
Daniel ist wieder da, die Symbolfigur unserer Weiterbildungen, die unsere Lernenden bis zum Abschluss begleitet. Heute wird er Dir ein Modell vorstellen, das häufig in der Computer Vision verwendet wird: VGG.
Vor einiger Zeit hatten wir bereits die Gelegenheit, das Konzept des Transfer Learning näher zu erläutern. Wenn Du unseren Artikel zu diesem Thema verpasst hast, kannst Du ihn hier noch einmal anschauen. Kurz erklärt, bezeichnet Transfer Learning die Fähigkeit, vorhandenes Wissen, das zur Lösung bestimmter Probleme entwickelt wurde, zur Lösung eines neuen Problems zu nutzen.
Ein paar Hintergrundinformationen
VGG ist ein neuronales Netz aus Faltungszellen, das von K. Simonyan und A. Zisserman von der Universität Oxford entwickelt wurde und das durch den Gewinn des ILSVRC-Wettbewerbs (ImageNet Large Scale Visual Recognition Challenge) im Jahr 2014 Berühmtheit erlangte. Das Modell erreichte auf Imagenet eine Genauigkeit von 92,7 %, was einen der höchsten Werte darstellt. Es stellte einen Fortschritt gegenüber früheren Modellen dar, indem es in den Faltungsmatrixen kleinere Faltungskerne (3×3) nutzte als bis dahin üblich. Das Modell wurde über Wochen hinweg mithilfe modernster Grafikkarten trainiert.
ImageNet
ImageNet ist eine gigantische Datenbank mit über 14 Millionen gelabelten Bildern, die in über 1000 Klassen eingeteilt sind, Stand 2014. Im Jahr 2007 begann eine Forscherin namens Fei-Fei Li mit dem Projekt, einen solchen Datensatz zu erstellen. Zwar ist die Modellierung ein sehr wichtiger Aspekt, um eine gute Leistung zu erzielen, aber über qualitativ hochwertige Daten zu verfügen, ist ebenso wichtig, um ein erstklassiges Lernergebnis zu erzielen. Die Daten wurden von Menschen aus dem Internet gesammelt und mit Tags versehen. Sie sind daher Open Source und gehören somit keinem bestimmten Unternehmen.
💡 Auch interessant:
| Was genau ist ein Deep Neural Network? |
| Recurrent Neural Network (RNN): Was genau ist das? |
| Convolutional Neural Network (CNN): Alles, was Du wissen solltest |
Seit 2010 findet jedes Jahr die ImageNet Large Scale Visual Recognition Challenge statt, bei der es darum geht, Modelle der Bildverarbeitung herauszufordern. Der Wettbewerb wird auf einer Teilmenge des ImageNet durchgeführt, die aus : 1,2 Millionen Trainingsbildern, 50.000 zur Validierung und 150.000 zum Testen des Modells.
Die Architektur
In der Praxis gibt es zwei verschiedene Algorithmen: VGG16 und VGG19. In diesem Artikel werden wir uns auf die Architektur des ersteren konzentrieren. Obwohl beide Architekturen sehr ähnlich sind und der gleichen Logik folgen, weist VGG19 eine größere Anzahl von Faltungsmatrixen auf.
