Stilübertragung mit CycleGAN
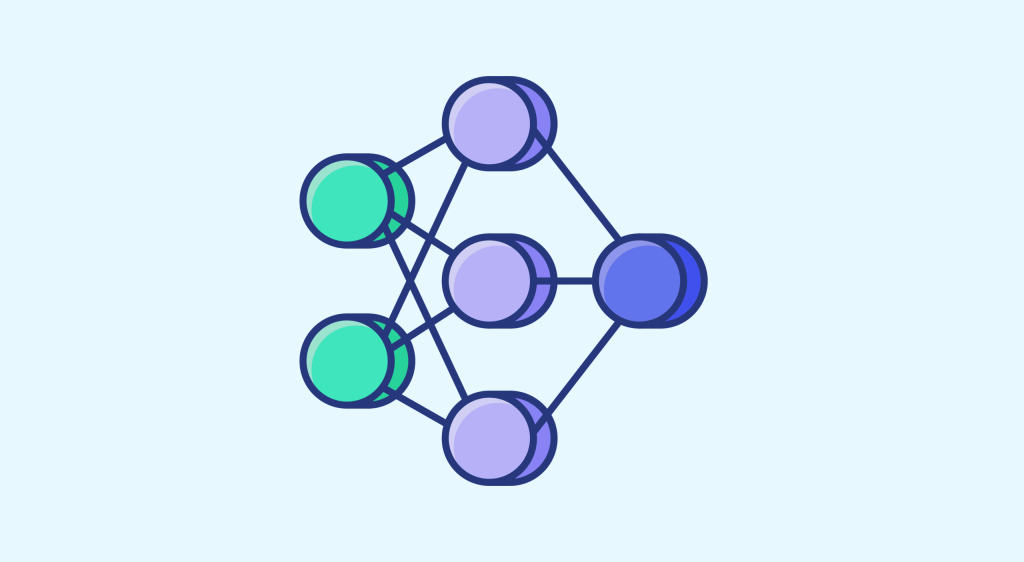
Der Neural Style Transfer (NST) ist eine Sammlung von Modellen und Methoden, die es ermöglichen, den visuellen Stil von Bildern oder Videos auf ein anderes Bild zu übertragen. In diesem Artikel beschäftigen wir uns mit einem bestimmten Modell, das CycleGAN heißt. Heutzutage sind die erfolgreichsten Algorithmen im Bereich NST angepasste Deep-Learning-Algorithmen, die Faltungsschichten verwenden. In […]
Streamlit: Das Tool, um deine Machine-Learning-Projekte zu präsentieren

Streamlit: Ein wichtiger Schritt bei der Verarbeitung von Daten in Machine Learning ist ihre grafische Darstellung, um sie zu visualisieren und ihr Verhalten besser zu verstehen. Daher müssen Personen, die einen Beruf wie Data Scientist ausüben, regelmäßig Daten interpretieren und für andere Teams in ihrer Firma visualisieren. Erstellen von Web-Apps mit Streamlit Im Gegensatz zu […]
AttGAN: Ein Tool zur Veränderung von Gesichtsattributen

Die Bearbeitung von Gesichtsattributen, auch Facial Attribute Editing genannt, bezeichnet alle Methoden, die zum Ziel haben, ein oder mehrere Attribute eines bestimmten Gesichts zu verändern. Vor dem Aufkommen von Deep Learning war dies eine mühsame Aufgabe, da sie Pixel für Pixel von Hand durchgeführt wurde. Seit kurzem gibt es jedoch neue Algorithmen, die es ermöglichen, […]
CatBoost: Das Must-Have im Machine Learning

Seit 2017 ergänzt CatBoost die bestehende Palette an Tools für maschinelles Lernen. CatBoost ist schnell, effizient und präzise und gehört zu den führenden Technologien im Bereich des Gradient Boosting. In diesem Artikel erklären wir dir alles, was du über diese Technologie wissen musst: Anwendungen, Vorteile, Funktionsweise. Was ist CatBoost ? CatBoost ist ein Open-Source-Algorithmus, der […]
train_test_split: Tutorial zur Verwendung dieser Funktion

Ein Machine-Learning-Modell ist in der Lage, selbstständig aus einem Datensatz zu lernen, mit dem Ziel, Verhalten in einem anderen Datensatz vorherzusagen. Dazu findet es zugrunde liegende Beziehungen zwischen unabhängigen erklärenden Variablen und einer Zielvariablen im ursprünglichen Datensatz. Dann verwendet er diese Muster, um neue Daten vorherzusagen oder zu klassifizieren. Wie wird die Funktion train_test_split definiert? […]
Jupyter Notebook: Ein unverzichtbares Tool für den Code-Austausch

