Deep Learning fasziniert ebenso sehr, wie es einschüchtern kann. Zwischen mathematischen Formeln, Grafikkarten und technischem Vokabular wirkt es oft wie ein Thema für Spezialisten. Dabei ist das Grundprinzip einfach: Maschinen lernen aus Beispielen.
Und genau hier setzt der TensorFlow Playground an. Mit diesem interaktiven, kostenlosen Online-Tool kannst Du neuronale Netze im Browser live ausprobieren, Einstellungen verändern und dabei beobachten, wie das Netzwerk „lernt“. In wenigen Minuten wird aus einem abstrakten Konzept ein anschauliches Aha-Erlebnis.
Deep Learning - kurz erklärt
Deep Learning ist heute das Rückgrat vieler KI-Anwendungen – von Bilderkennung über maschinelle Übersetzung bis hin zur Textgenerierung. Doch die Grundidee ist älter, als viele denken: Schon in den 1950er-Jahren begannen Forschende damit, die Funktionsweise biologischer Neuronen rechnerisch nachzubilden. Ein künstliches Neuron verarbeitet Zahlenwerte (Inputs), gewichtet sie, fügt gegebenenfalls einen Bias hinzu und schickt das Ergebnis durch eine sogenannte Aktivierungsfunktion. Werden viele dieser Neuronen in mehreren Schichten hintereinandergeschaltet, entsteht ein neuronales Netzwerk, das Daten Schritt für Schritt transformiert – von Rohdaten bis hin zu nützlichen Merkmalen für Klassifikation, Vorhersage oder Generierung.
