Grenzwert einer Funktion: Wie kann man ihn bestimmen?
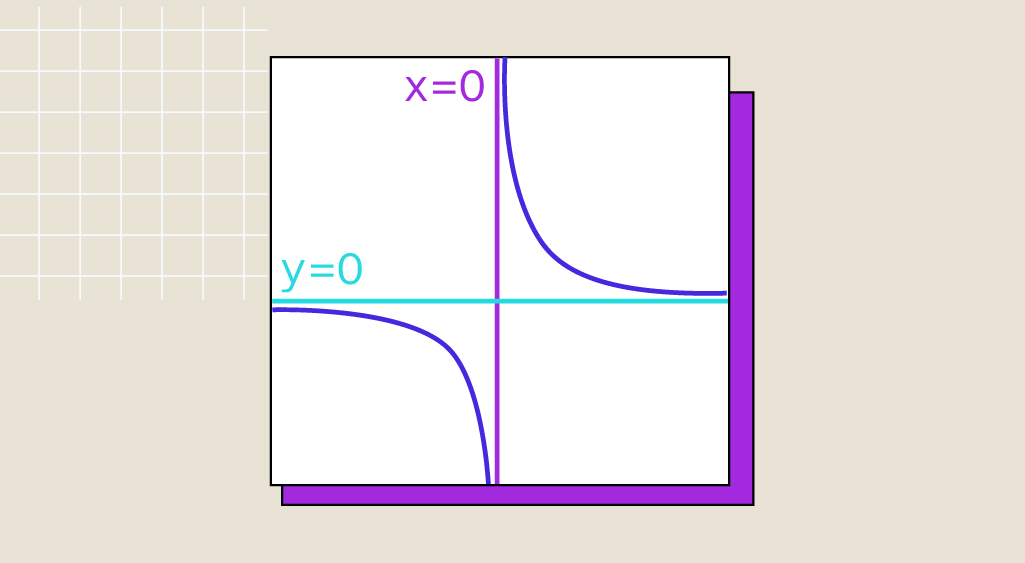
Alle wissenschaftlichen Disziplinen basieren auf Mathematik, und die Datenwissenschaft ist da keine Ausnahme. Wenn es sich bei den zu lösenden Problemen um Optimierungsprobleme handelt, ist es notwendig, zu wissen, was der Grenzwert einer Funktion ist. In diesem Artikel erfährst du, wie du den Grenzwert einer Funktion bestimmen kannst. Grenzwert einer Funktion vs. Grenze: Definition Der […]
Shell Schulung: Warum und wie man Bash lernt
In einer Shell Schulung lernst du, eine Shell wie Bash zu beherrschen. Hier erfährst du alles, was du wissen musst und wie du einen solchen Kurs absolvieren kannst. Wenn ein Computer startet, erkennt ein Kernel alle physischen Komponenten und ermöglicht es ihnen, miteinander zu kommunizieren und von grundlegender Software orchestriert zu werden. Damit Menschen jedoch […]
Cisco DevOps Training: Inhalt und entwickelte Fähigkeiten

Als Marktführer im Bereich der drahtlosen Kommunikation ist Cisco bei Tausenden von Unternehmen auf der ganzen Welt vertreten. Branchenexperten, die die Cisco-Tools perfekt beherrschen, haben daher einen klaren Vorteil auf dem Arbeitsmarkt. Genau aus diesem Grund bietet Cisco seine DevOps-Schulung an. Warum sollte man den Cisco DevOps-Kurs besuchen? Ursprünglich war DevOps eher eine Philosophie, die […]
Power Automate Feed erstellen in 6 Schritten

Power Automate Feed: Seit den letzten Jahren wird versucht, IT-Prozesse zu automatisieren, um in Unternehmen Zeit zu sparen und damit die Produktivität zu steigern. Dies wird als RPA bezeichnet: Robotic Process Automation. Heute präsentiert dir DataScientest ein Tutorial darüber, wie du mit Power Automate einen RPA-Prozess auf Microsoft erstellen kannst. Beginnen wir gleich mit der […]
Power Automate: Alles über das Automatisierungstool von Microsoft

