Le deep learning fascine autant qu’il intimide. Entre équations, GPU et vocable ésotérique, on pourrait croire qu’il faut un doctorat en mathématiques pour en saisir la logique. Pourtant, le principe est simple : apprendre par l’exemple. Pour le voir de ses propres yeux — littéralement — rien ne surpasse TensorFlow Playground.
Ce petit outil accessible en ligne permet de manipuler un réseau de neurones en temps réel, d’observer les réactions, et surtout, de comprendre comment il apprend. Quelques minutes suffisent pour transformer une idée abstraite en expérience concrète.
Le deep learning en quelques lignes
Depuis une dizaine d’années, le deep learning — ou apprentissage profond — domine la reconnaissance d’images, la traduction automatique et la synthèse de texte. L’idée fondatrice remonte pourtant aux années 1950 : imiter (grossièrement) le fonctionnement des neurones biologiques. Un neurone artificiel reçoit des entrées numériques, les pondère, y ajoute éventuellement un biais et applique une fonction d’activation. Alignés en couches successives, ces neurones transforment peu à peu les données brutes en représentations aptes à séparer, prédire ou générer.
Pourquoi “profond” ? Parce que les réseaux modernes empilent des dizaines, voire des centaines de couches, chacune capturant une abstraction plus subtile que la précédente : des arêtes aux motifs, des motifs aux objets, puis des objets à la scène entière. Le tout est entraîné par une méthode d’optimisation — souvent la descente de gradient — qui ajuste les poids pour minimiser une erreur mesurée sur un échantillon d’exemples annotés.
TensorFlow Playground : un laboratoire dans le navigateur
Ouvrez TensorFlow Playground et, sans rien installer, un réseau minimal s’affiche. À gauche, des points colorés représentent les données ; au centre, des cercles (les neurones) reliés par des flèches (les poids) ; à droite, les hyper-paramètres modifiables par simple clic : taux d’apprentissage, fonction d’activation, régularisation, taille de lot, etc. Lorsque l’on appuie sur Train, chaque itération réactualise la frontière de décision en temps réel.
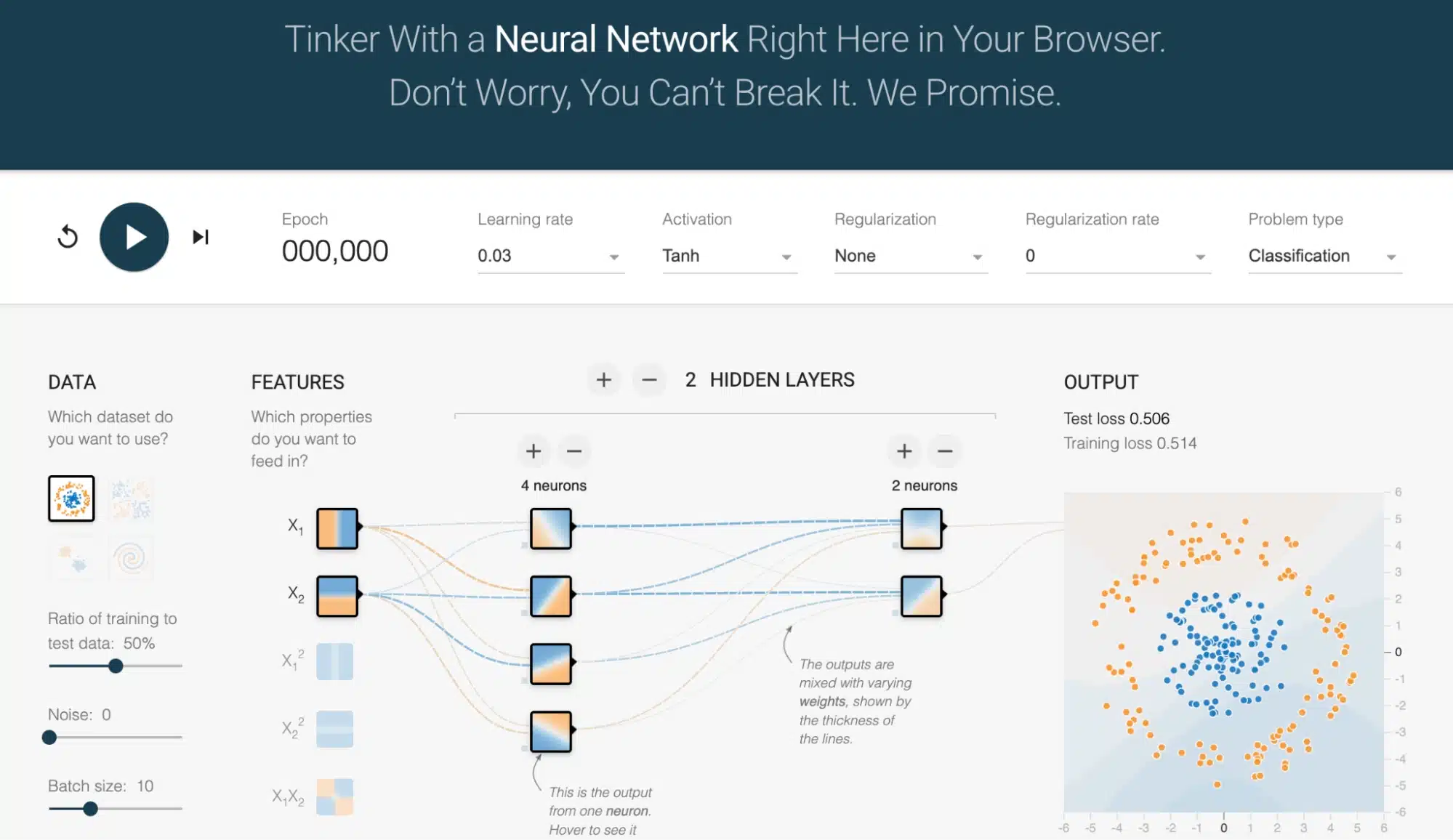
Pourquoi cet outil est-il si puissant pour comprendre ?
- Visualisation instantanée : la frontière évolue sous vos yeux, illustrant la descente de gradient bien mieux qu’un graphique statique.
- Sécurité : aucun risque d’effacer un disque ou de faire fondre un GPU.
- Partage aisé : toutes les options sont encodées dans l’URL ; il suffit de la copier pour partager une configuration exacte.
Anatomie d’un réseau depuis Playground
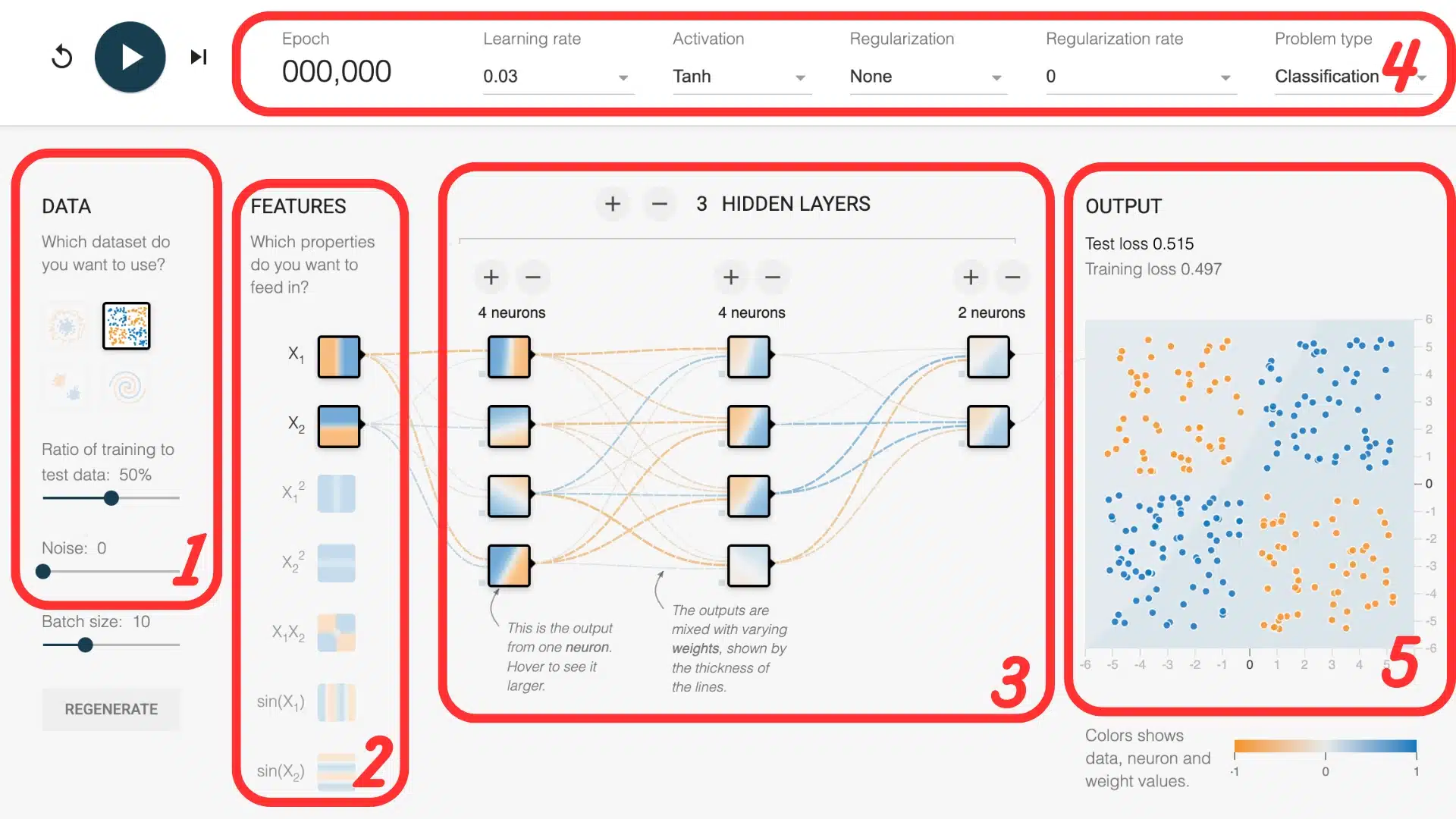
