Si vous vous intéressez aux algorithmes de Machine Learning, vous avez forcément déjà vu les mot « Boosting » ou « Boost » quelque part. On les retrouve dans un grand nombre de compétitions d’algorithme, et ils obtiennent souvent de très bons résultats. Mais qu’est-ce que c’est le Boosting au juste ?
Dans cet article, vous apprendrez à faire la différence entre un algorithme de Boosting et de Bagging. Puis vous comprendrez les rouages des algorithmes de Boosting AdaBoost, Gradient Boost et XGBoost.
Bagging, Boosting, qu’est-ce que c’est ?
Bagging
Pour définir ce qu’est le Boosting, le plus simple est de commencer par définir ce qu’est le Bagging.
Le Bagging est une technique en intelligence artificielle qui consiste à assembler un grand nombre d’algorithmes avec de faibles performances individuelles pour en créer un beaucoup plus efficace. Les algorithmes de faible performance sont appelés les « weak learners » et le résultat obtenu « strong learner ».
L’idée derrière cet algorithme est que plusieurs petits algorithmes peuvent être plus performants qu’un seul grand algorithme.
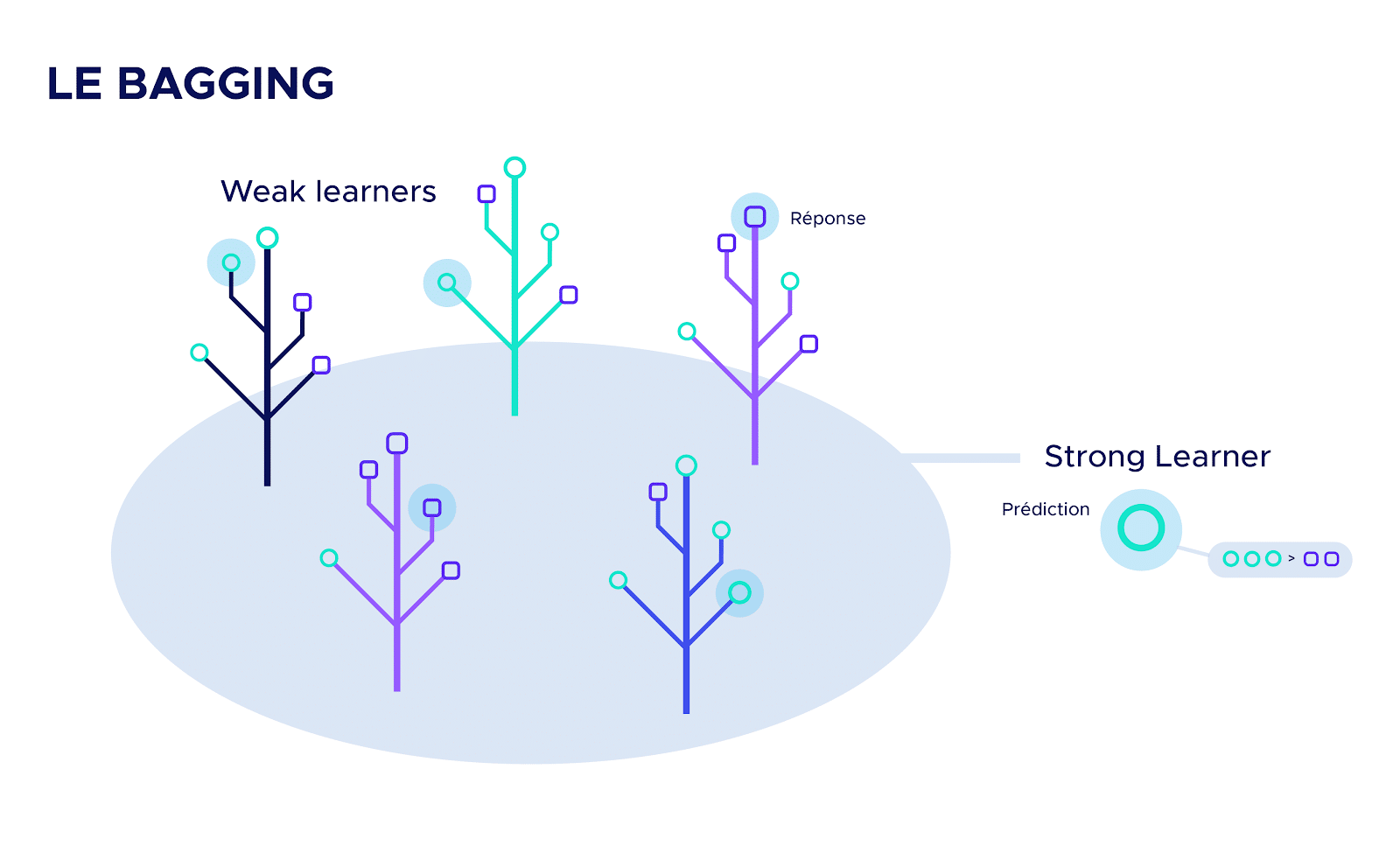
Pour simplifier, on peut se représenter mentalement ce procédé par une grande forêt de petits arbustes, d’espèces différentes. Grâce à la variété des arbres qui compose la forêt, elle résistera mieux aux intempéries qu’un grand chêne centenaire.