Jupyter Notebook ist eine Webanwendung, mit der du Computercode austauschen kannst. Hier erfährst du alles, was du über dieses Tool wissen musst, das bei Entwicklern sehr beliebt ist, aber auch in der Data Science nicht fehlen darf. Jedes Programmierprojekt muss an einem bestimmten Punkt seines Fortschritts geteilt werden. Es ist möglich, den Quellcode zu teilen, […]
Die Brownsche Bewegung: Prinzip und praktische Anwendungen
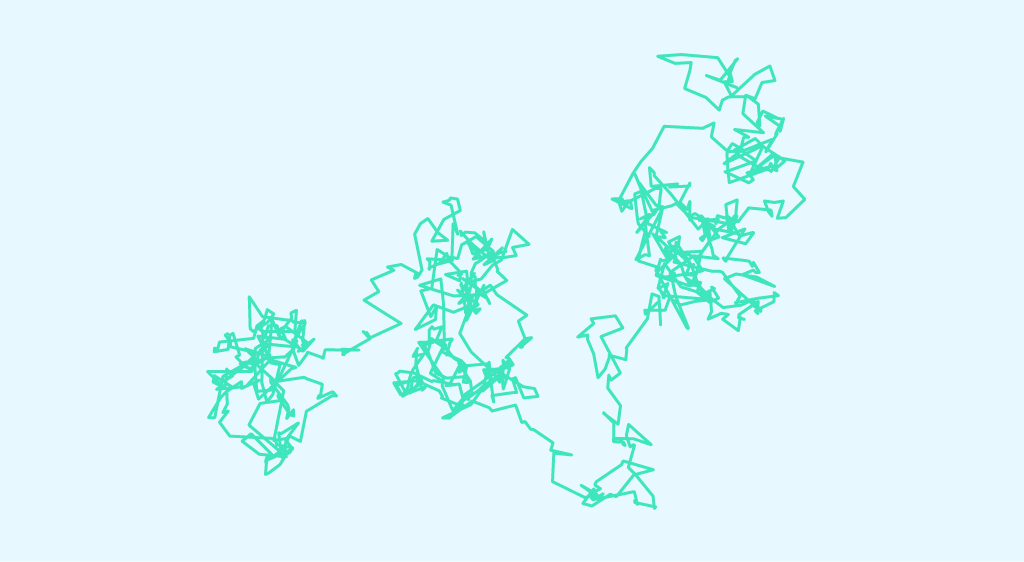
Nehmen wir ein mikrometergroßes Teilchen, das in einer Flüssigkeit schwimmt. Dieses Teilchen bewegt sich zufällig, weil andere kleine Teilchen auf dieses „große“ Teilchen stoßen. Dies ist das Prinzip der Brownschen Bewegung, auch Wiener-Prozess genannt. Historisch gesehen entdeckte der Botaniker Robert Brown die Brownsche Bewegung im Jahr 1827. Er beobachtete die chaotische Bewegung von Pollenkörnern in […]
Beautiful Soup: Einführung in Web Scraping mit Python

