
Le langage Python étant un des plus utilisés, il contient énormément de frameworks, et beaucoup sont développés exclusivement pour la Data Science. Dans cet article, nous allons donc vous parler en détail de l’un d’entre eux : PyTorch.
La popularité de la Data Science ne cesse de croître ces dernières années, et cela entraîne une explosion des ressources mises à dispositions des programmeurs : il n’est plus nécessaire de tout coder à la main. Des environnements de programmation tels que Pytorch, dits « frameworks », permettent d’utiliser des modèles complexes en seulement quelques lignes.
L'histoire de Pytorch
Les frameworks permettent de donner un cadre de travail et des outils pour faciliter la programmation. Ils sont généralement développés en « open source », c’est-à-dire que le code est accessible et modifiable par tous, ce qui permet fiabilité, transparence et un entretien continu.
PyTorch ne déroge pas à cette règle. Basé sur l’ancienne librairie Torch, PyTorch a été lancée officiellement en 2016 par une équipe du laboratoire de recherche de Facebook, et est depuis développé en open source. L’objectif de ce framework est de permettre l’implémentation et l’entraînement de modèles de Deep Learning de manière simple et efficiente. Sa fusion en 2018 avec Caffe2 (un autre framework de Python) a permis d’améliorer encore plus ses performances.
Pytorch est aujourd’hui utilisé par 17% des développeurs Python (étude Python Foundation 2020), et dans de nombreuses entreprises comme Tesla, Uber etc.
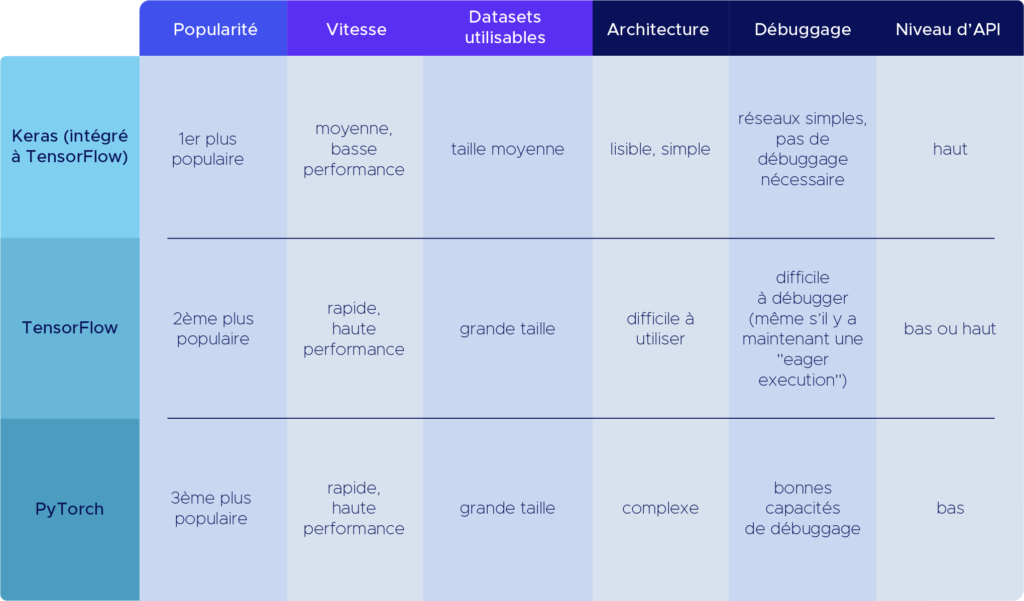
Pytorch vs Keras vs Tensorflow
Il semble difficile de présenter PyTorch sans prendre le temps de parler de ses alternatives, toutes créées à quelques années d’intervalle avec sensiblement le même objectif mais des méthodes différentes.
Keras a été développé en mars 2015 par François Chollet, chercheur chez Google. Keras a vite gagné en popularité grâce à son API facile à utiliser, qui s’inspire grandement de scikit-learn, la librairie de Machine Learning standard de Python.
Quelques mois plus tard, en novembre 2015, Google a publié une première version de TensorFlow qui est vite devenu le framework de référence en Deep Learning, car il permet d’utiliser Keras. Tensorflow a également mis au point un certain nombre de fonctionnalités en apprentissage profond dont les chercheurs avaient besoin pour créer facilement des réseaux de neurones complex.
Keras était donc très simple à utiliser, mais n’avait pas certaines fonctionnalités « bas niveau » ou certaines personnalisations nécessaires aux modèles de pointe. À l’inverse, Tensorflow donnait accès à ces fonctions, mais ne ressemblait pas au style habituel de Python et avait une documentation très compliquée pour les néophytes.
PyTorch a résolu ces problèmes en créant une API à la fois accessible et facile à personnaliser, permettant de créer de nouveaux types de réseaux, des optimiseurs et des architectures inédites.