Les « weak leaners » peuvent être de différentes natures et avoir des performances variées, mais ils doivent être indépendants les uns des autres.
L’assemblage des « weak learners » (arbustes) en « strong learner » (forêt) se fait par votation. C’est-à-dire que chaque « weak learner » va émettre une réponse (un vote), et la prédiction du « strong learner » sera la moyenne de toutes les réponses émises.
Si le Bagging vous intéresse, vous pouvez découvrir cet article qui présente le fonctionnement de l’algorithme de Bagging le plus célèbre : le Random Forest.
Boosting
Les algorithmes de Boosting se basent sur le même principe que ceux de Bagging. La différence apparaît lors de la création des « weak learner ».
Pour le Boosting, les algorithmes ne sont plus indépendants. Au contraire, chaque « weak learner » est entraîné pour corriger les erreurs des « weak learner » précédents.
Ainsi, si l’on reprend l’image de la forêt, ici chaque arbuste a été soigneusement planté pour rendre la forêt plus résistante aux intempéries.
Dans cet article nous allons détailler le fonctionnement des algorithmes Adaboost, Gradient Boosting et XGBoost, qui sont probablement les algorithmes de Boosting les plus célèbres.
Adaboost
Adaboost a été utilisé pour la première fois par Yoav Freund et Robert Schapire, et a remporté le prix Gödel en 2003. Adaboost utilise des arbres décisionnels dont vous pouvez trouver le détail du fonctionnement dans cet article
Les « weak learners » d’AdaBoost sont généralement des arbres décisionnels à seulement 2 branches et 2 feuilles (aussi appelés souches) mais on peut utiliser d’autres types de classificateur.
Voici les étapes de construction du premier « weak learner » que l’on appellera w1 :
- On attribue le même poids à chaque ligne du dataset
- On entraîne w1 de manière à maximiser le nombre de bonnes réponses
- On donne une note à w1 en fonction de ses performances
L’idée derrière la notation est que nous souhaitons qu’un bon « weak learner » soit plus écouté qu’un mauvais « weak learner ».
La note va nous permettre de déterminer quelle importance donner à quel « weak learner » au moment du vote final.
De plus, nous souhaitons que les prochains « weak learner » puissent corriger les erreurs du précédent. Pour ce faire, nous allons augmenter le poids des lignes sur lesquelles w1 s’est trompé, et diminuer ceux pour lesquelles w1 a vu juste.
Voici donc les étapes de construction des autres « weak learner » :
- On modifie les poids attribués aux lignes en fonction des erreurs du dernier « weak learner »
- On entraîne un « weak learner » de manière à maximiser le nombre de bonnes réponses sur les lignes à poids élevé
- On donne une note à ce « weak learner » en fonction de ses performances
Contrairement à w1, les prochains « weak learner » prendront en compte les poids attribués au lignes. Plus une ligne a un poids élevé, plus il est important que le « weak learner » classe cette ligne correctement, et inversement.
Comme pour w1, nous donnerons une note à ces « weak learner » qui déterminera leur importance. Attention, la note dépend des résultats du « weak learner » en prenant en compte la pondération des lignes.
Après la création de chaque « weak learner », nous modifions le poids des lignes. Chaque « weak learner » corrige donc les erreurs faites par les précédents, et a une note qui reflète ses résultats.
Pour demander la prédiction d’Adaboost sur une observation, il faut interroger chaque « weak learner » et pondérer chaque réponse en fonction de la note qu’ils ont obtenu. La prédiction du « strong learner » sera la moyenne de toutes les réponses des « weak learner ».
