Le Reinforcement Learning, ou apprentissage par renforcement en français, est, avec les apprentissages supervisé et non supervisé, l’une des trois grandes techniques d’apprentissage automatique.
Cette famille d’algorithme crée beaucoup d’engouement depuis quelques années, avec notamment les produits innovants de l’entreprise OpenAI tels que OpenAI Five, une IA qui a réussi à battre une équipe de joueurs professionnels sur le jeu vidéo Dota 2, ou le célèbre ChatGPT qui utilise cette technique pour ajuster ses paramètres.
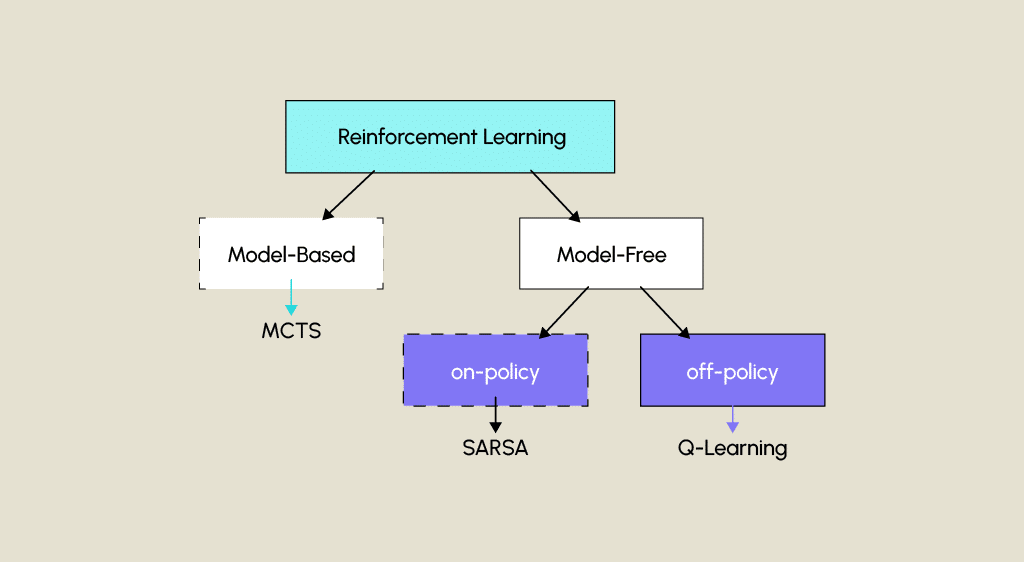
Qu’est-ce que le reinforcement learning ?
Qu’est-ce que l’algorithme SARSA ?
SARSA est un algorithme d’apprentissage dont le nom vient de l’anglais State-Action-Reward-State-Action, qui signifie État-Action-Récompense-État-Action et qui désigne la suite d’éléments qui constituent cet algorithme. Il s’agit d’un algorithme basé sur un tableau de valeurs d’action (ou Q-table, Q représentant la mesure de la qualité d’une action effectuée) qui attribue à chaque paire état-action une valeur représentant la récompense attendue.
Déroulement de l’algorithme
On peut illustrer les différentes étapes qui constituent cet algorithme en prenant pour exemple un livreur qui doit amener un colis d’un point A à un point B.
Tout d’abord la Q-table est initialisée avec des valeurs nulles. Les différentes étapes de SARSA peuvent ensuite commencer :
- L’algorithme est dans un état S (Le livreur connaît sa distance par rapport au point B)
- Vous choisissez une action A à effectuer, soit en exploitant vos connaissances soit en explorant des nouvelles possibilités (le livreur arrive à un croisement depuis le nord et connaît la route qui va vers le sud, il suit donc cette route)
- Vous recevez une récompense R (le livreur gagne 1 minute si son choix le rapproche du point B mais perd 5 minutes si il s’en éloigne). A ce moment la Q-table est mise à jour à l’aide de la formule Q[état_1, action_1] = (1-α) * Q[état_1, action_1] + α * (r + γ * Q[état_2, action_2]) avec
- Le taux d’apprentissage alpha ou α qui contrôle l’ampleur de la mise à jour. Si α = 0 on n’apprend rien, si α = 1 on apprend en oubliant ce qui a été appris précédemment.
- La récompense reçue r après avoir fait une action à un instant donné.
- Le facteur d’actualisation gamma ou γ qui pondère les récompenses futures.
- L’algorithme est dans un nouvel état S (le livreur connaît sa nouvelle distance par rapport au point B)
- Vous choisissez d’effectuer une nouvelle action A
Ces étapes se répètent jusqu’à ce que l’algorithme converge (jusqu’à ce que le livreur arrive au point B).
Cet algorithme est appelé « on-policy », ce qui signifie que la politique utilisée pour déterminer les actions est la même que celle qui met à jour les valeurs de la table Q. SARSA utilise généralement une politique ε-greedy, où ε est un paramètre qui détermine la probabilité d’exploration (sélection aléatoire d’actions) par rapport à l’exploitation (sélection de la meilleure action selon la Q-table). Cette caractéristique le différencie des algorithmes « off-policy » comme le Q-Learning.
Conclusion
En résumé, SARSA est un algorithme d’apprentissage par renforcement qui vise à apprendre à un agent les décisions à prendre dans un environnement grâce à une Q-table mise à jour itérativement. Il suit une politique d’exploration et d’exploitation tout en interagissant avec l’environnement, et il est utilisé dans divers domaines comme les jeux vidéo, la prise de décisions dans la robotique, ou la résolution de problèmes de planification de trajets.

Si vous souhaitez vous former à ce domaine, n’hésitez pas à consulter notre formation de Data Scientist.








