu’il ne nous manque pas des états ? Est-ce que nous n’avons pas biaisé notre agent ? C’est pourquoi, la plupart du temps, nous allons préférer donner à notre modèle une capture d’écran du jeu comme état.
Pour traiter un nombre d’états très important, nous pouvons allier Deep Learning et Q-learning en définissant un réseau de neurones retournant une estimation de la récompense future Q. Nous appelons cette algorithme le Deep Q-Learning.
Envie de démarrer une formation plus détaillée sur les différents aspects abordés de cet article ? Explorez tous nos modules !
N’hésitez pas à nous contacter pour plus d’informations, ou rejoignez nos réseaux sociaux pour être toujours informé des prochains lancements de bootcamps DataScience !