Und warum spricht man von „tiefem“ Lernen? Weil moderne Netzwerke oft aus Dutzenden oder sogar Hunderten solcher Schichten bestehen. Jede verarbeitet Informationen auf einer höheren Abstraktionsebene: von Kanten zu Formen, von Formen zu Objekten und schließlich zu ganzen Szenen. Gelernt wird das alles mithilfe von Optimierungsverfahren wie dem Gradientenabstieg, der die Gewichte im Netzwerk so anpasst, dass der Fehler auf einem Trainingsdatensatz minimiert wird.
TensorFlow Playground: Deep Learning spielerisch verstehen
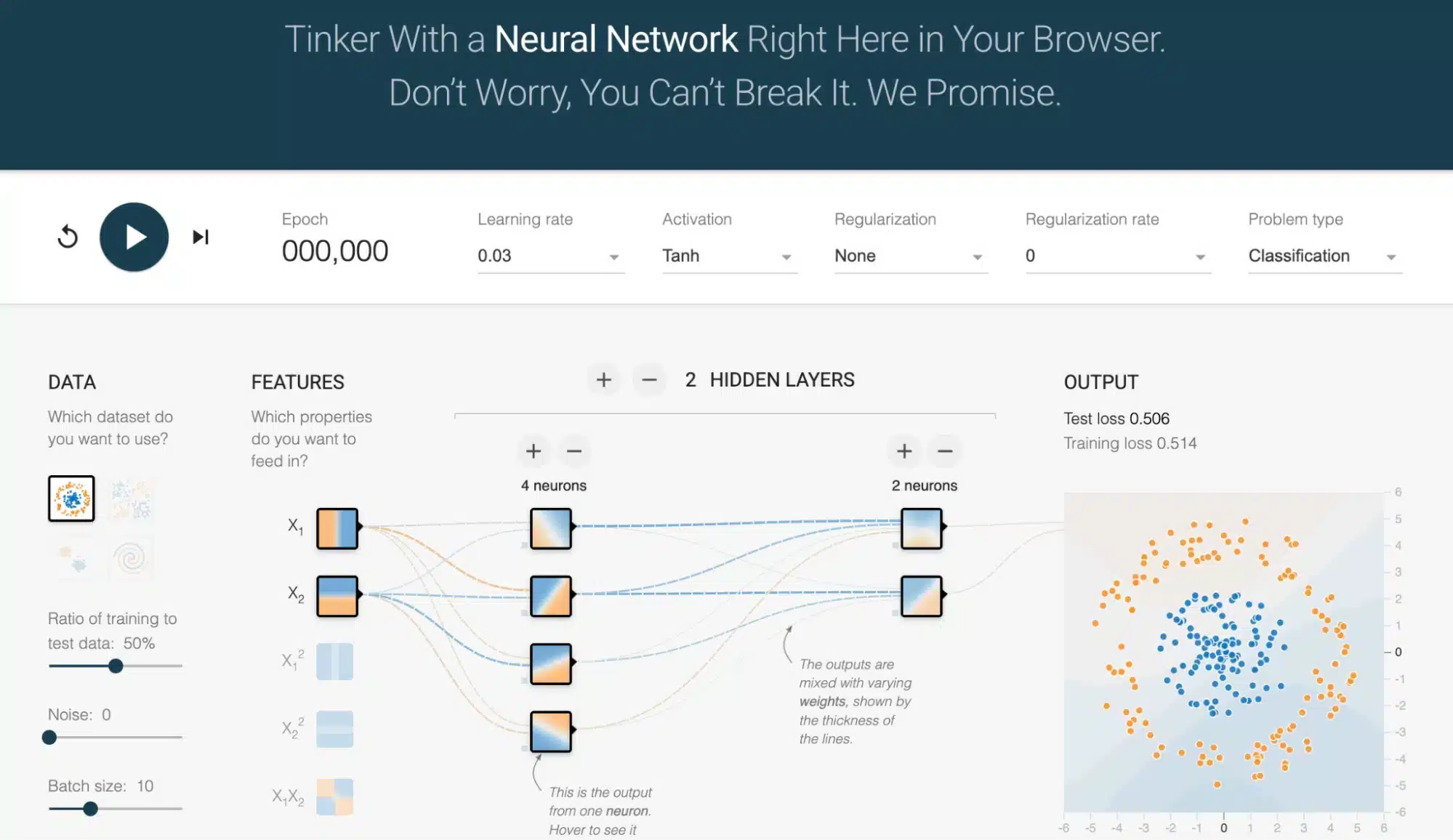
Ein Browser, ein Klick – und schon bist Du mitten im Geschehen: TensorFlow Playground ist ein interaktives Tool, das Deep Learning visuell erlebbar macht, ganz ohne Installation oder Code.
Was Du siehst, ist ein minimales neuronales Netzwerk:
Links: farbige Punkte, die die Trainingsdaten darstellen.
In der Mitte: Kreise (Neuronen), verbunden durch Pfeile (Gewichte).
Rechts: Einstellbare Hyperparameter wie Lernrate, Aktivierungsfunktion, Regularisierung oder Batch-Größe – alles per Mausklick anpassbar.
Sobald Du auf „Train“ klickst, startet das Training – und Du beobachtest live, wie sich die Entscheidungsgrenze bei jedem Schritt verändert.
Warum ist dieses Tool so hilfreich?
Sofortige Visualisierung: Du siehst direkt, wie das Netzwerk lernt. Der Prozess des Gradientenabstiegs wird greifbar – ganz ohne abstrakte Gleichungen.
Sicheres Experimentieren: Kein Risiko, eine GPU zu überlasten oder Dateien zu beschädigen – alles läuft im Browser.
Einfaches Teilen: Die Konfiguration wird in der URL gespeichert. Kopieren, teilen, fertig – ideal für Lehre, Teams oder Selbstlernende.