1. Les jeux de données
Playground propose quatre datasets synthétiques : un nuage linéairement séparable, deux jeux non linéaires (cercle et “lunes”), et l’incontournable spirale surnommée “l’escargot”. Ces données bidimensionnelles sont assez simples pour tenir dans un graphique, tout en étant suffisamment riches pour tester la puissance d’un réseau profond.
2. Les caractéristiques (features)
Par défaut, seules les coordonnées x et y sont utilisées comme entrées. Mais on peut activer d’autres caractéristiques dérivées : x², y², x·y, sin(x) ou sin(y). Ces transformations permettent au modèle de mieux capturer des motifs complexes. Par exemple, un nuage en forme de cercle devient bien plus facile à séparer si l’on ajoute x² + y² comme information : la frontière de décision peut alors devenir circulaire, même avec un réseau simple.
3. L’architecture
Sous les données, une glissière permet d’ajouter des couches et de régler le nombre de neurones. Un réseau sans couche cachée équivaut à une régression linéaire : il ne résout que les séparations linéaires. Avec une couche de trois neurones, le modèle capture déjà des courbes. Trois couches de huit neurones viennent à bout du dataset en spirale, tandis que pousser la profondeur encore plus loin expose au sur-apprentissage — d’où l’importance de la régularisation.
