Data Drift tritt auf, wenn die Daten, auf denen das Modell läuft, zu stark von den Trainingsdaten abweichen. Dieses Problem muss erkannt und vorhergesehen werden, da es die Vorhersageleistung im Laufe der Zeit verschlechtert. Hier erfährst du alles, was du über Data Drift wissen musst: Definition, Gefahren, Lösungen...
Beim Machine Learning werden verfügbare Daten verwendet, um ein Modell zu trainieren, damit es lernt, diese Daten zu erkennen, vorherzusagen oder zu reproduzieren. Die Dinge können jedoch kompliziert werden, wenn das Modell während des Produktionsprozesses eingesetzt wird.
Nehmen wir den häufigsten Fall des überwachten Lernens: Die Trainingsdaten werden mit einem Label versehen und das ist es, was unserem Modell hilft, seine Fehler zu quantifizieren, wenn es mit vergangenen Daten trainiert wird.
Sobald das Modell jedoch eingesetzt wird, sind die Daten, die vorhergesagt werden sollen, aktuelle Daten und haben daher kein Label oder Etikett.
Unabhängig von der Genauigkeit des Modells können Vorhersagen nur dann relevant sein, wenn die Daten, die dem Modell in der Produktion vorgelegt werden, den Daten, die für das Training verwendet wurden, ähnlich oder statistisch gleichwertig sind. Wenn dies nicht der Fall ist, kommt es zum sogenannten „Data Drift“.
Was sind die Ursachen von Data Drift ?
Data Drift ist eine Abweichung der Daten aus der realen Welt von den Daten, die zum Testen und Validieren des Modells vor dem Einsatz in der Produktion verwendet werden.
Es gibt viele Faktoren, die einen Data Drift verursachen können. Eine der Hauptursachen ist die zeitliche Dimension, da zwischen dem Zeitpunkt, an dem die Trainingsdaten gesammelt werden, und dem Zeitpunkt, an dem das auf diesen Daten trainierte Modell für die Vorhersage aus den realen Daten verwendet wird, eine lange Zeit vergehen kann.
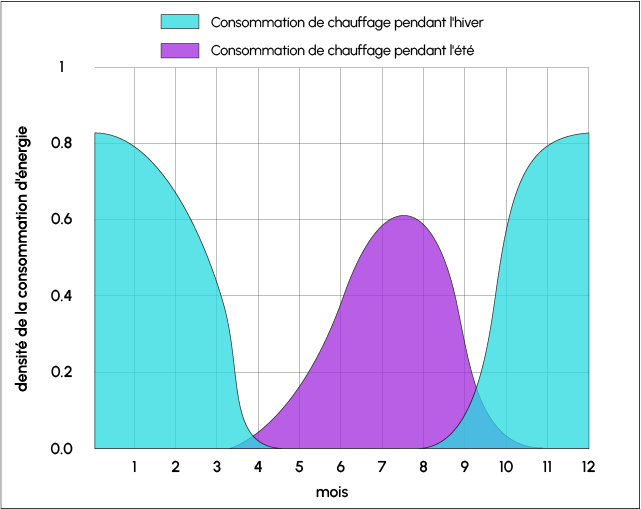
Eine weitere häufige Ursache für Data Drift ist die Saisonabhängigkeit. Einige Daten, die im Sommer gesammelt werden, können sich im Winter stark unterscheiden, wenn sie z. B. von der Temperatur oder der Länge der Tage beeinflusst werden.
Ebenso können Daten, die vor einem Ereignis gesammelt wurden, danach nicht mehr gültig sein. Beispielsweise sind viele Daten, die vor dem Aufkommen von Covid gesammelt wurden, inzwischen veraltet. Wenn ein Machine-Learning-Modell mit diesen Daten trainiert und mit aktuellen Daten getestet wird, wird nach dem Einsatz höchstwahrscheinlich ein Data-Drift-Problem auftreten.
>> Auch interessant: Adversial Examples im Machine Learning
Ein anderes Beispiel: Ein Computer Vision-Modell, das mit einem Datenbestand trainiert wird, der sich auf Straßen in Europa bezieht, wird nicht für Straßen in den USA geeignet sein. Die Auswahl der Trainingsdaten ist daher extrem wichtig.
Was sind die Risiken von Data Drift ?
Wenn ein Data Drift nicht rechtzeitig erkannt wird, werden die Vorhersagen des Modells falsch sein. Entscheidungen, die auf der Grundlage dieser Vorhersagen getroffen werden, haben daher negative Auswirkungen.
