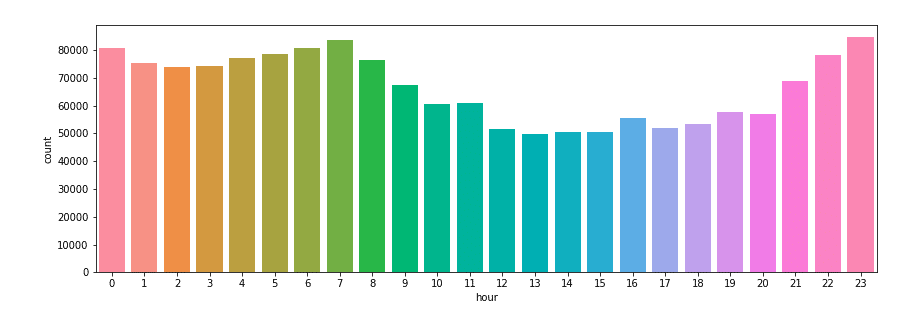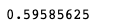Aujourd’hui, Twitter est utilisé par des centaines de millions de personnes dans le monde entier. Plus précisément, l'estimation actuelle s'élève à environ 330 millions d'utilisateurs actifs mensuels et 145 millions d'utilisateurs actifs quotidiens sur Twitter. Autre chiffre intéressant : 63 % des utilisateurs de Twitter dans le monde ont entre 35 et 65 ans.
L’objectif de cet article est de réaliser une analyse exploratoire et visuelle des tweets présents dans notre jeu de données. Dans un second temps, le but sera de parvenir à classifier à l’aide de différents modèles disponibles en Python, les sentiments des tweets selon qu’ils soient plutôt positifs, neutres ou négatifs. Autrement dit réunir sentiment analysis et NLP.
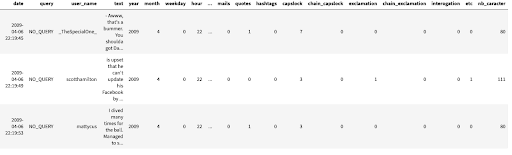
Tout d’abord, voici un premier aperçu du jeu de données que nous avons à disposition : télécharger le jeu de données, obtenu à l’aide de la commande df.head().
Comme nous pouvons l’apercevoir, ce jeu de données recensant au total 1.6 millions de tweets, contient une colonne intitulée label attribuant un 1 si le sentiment du tweet est positif et -1 dans le cas contraire.
Dans un premier temps, nous allons essayer de déterminer le mois dans lequel la twittosphère est la plus active.
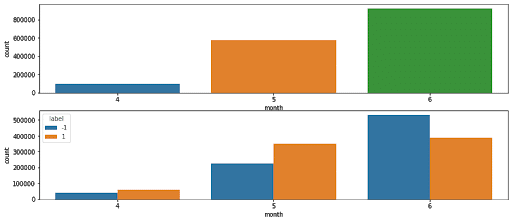
Une première tendance se dégage ici :
Les mois de mai (5) et juin (6) semblent être les mois où les tweets sont les plus nombreux. On pourrait expliquer cela par diverses raisons notamment le fait Twitter s’adresse particulièrement aux jeunes et que les mois de mai et juin constituent la fin de leur année scolaire ou universitaire, permettant ainsi à ces derniers de s’exprimer davantage sur Twitter.
On remarque également qu’en juin les sentiments des tweets sont plutôt négatifs (labélisés -1) confirmant ainsi l’idée pré-reçues que Twitter peut-être parfois un lieu de déferlement de violence.
Nous pourrions maintenant nous demander quel est le jour de la semaine où le nombre de tweet est le plus nombreux :
Nous remarquons ici sans surprise que les twittos utilisent beaucoup plus Twitter le week-end qu’en semaine.
On peut également s’intéresser à l’horaire de la journée où il y a le plus de tweets et constater également sans étonnement que c’est surtout avant et après le début et la fin de la journée de travail/école que le nombre de tweets explose :
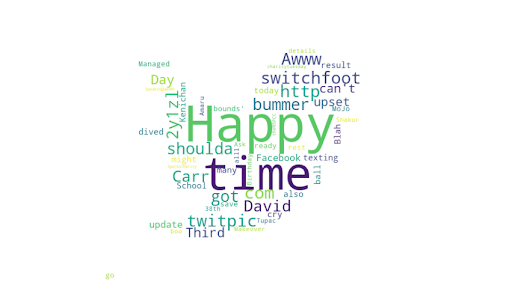
Voici un nuage de mots dans lequel on peut apercevoir quels sont les mots les plus utilisés dans les tweets de ses utilisateurs(plus la taille de la police d’un mot est grande, plus le nombre d’occurrences de celui-ci est important)
Désormais, nous allons commencer notre travail de classification de sentiments des tweets à l’aide d’une régression logistique.