Gradient Boosting
L’algorithme de Gradient Boosting a beaucoup de points communs avec Adaboost. Tout comme Adaboost, il s’agit d’un ensemble de « weak learners », créés les uns après les autres, formant un strong learner. De plus, chaque « weak learner » est entraîné pour corriger les erreurs des « weak learners » précédents. Néanmoins, contrairement à Adaboost, les « weak learners » ont tous autant de poids dans le système de votation, peu importe leur performance.
Nous allons désormais détailler rapidement le fonctionnement de l’algorithme :
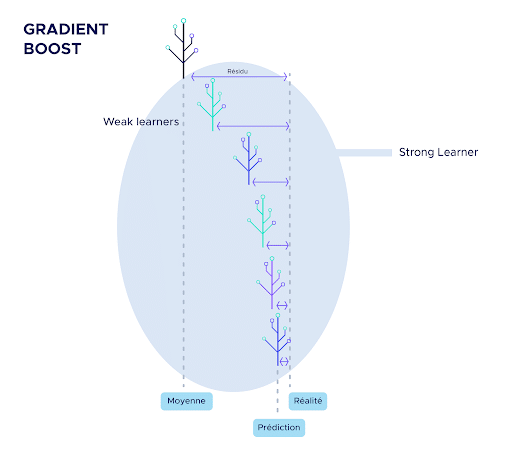
Le premier « weak learner » (w1) est très basique, il s’agit tout simplement de la moyenne des observations. Il est donc très peu efficace, mais il va servir de base au reste de l’algorithme.
Par la suite, nous calculons l’écart entre cette moyenne et la réalité que nous appelons premier résidu. De manière générale, on appellera ici résidu l’écart entre la prédiction de l’algorithme en cours de création et la réalité.
La particularité de Gradient Boosting est qu’il essaye de prédire à chaque étape non pas les données elles-mêmes mais les résidus.
Ainsi, le second « weak learner » est entraîné pour prédire le premier résidu.
Les prédictions du second weak learner sont ensuite multipliées par un facteur inférieur à 1.
L’idée derrière cette multiplication est que plusieurs petits pas sont plus précis que quelques grands pas. La multiplication réduit donc la taille des « pas » pour augmenter la précision. L’objectif étant « d’écarter » petit à petit les prédictions du modèle de la moyenne, pour les rapprocher de la réalité.
À partir de ce moment, la création des weak learners suit toujours le même pattern :
- À partir des dernières prédictions, on calcule les nouveaux résidus (écart entre la réalité et la prédiction)
- On entraîne le nouveau « weak learner » pour prédire ces résidus
- On multiplie les prédictions de ce « weak learner » par un facteur inférieur à 1
- On obtient de nouvelles prédictions, souvent légèrement meilleure que les précédentes
Pour demander la prédiction de Gradient Boosting sur une observation, il suffit d’interroger chaque « weak learner ». La prédiction du « strong learner » sera la somme de toutes les réponses des « weak learner ».
XGBoost
XGBoost est en fait une version particulière de l’algorithme de Gradient Boost. En effet, il s’agit d’un assemblage de « weak learners » qui prédisent les résidus, et corrigent les erreurs des “weak learners” précédents.
La particularité d’XGBoost réside dans le type de « weak learner » utilisé. Les « weak learners » sont des arbres décisionnels. Les arbres qui ne sont pas assez bons sont “élagués”, c’est à dire qu’on leur coupe des branches, jusqu’à ce qu’ils soient suffisamment performant. Sinon ils sont complètement supprimés. Cette méthode est appelé le « pruning » (élagage).
Ainsi, XGBoost s’assure de ne conserver que de bons weak learners.
De plus, XGBoost est informatiquement optimisé pour rendre les différents calculs nécessaires à l’application d’un Gradient Boosting rapides.
Enfin, XGBoost propose un panel d’hyperparamètres très important. Il est ainsi possible grâce à cette diversité de paramètres, d’avoir un contrôle total sur l’implémentation du Gradient Boosting.
Pour toutes ces raisons, XGBoost est souvent l’algorithme gagnant des compétitions Kaggle, il est rapide, précis et efficace, permettant une souplesse de manœuvre inédite sur le Gradient Boosting.
Les algorithmes présentés font certainement partie des plus utilisés, mais il en existe beaucoup d’autres. Dire qu’XGBoost est le meilleur algorithme de Machine Learning serait très réducteur. Il profite de beaucoup d’avantages, dont une facilité d’utilisation et une polyvalence déconcertantes. Néanmoins, à chaque problème correspond une solution différente. Ainsi, si vous souhaitez avoir une vue d’ensemble sur les différents types d’algorithmes de Machine Learning, consultez cet article sur les Random Forest.