Immer schneller, immer weiter. Um die Produktivität zu steigern, setzen viele Unternehmen heute auf Automatisierung und Technologien wie künstliche Intelligenz. Es gibt Tools und Lösungen, mit denen sich viele Geschäftsprozesse automatisieren lassen. Zu den bekanntesten gehört Microsoft Power Automate. Was genau ist Power Automate? Power Automate, früher Microsoft Flow genannt, ist ein Tool zur Automatisierung […]
Fremdschlüssel SQL : Ein wichtiges Schutzsystem
Fremdschlüssel SQL: Wer ein SQL-Datenbankverwaltungssystem entwirft, tut gut daran, das Fremdschlüsselsystem zu kennen und zu implementieren. Langfristig wird er davon profitieren. Ein Fremdschlüssel ist eine Spalte (oder mehrere Spalten) in einer Datenbank, die mit der Spalte Primärschlüssel in einer anderen Tabelle verknüpft ist. Der Primärschlüssel ist eine einfache Kennung. Die nützlichen – und veränderbaren – […]
Cloud Administrator: Aufgaben, Ausbildung und Gehalt

Cloud Administrator: Laut einer Statistik von Rackspace Technology und Google Cloud haben mehr als die Hälfte der Unternehmen 100 % ihrer Infrastruktur in der Cloud. Was die Nutzung der Cloud angeht, so sind es laut einer anderen Umfrage von Harvey Nash nicht weniger als 90 % der Unternehmen. Die Annahme ist eindeutig und sie hat […]
DNS: Was ist das Domain Name System und welche Rolle spielt es in der Datenwissenschaft?

Das Domain Name System (DNS) ist eines der Schlüsselelemente, die das Internet am Laufen halten. Wie ein virtuelles Telefonbuch wandelt es Domainnamen in IP-Adressen um, damit Internetnutzer auf Websites zugreifen können. Hier erfährst du alles, was du über dieses System und seine Bedeutung für die Data Science wissen musst! In den Anfängen des Internets war […]
Dense Neural Network – Definition und Funktionsweise
Bei der Gestaltung eines tiefen neuronalen Netzes können verschiedene Arten von Architekturen der ersten Ebene verwendet werden. Eine davon ist das dichte neuronale Netzwerk. Worum handelt es sich also? Wie funktioniert es? Finde die Antworten in diesem Artikel. Was ist ein dense neural network? Ein dichtes neuronales Netz ist ein Modell für maschinelles Lernen, bei […]
Kurtosis: Die Häufigkeit von Ausreißern berechnen

Die Qualität der Leistung des maschinellen Lernens hängt in hohem Maße von den verfügbaren Informationen ab. Deshalb müssen Data Scientists die verwendeten Datensätze genau untersuchen. Dazu steht ihnen eine Vielzahl von statistischen Werkzeugen zur Verfügung. Eines davon ist die Kurtosis. Worum geht es also? Wozu dient sie? Hier findest du die Antworten. Was ist Kurtosis? […]
IT Systemadministrator: Alles über diesen Beruf im Zeitalter der Data Science
Der IT-Administrator, der früher für die Verwaltung und Optimierung von IT-Systemen zuständig war, ist heute ein wichtiger Akteur bei der Integration von Data Science und Datenanalyse in Unternehmen. Hier erfährst du alles, was du über diesen Beruf und seine Entwicklung im Zeitalter von Big Data wissen musst! In der Vergangenheit bestand die Hauptverantwortung des IS-Administrators […]
Meta enthüllt Llama 2, aber diesmal als Open Source: Warum ist das wichtig?

Meta hat gerade seine neue LLM, Llama 2, angekündigt, diesmal als Open Source und für alle Cloud-Anbieter verfügbar. Ist Llama 2 ein neues LLM? Meta kündigte am 18. Juli in einem Blog-Eintrag Llama 2 an, eine LLM, die aus 7 bis 70 Milliarden Parametern besteht und der Nachfolger von Llama ist. Im Gegensatz zu seinem […]