4. Les hyper-paramètres
Le taux d’apprentissage gouverne l’ampleur des mises à jour : trop grand, la perte oscille ; trop petit, le modèle stagne. Les fonctions d’activation — ReLU, tanh, sigmoid — injectent la non-linéarité nécessaire ; ReLU converge souvent plus vite, tanh se montre parfois plus stable. La régularisation L2 ajoute une pénalité sur les poids pour empêcher le réseau de mémoriser le bruit.
5. Visualiser les résultats
Une fois l’entraînement lancé, deux éléments sont à surveiller : la frontière de décision, qui évolue visuellement dans le plan, et la courbe de perte en bas à droite. La frontière montre comment le réseau apprend à séparer les classes ; plus elle épouse la forme des données, mieux le modèle a compris. La courbe de perte, elle, indique si l’erreur diminue — un bon signe que l’apprentissage progresse.
Deux défis à reproduire
Tous les paramètres des exercices ci-dessous sont déjà encodés dans les liens, il suffit de cliquer pour atterrir sur la configuration décrite.
Défi 1 : Premiers Pas
Lien : Défi – Premiers Pas
Lancez l’entraînement : en quelques secondes, la frontière commence à dessiner une séparation en deux zones bien nettes. Essayez ensuite de réduire le taux d’apprentissage et observez comment le modèle apprend plus lentement. Changez aussi la fonction d’activation, par exemple en passant de tanh à ReLU : la vitesse et la forme de convergence peuvent varier, même si la tâche reste simple. C’est un bon premier exercice pour prendre en main les paramètres sans se perdre dans la complexité.
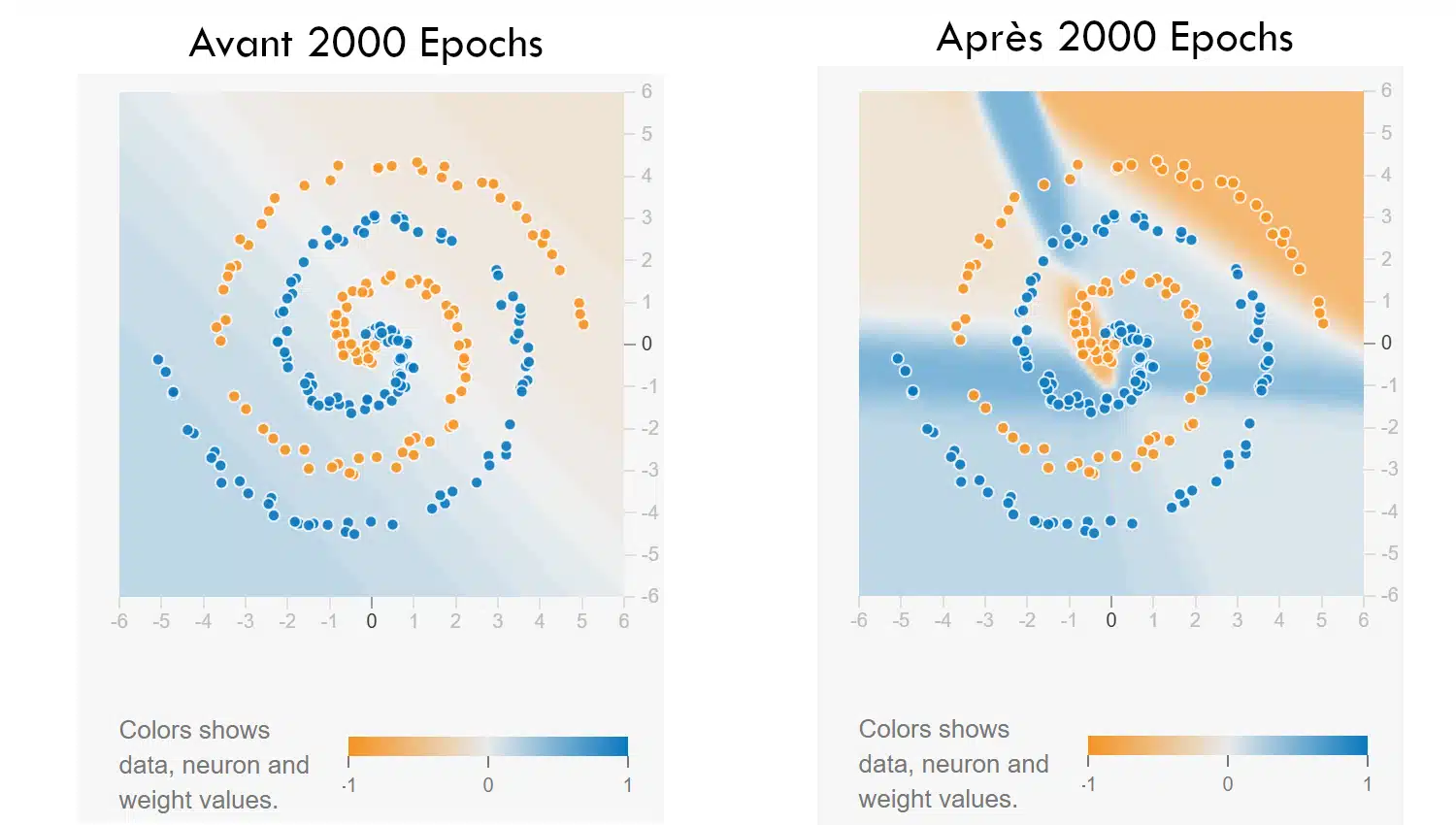
Défi 2 : Spirale
Lien : Spirale
Dans ce deuxième exercice, le réseau doit apprendre à classer un jeu de données en forme de spirale — un motif réputé difficile. La configuration de départ volontairement limitée (seulement les features x et y) oblige à jouer sur l’architecture et les hyperparamètres pour réussir.