Pour ce faire, l’idée est comme d’habitude de diviser notre jeu de données en un échantillon d’entraînement (80%) dans lequel nous allons apprendre les paramètres du modèle et un échantillon test (20%) dans lequel nous allons les tester.
Néanmoins, les variables explicatives étant des données textuelles (les tweets), nous allons au préalable créer de nouvelles variables explicatives numériques en lien avec les tweets (des métadonnées) afin de pouvoir ensuite prédire les labels.
CRÉATION DES MÉTADONNÉES ET CLASSIFICATION
Pour analyser le sentiment d’un tweet, nous pouvons alors extraire ce qui nous semble être important comme par exemple :
Le nombre de lien « http(s) » ou « www. ».
Le nombre d’adresse mail. (le nombre d’adresse mail cité dans le tweet pourrait avoir une importance concernant le sérieux du tweet.)
Le nombre d’hashtag.
Le nombre de citation d’utilisateur.
Le nombre de lettre en majuscule
Le nombre de chaine lettre en majuscule.
Le nombre de point d’exclamation.
Le nombre de chaîne de point d’exclamation.
Le nombre de point d’interrogation.
Le nombre de chaîne de point d’interrogation.
Le nombre de point ect (…).
Voici un nouvel aperçu de notre jeu de données après création des métadonnées :
En regroupant et sommant chaque colonne de ce nouveau jeu de données en fonction du label
Nous remarquons que si le tweet est composé de liens ou d’adresse mail, il aura tendance à être beaucoup plus positif.
Les variables explicatives étant désormais prêtes à être utilisé, nous n’avons plus qu’à faire tourner notre modèle de régression logistique afin de classifier les sentiments positifs ou négatifs des tweets.
Voici le score de prédiction obtenu par le modèle :
On obtient ainsi un score de prédiction d’environ 60% qui n’est pas extraordinaire. Pour améliorer ce score, on pourrait utiliser une représentation bag of words de chaque mot présent dans les tweets qui permet tout simplement dereprésenter le texte sous forme d’un vecteurtraitable par un algorithme de machine learning
SOLUTION ALTERNATIVE : AFINN
Une autre solution pour classifier le sentiment d’un tweet est d’utiliser des librairies disponibles sur Python comme Afinn.
Le lexique AFINN est une liste de termes anglais dont la version actuelle contient plus de 3 300 mots, chacun étant associé à un score de sentiment que nous pouvons obtenir à l’aide de la méthode score de la classe Afinn.
Le score Afinn est une variable catégorielle dont voici la règle d’interprétation :
Sentiment négatif : score afinn < 0
Sentiment neutre : score afinn == 0
Sentiment positif : score afinn > 0
Appliquons désormais la fonction Afinn à notre jeu de données :
Regardons maintenant si Afinn est efficace :
Comme on peut le voir, Afinn est particulièrement performant et a permis de déterminer de manière catégorique le caractère négatif des 2 tweets ci-dessus.
CONCLUSION :
À travers cet article, nous avons pu encore une fois nous rendre compte de la puissance du NLP qui a permis de classifier de manières fiable le sentiment des tweets.
Cette analyse de sentiments Twitter pourrait avoir plusieurs domaines d’application dont voici quelques exemples spécifiques :
La surveillance des médias sociaux : Détecter les tweets à sentiments négatifs pourrait permettre de réduire le harcèlement et le déferlement de violence se produisant sur Twitter
Campagnes politiques :L’analyse des sentiments sur Twitter pourrait permettre d’analyser la popularité d’un candidat politique et de prédire ainsi le vainqueur d’une élection présidentielle par exemple
Fidéliser la clientèle d’une entreprise : L’analyse des sentiments sur Twitter permet de suivre ce qui se dit à propos d’un produit ou service vendu par une entreprise et peut ainsi aider à détecter les clients en colère.
Cet article vous a plu ? Inscrivez-vous à notre Newsletter pour recevoir nos articles en avant-première !