
Spark Streaming est une solution innovante pour le traitement en temps réel des données. Il s’agit d’un composant du framework Apache Spark qui offre une performance, une scalabilité et une fiabilité exceptionnelles.
Ce système de traitement en temps réel distribué a été conçu pour répondre aux exigences les plus complexes en matière de traitement de données en temps réel. Il permet d’effectuer des analyses complexes et des tâches de transformations sur des données provenant de différentes sources (comme les réseaux sociaux, les périphériques connectés ou les capteurs)
Grâce à ses fonctionnalités avancées, telles que la gestion des flux de données très important, l’intégration de data sources variées et la prise en charge de la tolérance aux pannes, Spark Streaming s’est imposé comme un choix de référence pour les entreprises qui cherchent à traiter efficacement des données en temps réel.
Les domaines d’application d’une telle technologie sont très variés. Nous pouvons citer par exemple la détection de fraude, la surveillance de marchés financiers, ou encore de la recommandation personnalisée pour des achats en ligne, sans oublier bien entendu des analyses sur les réseaux sociaux.
Comment fonctionne le streaming de données ?
Le streaming de données est un processus en temps réel qui consiste à traiter des données qui sont générées en continu et à les analyser en temps réel.
Spark Streaming utilise une architecture dite « micro-batch », ce qui signifie que les données sont divisées en petits lots appelés « batchs » et sont traitées de manière séquentielle. Chaque batch est traité comme un RDD (Resilient Distributed Dataset) dans Spark, ce qui permet de bénéficier de la puissance de traitement en parallèle de Spark. Pour rappel, un RDD est l’unité de base de données dans Apache Spark, qui est une collection immuable de données partagées parallèlement sur plusieurs nœuds d’un cluster.
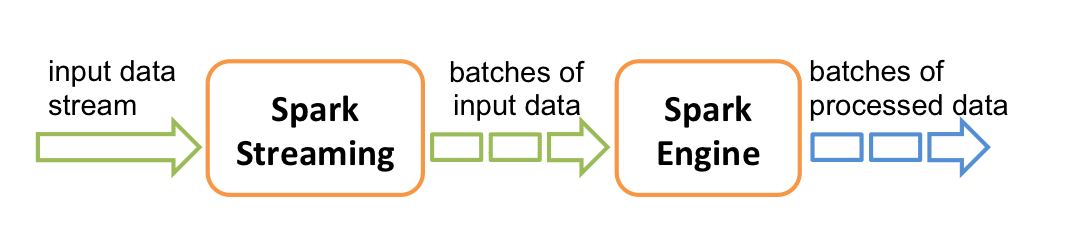
Qu'est ce que les DStreams ?
Spark Streaming fournit une abstraction de haut niveau appelée « flux discrétisé » (Discretized Stream), ou DStream, qui représentent un flux continu de données. Ils peuvent être considérés comme des RDD continus, où chaque RDD représente les données générées dans un intervalle défini.
Les DStream peuvent être créés à partir de flux d’entrée venant de sources telles que Kafka, Twitter ou Flume ou en appliquant des opérations de haut niveau sur d’autres DStreams et peuvent être utilisés pour effectuer diverses opérations comme le filtrage, l’agrégation, la jointure, etc., afin de produire les données résultantes en temps réel.

Prenons un exemple :
Imaginons que vous travaillez pour une entreprise de transport en commun qui souhaite surveiller en temps réel les passagers qui montent et qui descendent des bus. Pour cela, les bus sont équipés de capteurs qui envoient des informations en continu aux serveurs de la société.
Spark Streaming nous permettra d’utiliser un DStream pour traiter ces données en temps réel, où chaque DStream représentera les données envoyées par les capteurs des bus dans des intervalles de temps prédéfinis. Nous utiliserons des opérations sur ces DStreams pour effectuer nos analyses en temps réel. A l’aide d’agrégations, nous pourrons obtenir le nombre total de passagers dans les bus à chaque instant. Nous pourrons également utiliser des filtres afin d’identifier les bus qui ont atteint leur capacité maximale et ainsi envoyer des alertes pour la sécurité des passagers.
En somme, grâce à Spark Streaming nous pouvons effectuer des analyses en temps réel sur les données envoyées par les capteurs, et utiliser les résultats pour améliorer la sécurité et l’efficacité du système de transport en commun.
Qu'en est-il de la tolérance de pannes et réplication ?
Spark Streaming garantit la tolérance de panne grâce à des techniques de réplication de données et de reprise de tâches.
- La réplication de données consiste à dupliquer les données sur plusieurs nœuds afin de garantir leur disponibilité en cas de panne d’un nœud. Cette mesure assure également la robustesse du système en garantissant que les données ne seront pas perdues.
- La reprise de tâche, quant à elle, est un mécanisme qui permet de redémarrer les tâches sur d’autres nœuds en cas de panne, afin de garantir la continuité du traitement des données même en cas de problème.

Conclusion
Spark Streaming permet donc de répondre à des problématiques de Big Data en temps réel. Le fait qu’il supporte des sources de données variées, et qu’il permette de n’utiliser qu’un seul framework pour des besoins aussi variés n’en demeure pas moins un avantage non négligeable.