Ceci-dit, les évolutions récentes de ces frameworks ont grandement rapproché leur mode de fonctionnement. Avant de rentrer dans les détails techniques de PyTorch, voici un tableau récapitulatif des différences entre ces outils. Keras et Tensorflow fonctionnant dorénavant de pair, il est plus pertinent de les présenter conjointement.
Utilisation de PyTorch pour le Deep Learning
Nous avons parlé de la complexité des modèles et des réseaux sans parler de la vitesse d’exécution des algorithmes. En effet, PyTorch est pensé pour minimiser ce temps et utiliser au mieux les spécificités du hardware.
PyTorch représente les données sous forme de tableaux multidimensionnels, similaires aux tableaux NumPy, appelés « tenseurs ». Les tenseurs stockent les inputs du réseau de neurones, les paramètres des hidden layers et les outputs. À partir de ces tenseurs, PyTorch peut effectuer, de manière cachée et efficace, 4 étapes pour entraîner le réseau :
- Assembler un graphe à partir des tenseurs du réseau de neurones, ce qui permet une structure dynamique, il est possible de modifier le réseau de neurones (nombre de noeuds, connexions entre eux…) durant l’apprentissage.
- Effectuer les prédictions du réseau (« forward pass »)
- Calculer la perte ou erreur par rapport aux prédictions
- Traverser le réseau en sens inverse : « backpropagation », et ajuster les tenseurs afin que le réseau fasse des prédictions plus précises sur la base de la perte/erreur calculée.
Cette fonction de PyTorch appelée « Autograd » est très optimisée, et est compatible avec l’utilisation des GPUs et le data parallelism, ce qui accélère considérablement les calculs. Par ailleurs, cela permet une utilisation sur tous les clouds, alors que Tensorflow par exemple n’est optimisé que pour GoogleCloud et ses TPU.
Récemment, et en partenariat avec AWS (Amazon Web Services), Pytorch a devoilé 2 nouvelles fonctionnalités. La première, baptisée TorchServe, permet de gérer efficacement le déploiement de réseaux de neurones déjà entraînés. La seconde, TorchElastic, permet d’utiliser Pytorch sur des clusters Kubernetes tout en étant résistant aux pannes.
Ces 3 frameworks ont donc leur propre spécificité. En particulier PyTorch est très adapté pour les réseaux de neurones complexes et profonds. Pour découvrir PyTorch, le site officiel propose des tutoriels.
Pour approfondir votre pratique de ce framework, notre formation de Data Scientist propose des modules d’enseignement dédiés au Deep Learning avec PyTorch.
Pourquoi utiliser PyTorch ?
PyTorch est une bibliothèque d’apprentissage automatique assez récente, mais elle dispose d’un grand nombre de manuels et de tutoriels où il est possible de trouver des exemples. Elle dispose également d’une communauté qui se développe à pas de géant.
PyTorch dispose d’une interface très simple pour la création de réseaux neuronaux bien qu’il soit nécessaire de travailler directement avec les tensors sans avoir besoin d’une bibliothèque de plus haut niveau comme Keras pour Theano ou Tensorflow.
Contrairement à d’autres outils d’apprentissage automatique tels que Tensorflow, PyTorch fonctionne avec des graphes dynamiques plutôt que statiques. Cela signifie qu’au moment de l’exécution, les fonctions peuvent être modifiées et que le calcul des gradients variera avec elles. En revanche, dans Tensorflow, il faut tout d’abord définir le graphe de calcul, puis utiliser la session pour calculer les résultats du tensor, ce qui rend le débogage du code plus difficile et la mise en œuvre plus fastidieuse.
PyTorch est compatible avec les cartes graphiques (GPU). Il utilise en interne CUDA, une API qui relie le CPU au GPU et qui a été développée par NVIDIA.
Avantages de PyTorch
Bien que PyTorch présente de nombreux avantages, nous nous concentrerons ici sur quelques-uns.
1. PyTorch et Python
La plupart des travaux liés à l’apprentissage automatique et à l’Intelligence Artificielle sont effectués à l’aide de Python. Or, PyTorch et Python sont de la même famille, ce qui signifie que les développeurs Python devraient se sentir plus à l’aise lorsqu’ils codent avec PyTorch qu’avec d’autres frameworks de Deep Learning.
2. Facile à apprendre
Comme le langage Python, PyTorch est considéré comme relativement plus facile à apprendre par rapport à d’autres frameworks. La raison principale est due à sa syntaxe simple et intuitive.
3. Communauté forte
Bien que PyTorch soit un framework relativement récent, il a développé très rapidement une communauté dédiée de développeurs. De plus, la documentation de PyTorch est très organisée et utile pour les débutants.
4. Débogage facile
PyTorch est profondément intégré à Python, à tel point que de nombreux outils de débogage Python peuvent être facilement utilisés avec.









