
Predictive Modeling: Wie wird das Wetter morgen sein? Kann man den Börsenkurs vorhersagen? Kann man "erraten", ob ein Patient an einer Krankheit leiden wird oder nicht? Wie kann man das Verhalten von Kunden besser verstehen, um ihnen ein passendes Angebot zu machen? Das sind Fragen, auf die Datenwissenschaftler und Statistiker engagiert nach Antworten suchen, indem sie Methoden der vorausschauenden Modellierung oder Predictive Modelling anwenden.
Es lag schon immer in der Natur des Menschen, vorausschauend zu denken und sich mit den ihm zur Verfügung stehenden Mitteln so gut wie möglich an die aktuellen Bedingungen anzupassen. Die Evolution basiert auf der Fähigkeit von Lebewesen, sich anzupassen und sich daher implizit gut auf aktuelle Situationen vorzubereiten, um sich günstige Bedingungen zu sichern.
Manchmal werden diese Vorhersageoperationen viel zu komplex, als dass sie vom menschlichen Gehirn durchgeführt werden könnten. Daher ist es wichtig, diese Konzepte zu formalisieren und die Aufgabe einem Algorithmus zuzuweisen.
Außerdem neigt unser Gehirn zu kognitiven oder psychologischen Verzerrungen, die uns zu irrationalen Entscheidungen führen können, und diese Fehler sind weniger präsent, wenn man einen Algorithmus verwendet.
Heute haben wir Werkzeuge, die es uns ermöglichen, die Phänomene, die wir beobachten, zu modellieren (in eine abstrakte, mathematische Sprache zu übersetzen). Die Modellierung von Vorhersagen ermöglicht es, Antworten zu finden, die mit den uns zur Verfügung stehenden Daten in Zusammenhang stehen.
Wie macht man prädiktive Modellierung?
Die von Algorithmen verwendeten mathematischen und statistischen Methoden beruhen oft auf Techniken, die recht abstrakte Begriffe verwenden.
Wenn man „predictive modeling“ betreiben will, ist es hilfreich, den eingesetzten Algorithmus als eine Funktion zu sehen, die Daten als Input nimmt und Informationen als Output zurückgibt.
Es ist auch sehr wichtig, die Bedeutung der Parameter des Algorithmus zu verstehen, um sie unter Berücksichtigung der Besonderheiten der Daten und der zu erfüllenden Aufgaben anpassen zu können.
Die Qualität der Daten hat einen großen Einfluss auf die erzielten Ergebnisse. Bevor du mit irgendeiner Analyse beginnst, solltest du daran denken, eine explorative Datenanalyse durchzuführen und mit fehlenden Daten, Ausreißern, Duplikaten usw. umzugehen.
Es ist zu beachten, dass jedes Unternehmen seine eigenen Protokolle hat, und wenn man eine Antwort auf eine Frage sucht, wird die Arbeit sehr oft im Team mit Spezialisten auf dem Gebiet durchgeführt, was den Wissenschaftlern ermöglicht, die Herausforderungen zu verstehen und die am besten geeigneten Techniken anzuwenden.
Predictive Modeling - Konkret bedeutet das also..?
Wie bereits beschrieben, wird die prädiktive Modellierung verwendet, um das Verhalten einer Metrik (Messgröße) aus den beobachteten Daten vorherzusagen.
Zunächst muss man damit beginnen, sich die richtigen Fragen zu stellen und bereit sein, sie im Laufe der Zeit zu ändern, denn es gibt kein fertiges Rezept. Nachdem du eine Problemstellung aus einem Dataset definiert hast, wählst du je nach dessen Spezifität einen geeigneten Ansatz, der es dir ermöglicht, zu Antworten oder Elementen einer Antwort zu gelangen. Um zu sehen, wie das in der Praxis funktioniert, schauen wir uns zwei Beispiele an.
Beispiel 1: Sozial- und Gesundheitsdaten
Explorative Analyse
Das folgende Beispiel stammt von Kaggle, einer Webplattform, die Wettbewerbe im Bereich Data Science veranstaltet.
Um es einfach zu machen, nehmen wir eine Probe aus einem Dataset mit Daten über Personen, die einige Indikatoren über ihren sozialen Hintergrund und einige medizinische Informationen enthalten. Wir sehen hier 5 Personen (auf den Linien). Jede Person hat 12 Merkmale (in den Spalten), die sie charakterisieren.

Die Person mit der ID 29172 ist z. B. eine 68-jährige Frau, die verheiratet war und in einer ländlichen Gegend lebt, nie geraucht hat und weder Bluthochdruck noch Herzprobleme hatte. Wir haben auch ihren durchschnittlichen Blutzuckerspiegel und ihren BMI ermittelt.
Was uns am meisten interessiert, ist die letzte Spalte, „stroke“, aus der hervorgeht, ob die Person in der Vergangenheit einen Schlaganfall erlitten hat oder nicht.
Bevor wir uns an die Klassifizierung machen, ist es sinnvoll, eine explorative Analyse durchzuführen und zu sehen, wie sich die Personen mit der Krankheit auf die Daten verteilen.
Um eine Frage aus dem Geschäftsleben oder der klinischen Forschung beantworten zu können, möchte man wissen, welches Profil am ehesten diese Krankheit entwickeln wird, oder vorhersagen, ob eine neue Person mit hoher Wahrscheinlichkeit diese Krankheit entwickeln wird.