Ein Blick ins Netzwerk: So funktioniert der TensorFlow Playground
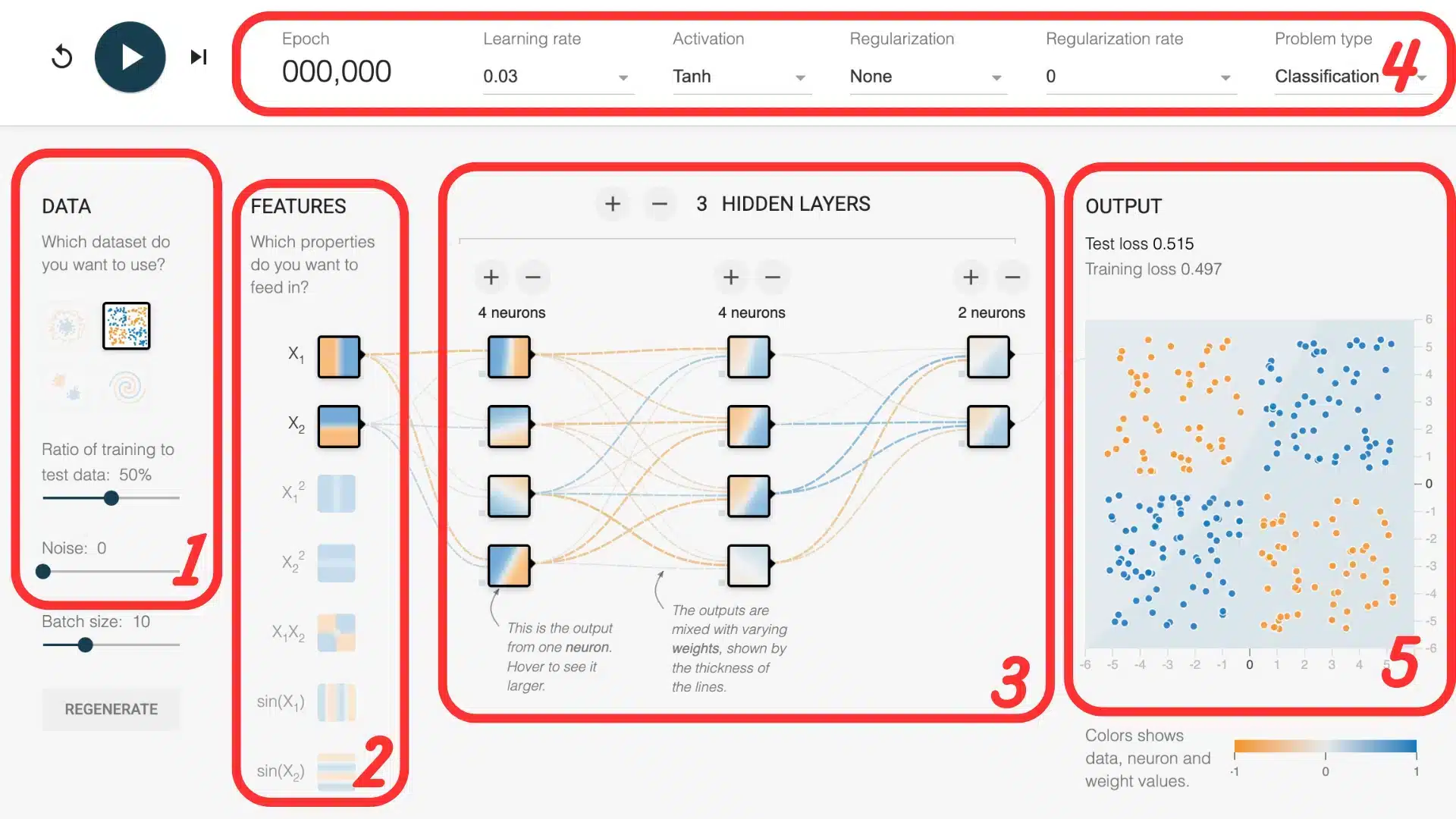
1. Die Datensätze
Der Playground stellt vier synthetische 2D-Datensätze bereit:
eine linear trennbare Punktwolke,
zwei nichtlineare Varianten (Kreis und „Monde“)
und die berühmte Spirale („Schnecke“).
Sie sind einfach genug für die Darstellung, aber komplex genug, um die Fähigkeiten eines neuronalen Netzwerks herauszufordern.
2. Die Eingabemerkmale (Features)
Standardmäßig dienen die x– und y-Koordinaten als Input. Zusätzlich kannst Du abgeleitete Merkmale aktivieren – z. B. x², y², x·y, sin(x) oder sin(y).
Diese Features erlauben es dem Netzwerk, nichtlineare Muster leichter zu erkennen. Beispiel: Die Kreisform lässt sich mit x² + y² wesentlich einfacher klassifizieren – selbst mit einem einfachen Netzwerk.
3. Die Architektur des Netzwerks
Unterhalb der Daten befindet sich ein Schieberegler, mit dem sich die Anzahl an Hidden Layers und die Anzahl an Neuronen pro Schicht festlegen lässt.
So kannst Du testen, welchen Einfluss ein flaches oder tiefes Netzwerk auf die Lernleistung hat. Du beobachtest direkt, wie zusätzliche Schichten die Modellkapazität verändern – von zu schwach bis hin zur Überanpassung.
