Dans un jeu de données, deux types de variables prédominent : les variables quantitatives, qui mesurent des quantités (une taille, un prix…), et les variables qualitatives ou catégorielles, qui déterminent plutôt des catégories ou des modalités (un sexe, une couleur…). Or comme le Machine Learning s’appuie sur diverses opérations mathématiques, il est crucial de convertir, ou plutôt d’encoder, nos variables catégorielles en valeurs numériques afin qu’elles puissent être traitées par nos modèles. Cet encodage intervient lors de la phase de prétraitement des données, aussi appelée "Preprocessing".
La librairie Python category encoders, comme son nom l’indique, offre alors une variété de techniques d’encodage pour nos variables. Comme toute librairie, elle s’installe avec la commande pip install category_encoders et s’importe avec import category_encoders as ce.
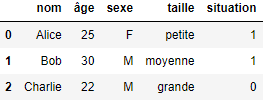
À travers cet article, voyons ensemble quelques-unes des nombreuses techniques d’encodage proposées par cette librairie. Nous considérons également, à titre d’exemple, le DataFrame suivant. Ce DataFrame contient cinq colonnes : trois variables catégorielles (nom, sexe, et taille), et deux quantitatives (âge et situation). La variable cible que nous souhaitons prédire est la situation professionnelle, inscrite dans la colonne éponyme : elle prend la valeur 1 si la personne étudiée est employée, 0 si elle est au chômage.
L’encodage One-Hot
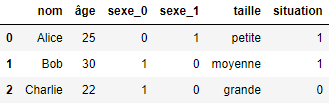
Commençons par la méthode d’encodage qui est sans doute la plus courante. Sur chaque colonne à encoder, l’encodage one-hot (ou one-hot encoding) la scinde en X colonnes, X étant le nombre de valeurs distinctes. Appliquons un one-hot encoding sur la colonne “sexe” de notre DataFrame :

Comme nous pouvons le remarquer, la colonne « sexe » s’est scindée en deux colonnes Femme et Homme. De même les valeurs contenues dans cette colonne sont maintenant binaires : 1 si le sexe de la colonne correspond à la personne étudiée, 0 sinon.

L’encodage binaire
L’encodage binaire fonctionne quasiment comme le one-hot : il scinde la colonne à encoder en X colonnes distinctes dont les valeurs sont binaires. La différence ici sera au niveau des valeurs : si l’encodage one-hot applique 0 ou 1 aux valeurs sans ordre particulier, l’encodage binaire lui comptera ces valeurs en base 2. Voyons cela avec le même DataFrame :
Si on obtient comme tout à l’heure deux colonnes distinctes au niveau du sexe, les valeurs, quant à elles, n’ont pas tout à fait le même sens. L’encodage binaire a en effet dénombré la valeur « F », qui apparaît en 1er, comme le chiffre 1 (01 en base 2), et la valeur « M » comme le chiffre 2 (10 en base 2).
En réalité, les encodages one-hot et binaire peuvent être considérés comme un sous-ensemble d’un autre type d’encodage pris en charge par category_encoders : l’encodage en base-N. Cet encodage permet de convertir nos variables catégorielles, sous forme de tableau, en leur équivalent en base-N. Ainsi, si l’encodage binaire correspond à un encodage base-2, le one-hot peut être considéré comme un encodage en base-1.
L’encodage ordinal
Il existe une sous-catégorisation au sein des variables catégorielles dont nous n’avons pas parlé jusqu’à présent. Généralement, les variables catégorielles sont dites « nominales », dans le sens où elles admettent un ensemble fini de valeurs qui n’admettent aucune relation entre elles. Dans notre DataFrame par exemple, les variables « nom » et « âge » sont nominales, car elles contiennent respectivement 3 et 2 valeurs sans lien entre elles.
Pourtant, lorsque ces variables catégorielles admettent une relation d’ordre entre leurs valeurs, elles sont alors considérées comme « ordinales ». Cela peut être une mention à un examen, un classement à une compétition, une tranche d’âge, etc. Dans notre exemple, la variable « taille » est une variable ordinale, puisqu’on peut y établir un classement entre ses valeurs : petite > moyenne > grande.
Ainsi pour traiter des variables ordinales, l’encodage ordinal sera plus adéquat, puisqu’il considèrera et maintiendra le classement établi lors de l’encodage des valeurs. Appliquons un encodage ordinal à notre DataFrame sur la colonne « taille » :

Comme nous pouvons le constater, en plus d’avoir converti numériquement les valeurs de la colonne, la hiérarchie de nos tailles a bien été maintenue !

L’encodage cible
Dans tout modèle de Machine Learning, il y a une variable cible que nous voulons prédire via ce modèle. Dans notre exemple, il s’agit de la situation professionnelle. Ainsi il peut être judicieux d’appliquer un encodage sur nos variables catégorielles qui, au lieu de leur définir une certaine valeur numérique, la calcule en fonction de la variable cible. C’est ici que s’applique l’encodage cible, ou « target encoder » !
L’encodage cible traduit les variables catégorielles en calculant la moyenne de la variable cible correspondante pour chaque catégorie distincte de la variable catégorielle que nous souhaitons encoder. Appliquons cet encodage sur les colonnes sexe et taille de notre DataFrame d’exemple, en spécifiant bien que notre variable cible est la colonne situation :

Ici, chaque valeur des colonnes sexe et taille prend bien une valeur numérique calculée comme la moyenne de la variable cible situation. Le calcul général pour chaque catégorie unique dans les colonnes catégorielles est effectué comme suit :

Ce calcul permet d’obtenir une représentation numérique de chaque catégorie catégorielle basée sur la moyenne de la variable cible associée à cette catégorie. Ces valeurs encodées peuvent ensuite être utilisées comme caractéristiques dans un modèle de Machine Learning.
Conclusion

Pour devenir un expert en encodage des données, n’hésitez pas à suivre les formations Data Scientist & Data Analyst proposées par DataScientest !