Um festzustellen, welche Merkmale die Krankheit am meisten beeinflussen, kann man eine grafische Darstellung mit den Prozentsätzen der erkrankten Personen nach ihrem Profil machen.
Hier zeigt sich, dass Personen, die rauchen und früher geraucht haben, eine höhere Neigung zu Schlaganfällen haben als Personen, die nie geraucht haben.
Bei Personen mit Bluthochdruck ist die Wahrscheinlichkeit, einen Schlaganfall zu erleiden, höher.
Für diese Analyse ist es also interessant, Profile herauszuarbeiten, die ein Risiko darstellen, und somit seine Ansprache anzupassen, um optimale Entscheidungen treffen zu können.
Klassifizierung
Nachdem du eine explorative Studie durchgeführt hast, kannst du einen Klassifikationsansatz verfolgen. Die Klassifizierung, wie der Name schon sagt, dient dazu, Klassen (Gruppen) unter den Individuen zu bilden.
Wir möchten nun neue Daten erheben und vorhersagen, ob z. B. eine Person mit einem bestimmten Profil die Voraussetzungen für einen Schlaganfall erfüllt. In diesem Fall würden wir also einen Klassifizierungsansatz verfolgen, d. h. wir würden der Person ein Label zuweisen: 0, wenn die Person gesund ist, oder 1, wenn die Person krank ist.
Je nach Problemstellung und Daten hat man verschiedene Methoden oder Modelle. Zu den Klassifikationsalgorithmen gehören KNN, K-means, Random Forest, logistische Regression usw. Maschinelles Lernen (engl. Machine Learning) ermöglicht es dem Computer, aus den Daten zu lernen.
Um eine Vorstellung davon zu bekommen, wie sehr man dem Modell vertrauen kann, durchläuft man eine „Testphase“, in der man den Algorithmus mit einem Teil der Daten testet. Es ist wichtig, dass der Testfehler klein ist, um dem Modell vertrauen zu können. Das Testen mehrerer Algorithmen dient dazu, die Fehler zu vergleichen und die richtige Wahl zu treffen.
Zusammenfassend lässt sich sagen, dass ein Klassifikationsalgorithmus, wie im einleitenden Teil erläutert, als eine Funktion visualisiert werden kann, die in unserem Beispiel Individuen als Argumente nimmt und jedem Individuum einen Wert von 1 (krank) oder 0 (gesund) zuweist.
Beispiel 2: Anzahl der Passagiere
Ein weiteres beliebtes Beispiel für die prädiktive Analyse sind Zeitreihen. Sie ermöglichen es, die Entwicklung einer Größe im Laufe der Zeit darzustellen. Diese Art von Daten findet man in den Charts der Börsenkurse. Bei der Vorhersage von Zeitreihen wird nach einem geeigneten Modell gesucht, um zukünftige Werte auf der Grundlage früher beobachteter Werte vorherzusagen.
Die Struktur des Datasets ist unterschiedlich. Bei der Zeitreihenanalyse hat man eine zeitliche Dimension, d. h. die Daten sind chronologisch geordnet.
Da es sich nur um zwei Variablen handelt, hier das Datum und die Anzahl der Passagiere an einem bestimmten Tag, kann man eine Visualisierung in der Ebene :
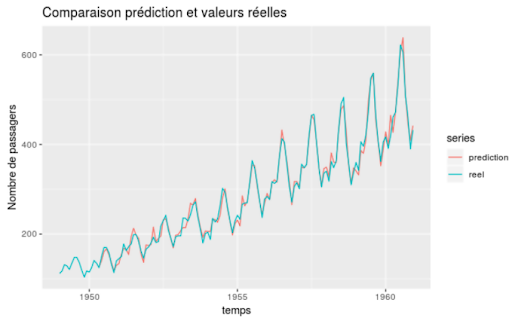
In Türkis sehen wir die tatsächlichen Daten und in Rot haben wir die vom Modell vorgeschlagenen Schätzungen.
Die Tatsache, dass die Daten nach der Zeit geordnet sind, führt zu einer Korrelation zwischen benachbarten Variablen. Die Untersuchung von Zeitreihen beruht auf einer Zerlegung in verschiedene Elemente (Trend, Saisonalität und Rauschen).
Fazit
Zusammenfassend lässt sich sagen, dass die Vorhersagemodellierung Antworten auf eine bestimmte Fragestellung liefert und Methoden vorschlägt, die es ermöglichen, zukünftiges Verhalten zu antizipieren. Es gibt viele verschiedene Möglichkeiten, Vorhersagen zu treffen, und es ist wichtig, den Kontext zu verstehen und die Fragen zu definieren, um ein Modell vorzuschlagen, das dem Kontext angepasst ist.
Bei einer Vorhersageanalyse ist es daher unerlässlich, Kenntnisse in Statistik zu haben, um eine geeignete Studie durchführen und die Ergebnisse richtig interpretieren zu können.
Wenn du dich in Statistik weiterbilden und deine technischen Fähigkeiten im Zusammenhang mit diesen Themen verbessern möchtest, dann melde dich für die Ausbildung zum Data Scientist an.