4. Die Hyperparameter
Lernrate: Gibt an, wie stark die Gewichte bei jedem Schritt angepasst werden. Ist sie zu groß, oszilliert der Fehler; ist sie zu klein, lernt das Netzwerk kaum.
Aktivierungsfunktionen: tanh, sigmoid oder ReLU – jede hat ihre Eigenheiten. ReLU führt oft zu schnellerer Konvergenz, während tanh stabiler lernt.
L2-Regularisierung: Fügt eine Strafe für große Gewichte hinzu, was Overfitting vorbeugt.
5. Die Ergebnisse darstellen
Sobald Du auf „Train“ klickst, zeigen zwei Elemente den Lernfortschritt:
Die Entscheidungsgrenze im Diagramm: Sie verändert sich live und visualisiert, wie das Modell die Daten trennt.
Die Verlustkurve unten rechts: Ein sinkender Wert zeigt, dass das Modell dazulernt und der Fehler abnimmt.
Zwei Übungen zum Ausprobieren
Alle Parameter der folgenden Übungen sind bereits in den Links kodiert. Du musst nur klicken, um direkt in die beschriebene Konfiguration einzusteigen.
Übung 1: Erste Schritte
Link: Erste Schritte
Starte das Training: Schon nach wenigen Sekunden beginnt sich die Entscheidungsgrenze zu formen und trennt die Punkte in zwei klar erkennbare Zonen.
Verändere anschließend die Lernrate – Du wirst sehen, wie sich das Lerntempo verlangsamt. Probiere außerdem verschiedene Aktivierungsfunktionen aus, zum Beispiel einen Wechsel von tanh zu ReLU. Geschwindigkeit und Verlauf der Konvergenz verändern sich spürbar, obwohl die Aufgabe einfach bleibt.
Diese erste Übung ist ideal, um ein Gefühl für die Auswirkungen der Parameter zu bekommen – ohne in komplexe Architekturen einzutauchen.
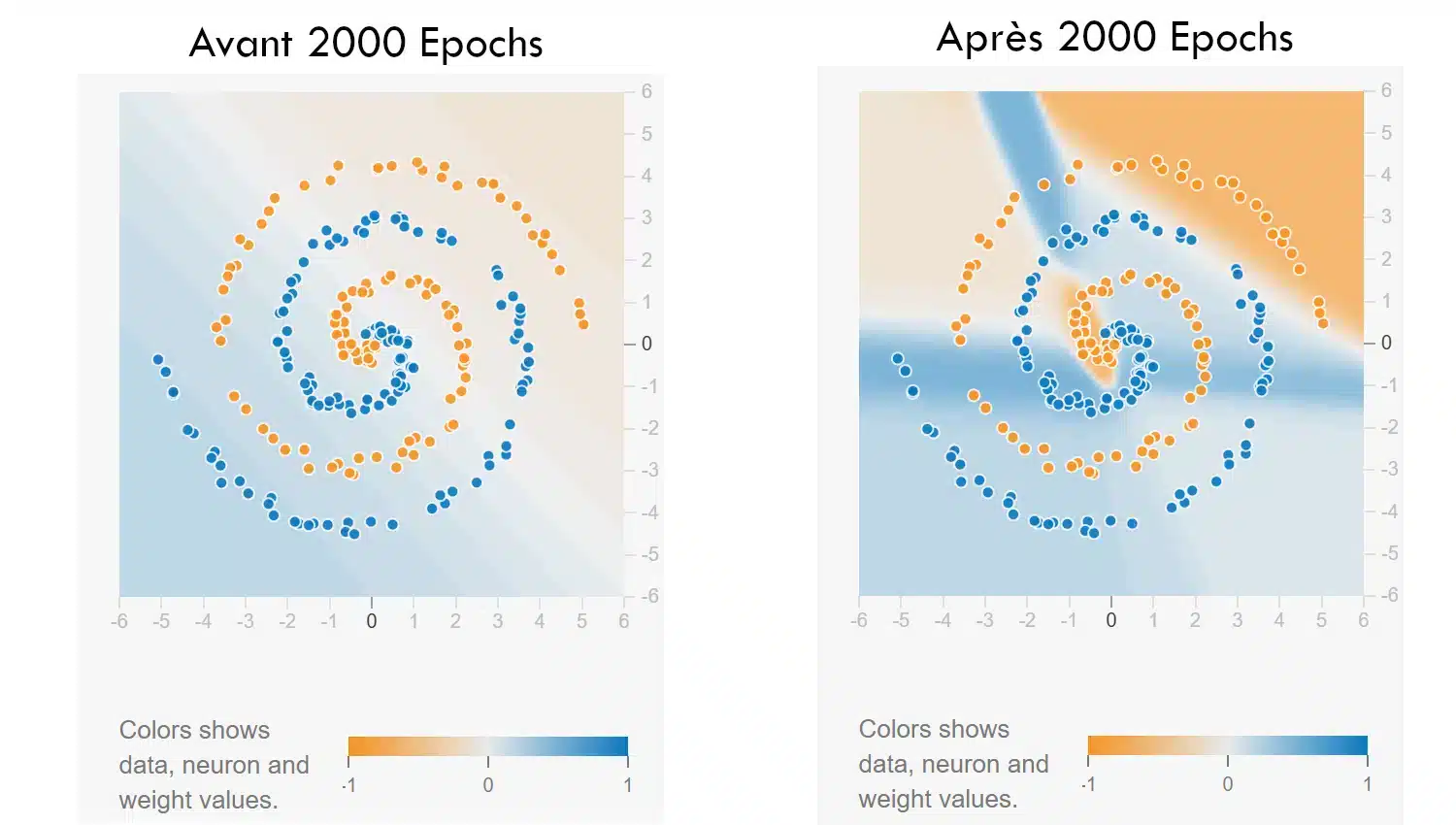
Übung 2: Spirale
Link: Spirale
In dieser zweiten Herausforderung geht es um einen besonders schwierigen Datensatz: eine Spirale, deren verschlungene Form neuronale Netzwerke schnell an ihre Grenzen bringt.
Die Startkonfiguration ist bewusst einfach gehalten – nur x und y als Eingaben – was Dich zwingt, mit Architektur und Hyperparametern zu experimentieren, um das Problem zu lösen.