Als User im Internet hat man Zugang zu vielen Informationen, die sich auf Kunden, Angebote, Aktienkurse, physikalische Phänomene usw. beziehen. Diese Daten können von Nutzern gelesen werden, aber man würde sie gerne auswerten, indem man sie in ein brauchbares Format umwandelt, um sie dann zu analysieren und daraus Nutzen zu ziehen. Web Scraping ist die […]
Verteilte Architektur: Definition, ihre Beziehung zu Big Data
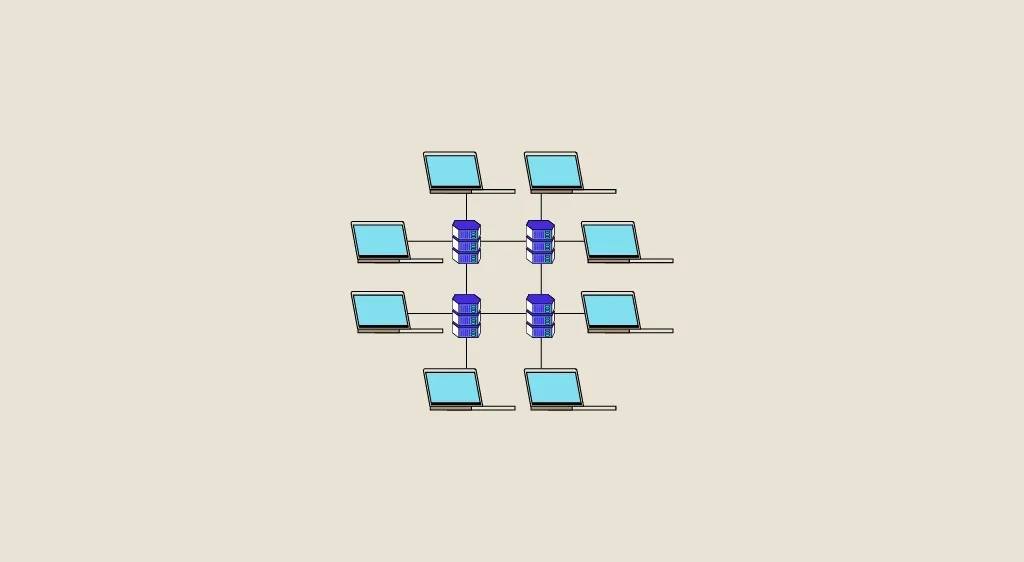
Verteilte Architekturen sind Informationssysteme, die verfügbare Ressourcen verteilen und nutzen, die sich nicht am gleichen Ort oder auf dem gleichen Rechner befinden. In diesem Artikel erklären wir ausführlich, was diese Architekturen sind, welche Vorteile sie gegenüber anderen Architekturen haben und wie sie in der Praxis in der Data Science eingesetzt werden. Was ist eine verteilte […]
Zeitreihe Python: Verarbeitung und Modellierung
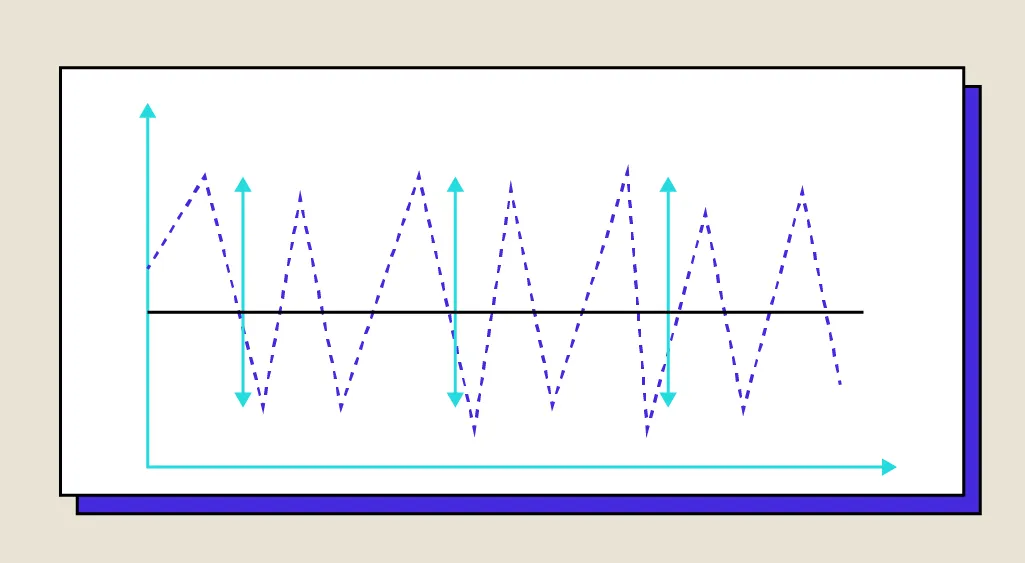
Eine Zeitreihe ist eine Datentabelle, die die Entwicklung einer Variablen im Laufe der Zeit wiedergibt. In Python wird die Zeitreihe oft in Form einer Pandas-Reihe verarbeitet, die durch ein DateTime indiziert ist. Dieses Format ist sehr einfach zu verarbeiten und zu visualisieren. Zeitreihen werden in vielen Bereichen wie z. B. der Astronomie und der Meteorologie […]
Bokeh: Die Python-Bibliothek für Visualisierung der nächsten Generation

Die Datenanalyse bietet viele Möglichkeiten. Allerdings kann es für nicht-technische Benutzer in einem Unternehmen schwierig sein, die Rohdaten zu interpretieren. Indem sie relevante Informationen klar und explizit darstellt, behebt die Data Visualization dieses Problem und ermöglicht es jedem, Big Data zu nutzen.. Wenn du bereits mit Data-Visualization-Bibliotheken wie Matplotlib und/oder Seaborn vertraut bist, werden wir […]
ELIF Python: Was du bei dieser Funktion beachten solltest

ELIF Python: Das Testen von bedingten Ausdrücken ist die Grundlage der Programmierung. Während die Struktur if then else (wenn dann sonst) den meisten Sprachen innewohnt, manipuliert Python eine andere Form der Bedingung: if elif else… Was genau ist das? Wenn du gelernt hast, ein Computerprogramm zu schreiben, und zwar unabhängig von deinem Niveau, wirst du […]