Wenn sich z. B. dein Geschmack geändert hat und Netflix keinen Zugriff auf deine neuesten Daten hat, kann es sein, dass das Modell dir Filme vorschlägt, die dir nicht gefallen oder zumindest nicht mehr gefallen.
Dieses Beispiel ist nicht sehr besorgniserregend, aber die Folgen können viel ernster sein. So kann z. B. ein Händler, der aufgrund eines Data Drifts falsch geleitet wurde, riesige Summen in eine Aktie ohne aktuellen Wert investieren.
Je nach Art, Umfang und Typ des Data Drifts ist der Aufwand unterschiedlich. Manchmal ist es möglich, das Problem zu lösen, indem das Modell erneut mit neuen Daten trainiert wird. Es kann jedoch auch erforderlich sein, ganz von vorne zu beginnen.
Neben den Daten kann auch das Modell selbst driften. Dies wäre z. B. der Fall bei einem Modell, das vor dem Covid verwendet wurde, um vorherzusagen, welche Studenten sich für Online-Kurse entscheiden werden. Bei einer Verwendung während der Covid-Krise wäre dieses Modell völlig nutzlos.
Dies wird als „Concept Drift“ bezeichnet. Dieses Problem kann durch E-Learning gelöst werden, indem das Modell bei jeder Beobachtung neu trainiert wird.
Es ist wichtig, einen wiederverwendbaren Prozess aufzubauen, um den Data Drift zu identifizieren. Man kann auch Schwellenwerte für den prozentualen Anteil des Drifts festlegen, der nicht überschritten werden darf, oder ein Warnsystem einrichten, um die notwendigen Maßnahmen zu ergreifen, bevor es zu spät ist.
Data Drift kann aus der Entwicklung der Daten selbst erkannt werden, oder wenn die Vorhersagen des Modells falsch sind.
Falsche Vorhersagen können jedoch nur erkannt werden, wenn eine manuelle Methode zum Auffinden des richtigen Labels zur Verfügung steht.
Wie entdeckt man einen Data Drift ?
Wenn du ein Machine-Learning-Modell einsetzt, ist es wichtig, seine Leistung regelmäßig zu überwachen. Nehmen wir zum Beispiel ein Computer Vision-Modell, das aus einem Datenbestand von 100 verschiedenen Hunderassen erstellt wurde.
Um zu überprüfen, ob seine Leistung aufgrund eines Data Drifts abnimmt, müssen alle neuen Bilder und Vorhersagen, die vom Feedbackschleifensystem aufgenommen wurden, durchgesehen werden. Die Vorhersagen müssen dann überprüft, bearbeitet oder bestätigt werden.
Durch den Vergleich der ursprünglichen Vorhersagen mit den bearbeiteten Vorhersagen kann überprüft werden, ob die Leistung überdurchschnittlich gut ist oder nicht.
Um alle Vorhersagen in Echtzeit zu validieren, müssen jedoch viele Personen Zugriff auf die Daten haben. Für diesen Vorgang ist daher eine große Belegschaft erforderlich.
Data Drifts können mithilfe von sequenziellen Analysemethoden, modellbasierten Methoden oder Methoden, die auf der zeitlichen Verteilung basieren, identifiziert werden.
Sequentielle Analysemethoden wie DDM (Drift Detection Method) oder EDDM (Early DDM) ermöglichen die Erkennung von Drift auf der Grundlage einer festen Fehlerrate.
Bei einer modellbasierten Methode wird ein angepasstes Machine-Learning-Modell verwendet, um die Drift zu identifizieren, indem die Ähnlichkeit zwischen einem Punkt oder einer Gruppe von Punkten und einer Referenz-Basislinie bestimmt wird.
Es ist notwendig, die Daten, die zur Erstellung des aktuellen Modells in der Produktion verwendet wurden, als „0“ zu kennzeichnen und die Echtzeitdaten als „1“ zu kennzeichnen.
Anschließend wird ein Modell erstellt, um die Ergebnisse zu bewerten. Wenn das Modell eine hohe Genauigkeit bietet, bedeutet dies, dass es problemlos zwischen den beiden Datensätzen unterscheiden kann. Daraus kann man schließen, dass ein Drift aufgetreten ist und das Modell neu kalibriert werden muss.
Wenn die Genauigkeit des Modells hingegen bei etwa 0,5 liegt, bedeutet dies, dass es keine nennenswerte Drift zwischen den beiden Datensätzen gegeben hat. Das Modell kann also weiterhin verwendet werden.
Diese Methode ist effizient, erfordert aber, dass das Modell jedes Mal, wenn neue Daten verfügbar sind, trainiert und getestet werden muss, was sehr kostspielig sein kann.