Starte das Training: Anfangs ist die Entscheidungsgrenze chaotisch. Jetzt bist Du gefragt: Finde eine Kombination aus Schichten, Neuronen, Aktivierungsfunktion und – falls nötig – Regularisierung, mit der das Netzwerk dem Muster folgen kann.
Bonus-Schwierigkeitsgrad: Du darfst keine abgeleiteten Features aktivieren. Die Lösung muss allein durch die Netzwerkstruktur erreicht werden.
Fazit: Was man vom Playground mitnimmt
Schon wenige Minuten im TensorFlow Playground reichen aus, um drei zentrale Prinzipien des Deep Learning zu verinnerlichen:
Lernen durch Fehlerkorrektur: Ein neuronales Netzwerk lernt, indem es seine Gewichte schrittweise so anpasst, dass der Fehler auf den Trainingsdaten kleiner wird. Der sogenannte Gradientenabstieg ist im Grunde ein automatisierter Prozess aus Versuch und Irrtum.
Nichtlinearität ist unverzichtbar: Ob über Aktivierungsfunktionen oder zusätzliche Merkmale – ohne Nichtlinearität kann das Netzwerk nur gerade Grenzen ziehen. Komplexe Muster erfordern mehr Flexibilität.
Hyperparameter entscheiden über Erfolg oder Misserfolg: Eine zu hohe Lernrate, eine unausgewogene Architektur oder falsche Regularisierung können das Training zum Scheitern bringen – ganz ohne Programmierfehler.
All das ist im Playground nicht bloß Theorie – Du siehst es. Die visuelle Rückmeldung macht deutlich, was Formeln oft nur abstrakt vermitteln.
Der TensorFlow Playground ist kein Werkzeug für industrielle Modelle – sondern ein Fenster ins Herz des Deep Learning. Er zeigt, wie Daten Schritt für Schritt durch das Netzwerk transformiert werden, und macht so die abstrakten Konzepte greifbar. Mit ein paar Klicks, farbigen Punkten und Schiebereglern wird das Unsichtbare sichtbar – und der Sprung zu Keras oder PyTorch nur noch eine Frage der Oberfläche.
Also: Seite öffnen, ein paar Parameter ändern, auf „Train“ klicken – und zusehen, wie die Theorie lebendig wird. Das maschinelle Lernen, so komplex es auch sein mag, beginnt mit diesem ersten Klick auf „Train“.








