
Les origines de Apache Flink
Initialement développé à l’université technique de Berlin, ses premières versions ont été publiées en 2011 et avaient pour but de répondre à des problématiques complexes dans le traitement de données dans un environnement distribué en temps réel. Flink est devenu au fil des années une référence pour un grand nombre d’entreprises, jusqu’à devenir un des framework open-source les plus populaires. C’est en 2014 que Flink a été accepté en tant que projet Apache Incubator, puis en 2015 est devenu un projet Apache Top-Level. Depuis lors, Flink n’a eu de cesse de s’améliorer, fier d’une communauté de développeurs et d’utilisateurs très active.
Composition de l'écosystème Flink
L’écosystème de Apache Flink est composé de plusieurs couches et niveaux d’abstraction, comme illustré dans la figure suivante :
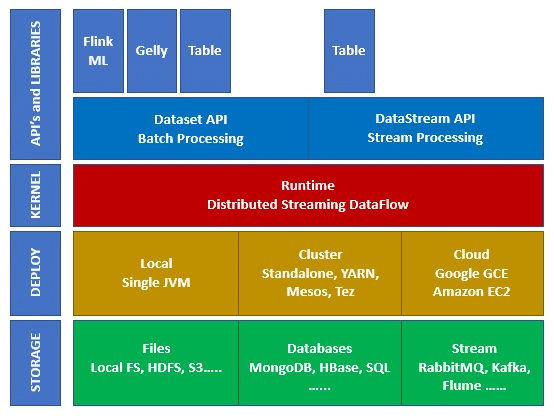
- Storage (stockage) : Flink dispose de plusieurs possibilités pour lire / écrire les données, telles que HDFS (Hadoop), S3, en local, Kafka, et bien d’autres
- Deploy (déploiement) : Flink peut se déployer en mode local, sur des clusters ou dans le cloud
- Kernel (noyau) : Il s’agit ici de la couche d’exécution, qui donne la tolérance aux pannes, les différents calculs distribués, etc.
- API’s & Libraries (API et bibliothèques) : Il s’agit de la couche de plus haut niveau de l’écosystème Flink. On y retrouve l’API Datastream, en charge du traitement des flux, l’API Dataset, en charge du traitement par lot (batch processing), et d’autres bibliothèques comme Flink ML (Machine Learning), Gelly (graph processing) et Table (pour le SQL).
Comment est structuré l'architecture de Flink ?
Flink est un moteur de traitement distribué pour des calculs avec état sur des flux de données bornés ou illimités. Il a été conçu pour fonctionner dans tous les environnements de cluster courants, et pour être en mesure d’effectuer des calculs à une vitesse très élevée, et à n’importe quelle échelle.
Tout type de données est produit sous forme de flux, qu’il s’agisse de relevés provenant de capteurs (IoT), de journaux d’événements (logs) ou même d’activités utilisateurs sur des sites web.
Comme nous venons de le voir, les flux traités peuvent être soit bornés, soit illimités, mais que cela signifie-t-il exactement ?
- Les flux illimités ont un début, mais pas de fin définie, ce qui signifie donc qu’ils fournissent les données telles qu’elles sont générées. Ils doivent être traités en continu, c’est-à-dire immédiatement après ingestion. De ce fait, il est impossible d’attendre que tout le flux soit arrivé pour le traiter, mais en revanche, il sera nécessaire de traiter ces flux dans l’ordre dans lequel ils arrivent.
- Le contrôle précis du temps et de l’état permet à Flink d’exécuter n’importe quel type d’application sur ces flux.
- Les flux limités, ou bornés, ont quant à eux un début et une fin définis. Contrairement aux flux illimités, ils peuvent être traités après avoir ingéré l’intégralité des données pour effectuer des calculs. Leurs traitements ordonnés ne sont par conséquent pas nécessaires. Les traitements de ces flux sont également appelés traitement par lots ou batch-processing.
- Ces flux sont traités en interne par des algorithmes et des calculs spécialement conçus pour les datasets de taille fixe.