Schließlich gibt es noch eine Methode, die auf der Zeitfensterverteilung basiert und den Zeitstempel und das Auftreten von Ereignissen berücksichtigt. Bei der ADWIN-Technik (Adaptive Windowing) wird beispielsweise damit begonnen, das Fenster W dynamisch zu vergrößern, solange es keine offensichtlichen Änderungen im Kontext gibt, und es zu verkleinern, wenn eine Änderung festgestellt wird. Der ADWIN-Algorithmus versucht, zwei Unterfenster mit unterschiedlichen Mittelwerten zu finden, und lässt das ältere Unterfenster fallen.
Die wichtigsten Methoden zur Berechnung des Unterschieds zwischen zwei Populationen sind der Population Stability Index, die Kullback-Leibler-Divergenz, die Jensen-Shannon-Divergenz, der Kolmogorov-Smirnov-Test und die Wasserstein-Distanz.
Was ist der Kolmogorov-Smirno Test ?
Der Kolmogorov-Smirnov-Test (KS-Test) ist ein statistischer Test, der keine Eingabe durch den Nutzer erfordert. Er wird verwendet, um kontinuierliche oder diskontinuierliche Wahrscheinlichkeitsverteilungen zu vergleichen.
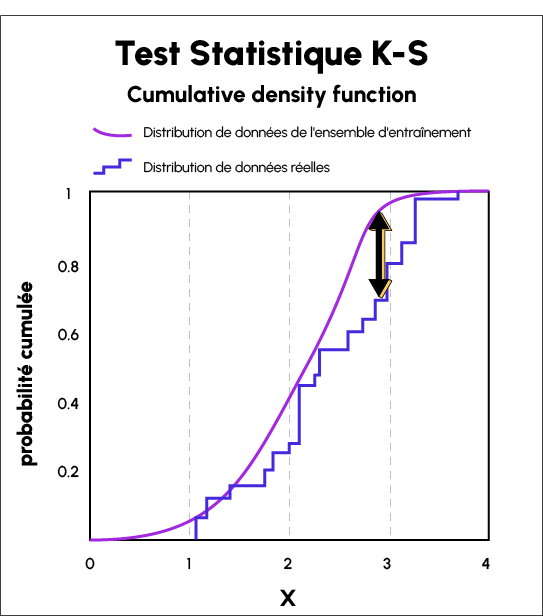
Man kann sie anwenden, um die Verteilung einer Stichprobe mit der Referenzwahrscheinlichkeitsverteilung oder zwei Stichproben von Populationsverteilungen mit gleicher Variabilität zu vergleichen, um zu überprüfen, ob sie von verschiedenen Populationsverteilungen mit unbekannten Parametern abgeleitet sind.
Die Methode ist nach Andrey Kolmogorov und Nikolai Smirnov benannt, die als erste ihre Verwendung für sehr große, von Menschen erzeugte Tabellen mit Zufallszahlen vorschlugen.
Die Kolmogorov-Smirnov-Statistik wird verwendet, um den Abstand zwischen den Verteilungsfunktionen der Daten aus der realen Welt der Stichproben und den Datenverteilungen des Trainingssatzes zu quantifizieren.
Sie liefert eine Liste von „p“-Werten für die Trainingsdaten und die Daten der realen Welt, und der Abstand zwischen den beiden Kurven enthüllt den Data Drift.
Wie löst man ein Data Drift Problem ?
Mithilfe der verschiedenen oben erwähnten Methoden kann ein Data Drift schnell erkannt werden. Anschließend ist es wichtig, Maßnahmen zu ergreifen, um das Problem zu beheben.
Es gibt jedoch einige Dinge, die beachtet werden müssen, bevor du zur Tat schreiten kannst. Zunächst solltest du die Daten in der Rückkopplungsschleife überprüfen. Es ist von entscheidender Bedeutung, dass keine verschlechterten Daten in die Pipeline eingespeist werden.
Wenn die Datenqualität in Ordnung ist, überprüfe die Leistung des Modells für einen bestimmten Geschäftsanwendungsfall.
Wenn das Modell immer noch in der Lage ist, zuverlässige Vorhersagen zu treffen, kannst du in Erwägung ziehen, einen Prozentsatz der neuen Daten, die über die Feedback-Schleife eingeflossen sind, zum Datensatz hinzuzufügen und das Modell erneut zu trainieren. Dadurch erhält man ein besseres Abbild der Realität bei gleichbleibender Genauigkeit.