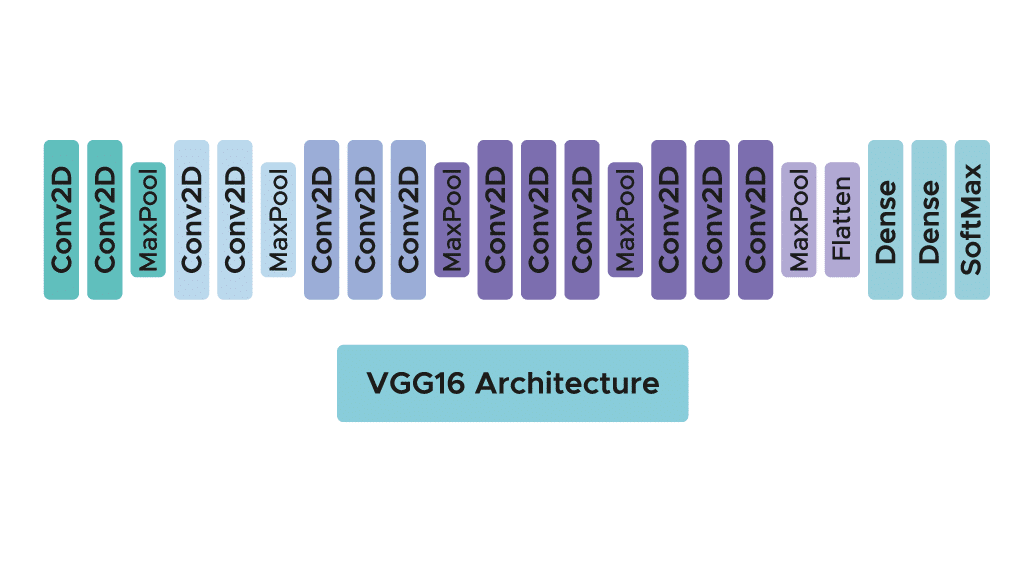
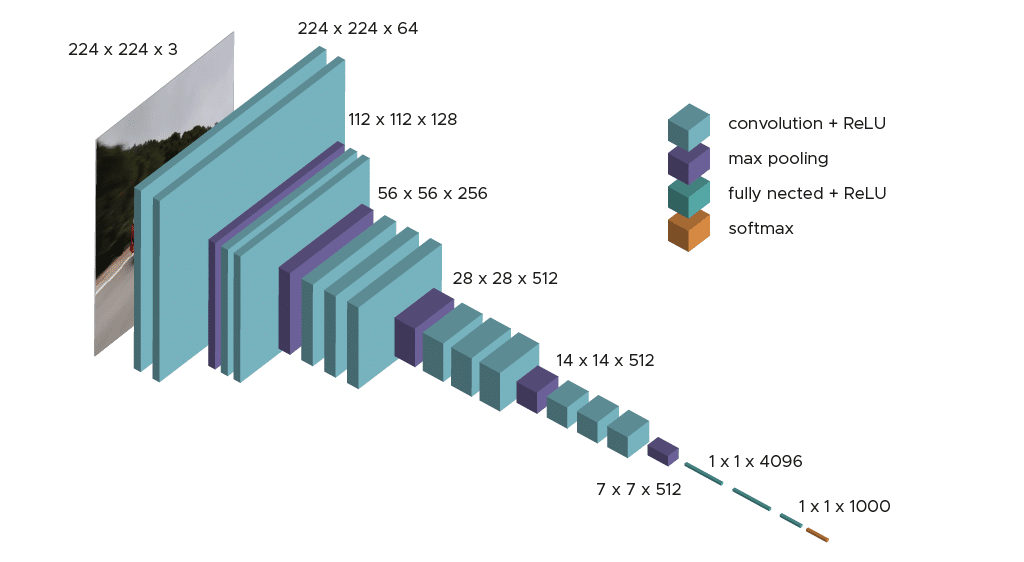
Das Modell erfordert nur eine spezifische Vorverarbeitung, bei der der durchschnittliche RGB-Wert, der über den Lernsatz berechnet wurde, von jedem Pixel subtrahiert wird.
Während des Lernens des Modells ist der Input für die erste Faltungsschicht ein RGB-Bild der Größe 224 x 224. Für alle Faltungsschichten ist die Faltungsmatrix 3×3 groß: die kleinste Dimension, um die Konzepte von oben, unten, links/rechts und mittig zu erfassen. Dies war eine Besonderheit des Modells zum Zeitpunkt seiner Veröffentlichung. Bis zur Markteinführung von VGG16 haben sich viele Modelle für größere Faltungskerne entschieden (z. B. Größe 11 oder Größe 5). Diese Schichten haben zum Ziel, das Bild zu filtern, indem sie nur diskriminierende Informationen wie atypische geometrische Formen filtern.
Diese Faltungsschichten werden von Max-Pooling-Schichten begleitet, die jeweils eine Größe von 2×2 haben, um die Größe der Filter während des Lernens zu reduzieren.
Am Output der Convolution- und Pooling-Schichten haben wir 3 Schichten von Fully-Connected-Neuronen. Die ersten beiden bestehen aus 4096 Neuronen und die letzte aus 1000 Neuronen mit einer Softmax-Aktivierungsfunktion, um die Klasse des Bildes zu bestimmen.