Lancez l’entraînement : la frontière est chaotique au début. À vous de trouver une combinaison de couches, neurones, fonction d’activation, voire de régularisation, qui permet au réseau de suivre les courbes du motif. C’est un bon moyen de voir à quel point la profondeur ou un petit changement de paramètre peuvent faire toute la différence.
Bonus difficulté : interdiction d’ajouter des features dérivées. Tout doit passer par la structure du modèle.
Ce que l’on retient du Playground
Une dizaine de minutes passées dans Playground suffit à dégager trois enseignements fondamentaux :
- Le réseau apprend en ajustant ses poids pour réduire l’erreur ; la descente de gradient n’est rien d’autre qu’un cycle d’essais et d’erreurs automatisé.
- La non-linéarité — soit via des caractéristiques, soit via des activations — est indispensable dès qu’une droite ne suffit plus.
- Les hyper-paramètres font la loi : un mauvais taux d’apprentissage ou une architecture surdimensionnée peuvent ruiner l’entraînement aussi sûrement qu’un bug dans le code.
Ces constats s’observent, non se devinent : l’image en mouvement imprime dans l’esprit ce que trois pages d’algèbre résument moins clairement.
TensorFlow Playground ne sert pas à produire un modèle industriel, mais à visualiser le cœur du deep learning : la transformation progressive d’un espace de données sous l’effet d’un apprentissage itératif. En réduisant le sujet à des points colorés et à quelques boutons, l’outil met la mécanique à la portée de quiconque dispose d’un navigateur, de là, franchir le pas vers Keras ou PyTorch devient un simple changement d’interface. Alors, ouvrez la page, jouez quelques minutes, ajustez un paramètre, observez le résultat, et sentez la théorie prendre vie. L’apprentissage automatique, si complexe soit-il, commence toujours par un premier clic sur Train.