Wenn das Modell nicht mehr wie erwartet funktioniert, bedeutet dies, dass die für das Training und die Validierung verwendeten Daten nicht repräsentativ für die Realität deines Anwendungsfalls waren. Du musst dann entweder einen kompletten Datensatz mit den neu eingeflossenen Daten neu aufbauen oder warten, bis du genügend Daten hast, um das Modell erneut zu trainieren.
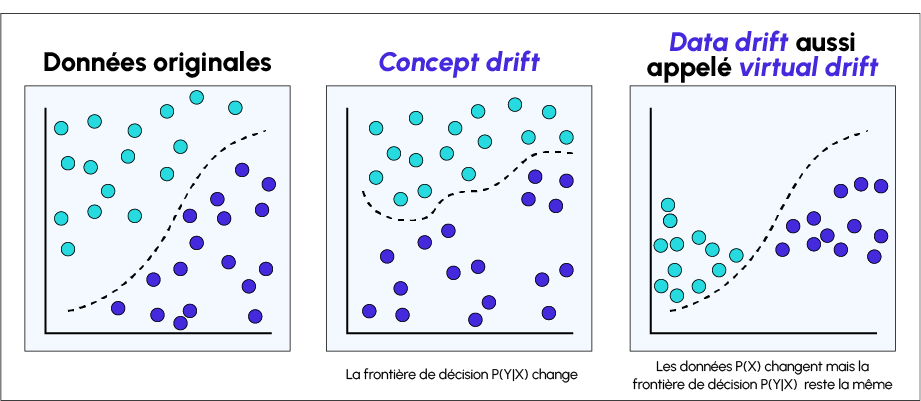
Data Drift vs Concept Drift : Was ist der Unterschied ?
Ein Data Drift tritt auf, wenn es eine Diskrepanz zwischen den Trainingsdaten eines Modells und den Daten der realen Welt gibt. Diese Änderung in den Daten verschlechtert die Leistung des Modells.
Ein Concept Drift tritt auf, wenn sich das Ziel der Vorhersagen des Modells oder seine statistischen Eigenschaften im Laufe der Zeit ändern. Das Modell hat während des Trainings eine Funktion gelernt, die die Zielvariable abbildet, hat sie aber im Laufe der Zeit wieder vergessen oder ist nicht in der Lage, die Muster in einer neuen Umgebung zu verwenden.
Beispielsweise müssen Modelle zur Erkennung von Spam möglicherweise angepasst werden, wenn sich die Definition von Spam ändert. Concept Drift kann saisonal (wie die Kleidermode), plötzlich (wie das Verbraucherverhalten nach der Covid-Pandemie) oder allmählich auftreten.
Um Concept Drift zu messen, kann man die Trainingsdaten kontinuierlich überwachen und Veränderungen innerhalb der Beziehungen des Datasets erkennen. Zu den beliebtesten Algorithmen zur Erkennung von Concept Drift gehören ADWIN (ADaptive WINdowing) für Streaming-Daten und der KS-Test oder Chi-Quadrat-Test für Batch-Daten.
Fazit
Nun weißt du, woher der Data Drift kommt, welche Ursachen er hat, welche Merkmale er aufweist und welche möglichen Lösungen du testen kannst, um ihn zu beheben. Data Drift und Concept Drift gehören zu den häufigsten Problemen beim Trainieren von Machine-Learning-Modellen.
Um ein Experte auf diesem Gebiet zu werden, kannst du dich bei DataScientest weiterbilden.
Unsere verschiedenen Kurse bieten dir die Möglichkeit, Data Science und Machine Learning zu beherrschen.
In unseren Programmen kannst du die Fähigkeiten erwerben, die du brauchst, um als Data Analyst, Data Scientist, Data Engineer oder Machine Learning Engineer zu arbeiten.
Nach Abschluss des Kurses wirst du keine Geheimnisse mehr vor der Verwaltung von Datenbeständen und dem Training von Machine-Learning-Modellen haben. Du wirst direkt bereit sein, dein Wissen in einem Unternehmen anzuwenden, wie die 80 % unserer Alumni, die sofort einen Job gefunden haben.
Unser innovativer Blended-Learning-Ansatz kombiniert Online-Lernen auf einer gecoachten Plattform mit kollektiven Masterclasses.
Darüber hinaus kannst du zwischen einem intensiven BootCamp, einer Weiterbildung oder einem dualen Studium wählen. Alle unsere Ausbildungen werden vollständig im Fernunterricht absolviert.
Unsere staatlich anerkannte Fortbildung kann über Deinen Bildungsgutschein finanziert werden.
Warte nicht länger und entdecke DataScientest!