Wie Du siehst, ist die Architektur klar und einfach zu verstehen, was auch eine Stärke dieses Modells darstellt.
Ergebnisse aus dem ImageNet
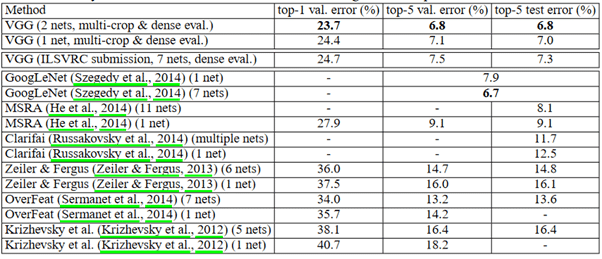
Die obige Abbildung vergleicht die Ergebnisse verschiedener Modelle aus dem Jahr 2014 oder auch aus früheren Jahren. Wir können sehen, dass VGG sowohl im Validierungs- als auch im Testsatz die besten Ergebnisse liefert. Bemerkenswert ist auch, dass das Modell deutlich bessere Ergebnisse liefert als in den Jahren 2012 und 2013.
Was hat Transfer Learning mit all dem zu tun?
Wie bereits erwähnt, kann die Trainingszeit für ein Modell wie VGG sehr lang sein, vor allem, wenn man nur wenige Ressourcen zur Verfügung hat. Da das Modell im ImageNet trainiert wurde, kann es außerdem interessant sein, die Gewichte des bereits trainierten Modells abzurufen, insbesondere die Filter in den Faltungsschichten, die aus dem Training im ImageNet stammen. In der Praxis wird dies auch so gehandhabt: Wir rufen die Gewichte aus den Faltungsschichten ab und müssen nur die drei Schichten trainieren, die wir hinzufügen. Das Prinzip bleibt das gleiche: das in ImageNet gewonnene Wissen zur Lösung eines naheliegenden Problems zu nutzen.
Insbesondere ist es möglich, das vorab trainierte Modell sehr einfach direkt abzurufen und die spezifische Vorverarbeitung anzuwenden, die das Modell verlangt.
Ein kleiner Einblick in die Praxis
In der Praxis gibt es zwei verfügbare Algorithmen: VGG16 und VGG19.
Mit Hilfe der keras-Bibliothek von Tensorflow ist es einfach, das bereits trainierte Modell standardmäßig von ImageNet abzurufen.
Zunächst müssen wir die gleiche spezifische Verarbeitung anwenden, die zum Zeitpunkt des Trainings des Modells angewandt wurde. Darüber hinaus ergänzen wir die Trainingsdaten durch zusätzliche Daten, um ein Risiko des Overlearnings zu verhindern. Dabei ist es auch wichtig, zu überprüfen, ob die als Input gegebenen Bilder RGB-Bilder im Format 224×224 sind.
Dann können wir die optimierten Gewichte aus den Faltungsschichten abrufen und die drei Dense Layer trainieren, die wir hinzufügen und zusammensetzen:
Wenn die Ergebnisse nach dem Training nicht gut genug sind, ist es nicht mehr möglich, die letzten Faltungsmatrixen zu fixieren und sie erneut zu trainieren, um eine bessere Leistung zu erzielen. Auch hier hängt alles von den zur Verfügung stehenden Ressourcen ab, sodass sich dieser zusätzliche Schritt als zeitaufwendig herausstellen kann.
💡Auch interessant:
Zusammenfassung
VGG ist ein bekannter Algorithmus in der Computer Vision, der sehr oft durch Lerntransfer eingesetzt wird, um ein erneutes Training zu vermeiden und ähnliche Probleme zu lösen, auf die VGG bereits trainiert wurde. Es gibt noch viele andere Algorithmen des gleichen Typs wie VGG, wie z. B. ResNet oder Xception, die in der Keras-Bibliothek verfügbar sind. Wenn Du Dich im Bereich Deep Learning und Computer Vision weiterbilden möchtest, dann nimm an unserem Intensivkurs oder unserem berufsbegleitenden Kurs teil.







