
Lorsque nous faisons face à des datasets de grandes dimensions avec énormément d’observations et à des modèles de Machine Learning complexes avec beaucoup d’hyperparamètres, l’étape d’entraînement peut prendre plusieurs heures. Dans ce cas, une relation inverse entre le nombre de données et la performance du modèle se met en place. Alors pour réduire ce temps perdu à attendre l’exécution des algorithmes et éviter cette diminution de performance, cuML semble être la solution !
Qu'est ce que cuML ?
cuML est une API OpenSource d’algorithmes. Elle fait partie de la suite de packages RAPIDS, dont la caractéristique principale est d’utiliser des GPU (Graphical Processing Unit) pour toutes les structures d’algorithmes, et pas seulement celles de réseaux de neurones comme habituellement. Plus précisément, cuML utilise un GPU accéléré pouvant multiplier les performances d’un CPU (Central Processing Unit) classique par 4 pour des algorithmes de Machine Learning simples et par 1000 pour des algorithmes plus complexes.
Grâce à cela, c’est une réelle alternative à Scikit-Learn. En effet Scikit-Learn est une bibliothèque Python certes complète et très utilisée en Data Science, mais peu efficace en termes de rapidité pour des Big Data.
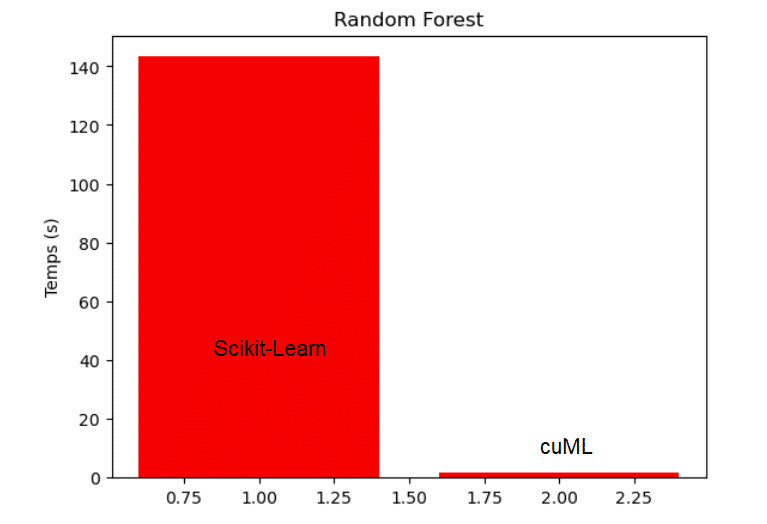
Prenons un exemple pour comparer le temps d’exécution des deux librairies. Nous avons multiplié par 8000 le dataset Titanic disponible sur Kaggle afin d’obtenir un dataset de plus de sept million d’observations. Nous souhaitons faire de la classification binaire pour prédire si un passager du Titanic survit ou non. Avec Scikit-Learn, le temps d’entraînement d’un modèle Random Forest sur le dataframe agrandi est de 143 secondes. Avec cuML, le temps d’entraînement d’un modèle Random Forest sur ce même dataframe est de de seulement 1.6 seconde. Cela prouve à quel point cuML permet de travailler beaucoup plus efficacement et rapidement sur un projet de Data Science !
Mais comment utiliser cuML ?
- Installation : cuML fait partie de la suite d’API RAPIDS. Il faut ainsi l’installer en passant par le RAPIDS Release Selector, accessible via ce lien, et en cochant cuML et les options compatibles avec la machine utilisée.
- Utilisation : L’API de cuML est très proche de celle de Scikit-Learn, ce qui la rend facile d’utilisation. En effet, elle contient des outils statistiques, des Scaler de preprocessing et des méthodes de Tuning d’hyperparamètres définis de la même façon. Pour la modélisation, il suffit d’emporter le modèle choisi depuis la librairie cuML, de lui passer les hyperparamètres en argument, puis d’utiliser la méthode .fit() pour l’entraîner.
Poursuivons avec le problème du Titanic. Pour entraîner le modèle Random Forest avec 200 arbres, nous utilisons le code suivant :
Ce code ressemble bien à celui que nous aurions écrit en utilisant Scikit-Learn :
Quelles sont les performances de prédictions ?
cuML est donc simple d’utilisation pour les connaisseurs de Scikit-Learn et surpasse même cette librairie d’un point de vue de rapidité.
En termes de performances, elle semble tout aussi efficace. Que ce soit en régression, en classification ou en clustering, il a été prouvé que les modèles de cuML obtiennent généralement d’aussi bons résultats de prédictions que ceux de Scikit-Learn. Il est même possible de tester un ensemble d’hyperparamètres pour obtenir un modèle optimal, de faire de la feature selection et d’interpréter les modèles.
Ainsi cuML semble être la solution idéale pour traiter des grosses bases de données ou des données qui continuent d’évoluer. À la différence de Scikit-Learn, peu compétitif en termes de temps, et de Spark, basé sur un CPU classique, cuML utilise les fonctionnalités d’un GPU accéléré. Cela lui permet ainsi d’optimiser des modèles complexes en un temps réduit !
Maintenant que vous savez tout sur cuML, vous souhaitez peut-être le mettre en pratique dans vos projets data. Pour ce faire, DataScientest vous invite à découvrir ses formations data.