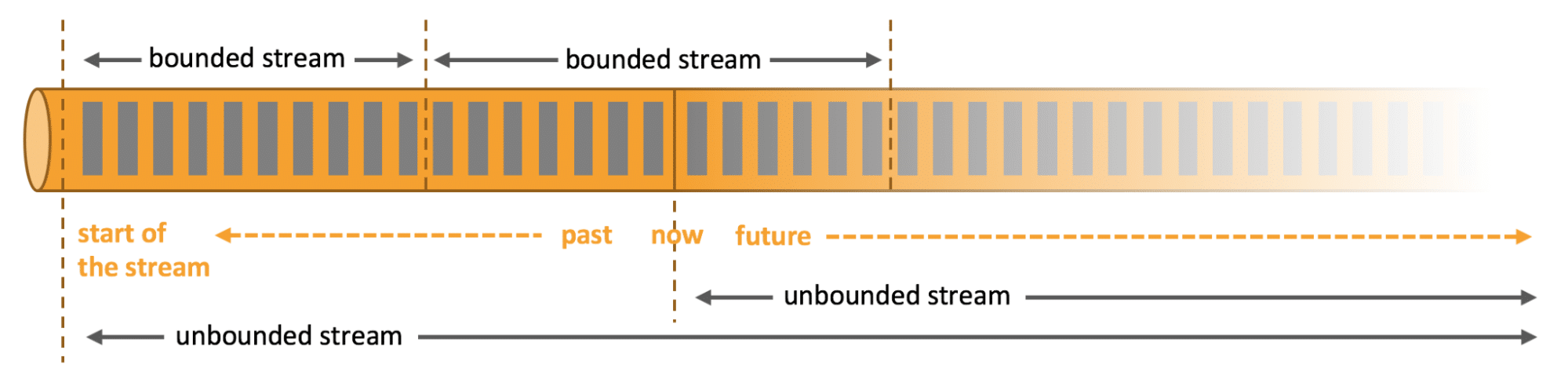
On comprend alors facilement que Flink propose d’excellente performance dans le traitement d’ensemble de données bornés ou illimités.
Quelles sont les applications liées à Flink grâce aux API’s ?
Apache Flink propose un ensemble d’API très riches permettant de faire des transformations à la fois sur des données par lot (batch) ou en temps-réel (streaming). Ces transformations sont effectuées sur les données distribuées et permettent aux développeurs de construire une application qui répondra à leur besoin. Voici les principales APIs proposées par Flink :
L’API Datastream :
Cette API est la principale interface de programmation pour la création de flux de données (stream processing).
Elle fournit une abstraction de haut niveau pour leur manipulation, et offre une prise en charge native pour la répartition (partitioning) des données pour le traitement en parallèle.
L’API Dataset :
Cette API est quant à elle une interface de programmation pour le traitement de données par lots (batch processing). Elle fournit également une prise en charge native pour le traitement en parallèle à grande échelle.
Elle est basée sur le modèle de MapReduce mais offrant des possibilités plus avancées, comme la gestion de l’état distribué, la gestion des erreurs et une optimisation automatique.
L’API Table :
Cette API est une interface de programmation pour le traitement de données relationnelles. Elle permet aux développeurs de créer des programmes de traitement de données basés sur des tables et des requêtes SQL, tout en profitant des avantages offerts par Flink.
Elle est compatible avec les autres APIs de Flink, permettant ainsi de combiner facilement les différentes interfaces pour répondre à des besoins de traitement de données spécifiques.
Les programmes créés avec ces API sont facilement évolutifs et résilients aux pannes grâce à l’architecture distribuée de Flink. Ils peuvent être exécutés sur des clusters de traitement à grande échelle, garantissant ainsi des performances élevées et une haute disponibilité.
À noter : Il existe également les API’s FlinkML pour le Machine Learning, Gelly pour les bases orientées graph ou encore CEP pour les traitements complexes (Complex Event Processing).
