Data Science
Data Pipeline: Was du noch nicht wusstest
Eine Data Pipeline ist eine Reihe von Prozessen und Werkzeugen, die verwendet werden, um Rohdaten aus verschiedenen Quellen zu sammeln, sie zu analysieren und die
Eine Data Pipeline ist eine Reihe von Prozessen und Werkzeugen, die verwendet werden, um Rohdaten aus verschiedenen Quellen zu sammeln, sie zu analysieren und die

Open Data bezeichnet alle Daten, die von öffentlichen Verwaltungen und Unternehmen veröffentlicht und gesammelt werden. Diese Daten sind in der Regel kostenlos oder zu sehr

Wenn man über das Linux Betriebssystem spricht, bedeutet das in der Regel, dass man die Entwicklung des Betriebssystems erlernen muss, und das kann Angst machen.
OLAP-Würfel: Multidimensionale Analyse ist die Fähigkeit, Daten zu analysieren, die in mehreren Dimensionen zusammengefasst wurden. In diesem Artikel lernst du das Stern- und das Schneeflockenmuster
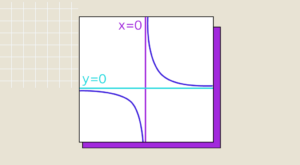
Alle wissenschaftlichen Disziplinen basieren auf Mathematik, und die Datenwissenschaft ist da keine Ausnahme. Wenn es sich bei den zu lösenden Problemen um Optimierungsprobleme handelt, ist
Fremdschlüssel SQL: Wer ein SQL-Datenbankverwaltungssystem entwirft, tut gut daran, das Fremdschlüsselsystem zu kennen und zu implementieren. Langfristig wird er davon profitieren. Ein Fremdschlüssel ist eine
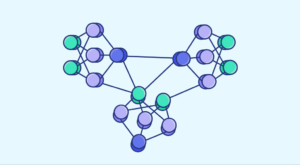
Bei der Gestaltung eines tiefen neuronalen Netzes können verschiedene Arten von Architekturen der ersten Ebene verwendet werden. Eine davon ist das dichte neuronale Netzwerk. Worum

Die Qualität der Leistung des maschinellen Lernens hängt in hohem Maße von den verfügbaren Informationen ab. Deshalb müssen Data Scientists die verwendeten Datensätze genau untersuchen.
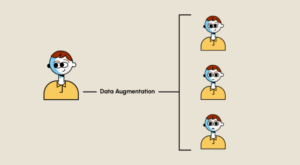
Die Genauigkeit und Effektivität von Deep Learning hängt stark von der Qualität und Quantität der Lerndaten ab. Und obwohl wir uns voll und ganz im

Data Governance Tools sind unerlässlich, um eine Data Governance-Strategie in einer Organisation umzusetzen. Finde heraus, welche Tools die besten sind! Im Zeitalter der digitalen Transformation

Kontext – Pilzerkennung Pilzerkennung: Eine der am weitesten verbreiteten und ältesten Artenbestimmungsmethoden ist die „morphologische Bestimmung“, bei der die Individuen anhand ihrer anatomischen Merkmale identifiziert
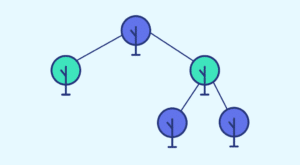
Heute beschäftigen wir uns mit dem Isolation Forest, einem Machine-Learning-Algorithmus zur Lösung von binären Klassifikationsproblemen wie Betrugserkennung oder Krankheitsdiagnose. Diese Technik, die 2008 auf der