Fonctionnalités clés de Flink
Apache Flink dispose des notions clés énumérées ci-après :
- La parallélisation permet à Apache Flink de traiter les données en distribuant les tâches sur plusieurs nœuds de traitement (des « slots ») simultanément. Cela permet de réduire considérablement le temps de traitement des données en exploitant pleinement les ressources de l’environnement distribué. Les tâches peuvent être divisées en plusieurs sous-tâches qui sont ensuite exécutées en parallèle, augmentant ainsi l’efficacité de traitement.
- La répartition des données consiste à diviser les données en petits groupes, appelés « partitions », qui sont ensuite distribuées sur plusieurs nœuds de traitement. Les partitions peuvent être réparties en fonction de clés, valeurs, ou tout autre critère de répartition afin de permettre de les traiter plus efficacement, évitant par conséquent les goulots d’étranglement. Cette fonctionnalité est un aspect fondamental de la parallélisation dans Apache Flink.
- Apache Flink est conçu pour être tolérant aux pannes grâce à un système de checkpointing, ce qui signifie qu’il peut continuer à traiter les données, même en cas de défaillance d’un ou de plusieurs nœuds de traitement. Il peut détecter automatiquement les pannes et répliquer les données en conséquence.
Comparatif entre Flink et Spark Streaming
| Caractéristique | Apache Flink | Spark Streaming |
|---|---|---|
| Traitement temps réel | ✅ | ✅ |
| Traitement de flux | ✅ Traitement de flux infinis avec une latence très faible |
✅ Limité par la taille des lots et les temps de latence associés |
| Traitement de batchs | ✅ | ❌ |
| Modèle | ✅ Basé sur des transformations d'opérateurs |
✅ Basé sur des transformations RDD |
| Graphes | ✅ Via l'API Gelly |
❌ Pas de prise en charge |
| Langages | ✅ Python, Java et Scala |
✅ Python, Java et Scala |
| Tolérance de pannes | ✅ Gère les pannes de noeuds de traitement |
✅ Tolérant aux pannes, mais moins efficacement |
Quelles sont les limites de Flink ?
Comme nous venons de le voir, Flink est un outil très puissant pour le traitement de données. Il a cependant quelques limitations qui sont nécessaires de prendre en considération :
- Besoins en ressources : Il nécessite beaucoup de ressource pour s’exécuter efficacement, notamment pour le stockage de données et la puissance de traitement
- Complexe à mettre en œuvre : Il peut être difficile à mettre en œuvre pour les développeurs ayant peu d’expérience en traitement de données en temps réel. La courbe d’apprentissage peut s’avérer très élevée.
- Documentation : Sa documentation est complète, mais difficile à appréhender selon l’expérience du lecteur
- Ecosystème : Son développement à été rapide, mais Flink est relativement nouveau par rapport à d’autres outils du marché. Par conséquent, il peut manquer de maturité sur certains sujet, ou manquer de fonctionnalités
- Montées de version : Le code développé sur des versions antérieures ne sont pas forcément compatible après une mise à jour des API’s, ce qui peut s’avérer chronophage pour rendre à nouveau son code compatible
Conclusion
Pour conclure, Apache Flink est un framework de traitement de données extrêmement puissant et polyvalent. Il offre des fonctionnalités avancées pour le traitement de flux et de batch, et permet aux utilisateurs de réaliser des tâches de traitement de données en temps réel de manière efficace et évolutive.
Les API de programmation de Flink sont faciles à utiliser, offrant une grande flexibilité pour les développeurs, et sa capacité à gérer des charges de travail de grande envergure en fait un choix de premier ordre pour les entreprises et les organisations de toutes tailles.
Bien qu’il ait certaines limites, Flink continue d’évoluer rapidement pour répondre aux besoins changeants des entreprises.
Maintenant que vous savez tout sur Apache Flink, commencez une formation qui vous permette de maîtriser entièrement cet outil de traitement de flux. Découvrez DataScientest !








