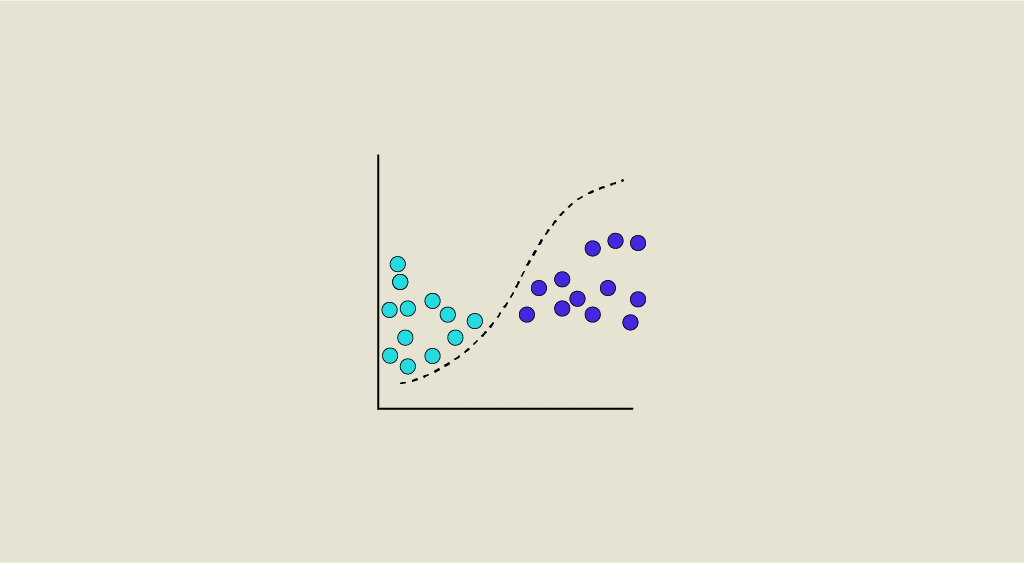
Le Data Drift ou dérive de donnée survient quand les données sur lequel s’exécute le modèle diffèrent de façon trop importantes des données d'entraînement. Ce problème doit être détecté et anticipé, car il dégrade les performances de prédiction au fur et à mesure du temps. Découvrez tout ce que vous devez savoir sur le data drift : définition, dangers, solutions...
Le Machine Learning consiste à utiliser les données disponibles pour entraîner un modèle, afin de lui apprendre à reconnaître, prédire ou reproduire ces données. Toutefois, les choses peuvent se compliquer lors du déploiement du modèle durant le processus de mise en production.
Prenons le cas le plus courant de l’apprentissage supervisé : les données d’entraînement sont labellisées et c’est ce qui aide notre modèle à quantifier ses erreurs lors de l’entraînement sur des données passées.. Or, une fois que le modèle est déployé, les données à prédire sont des données actuelles et donc ne possèdent pas de label ou étiquette.
Peu importe le niveau de précision du modèle, les prédictions ne peuvent s’avérer pertinentes que si les données soumises au modèle en production sont similaires ou statistiquement équivalentes aux données utilisées pour l’entraînement. Dans le cas contraire, on apercevra le phénomène du le « data drift » : la dérive de données.
Quelles sont les causes du Data Drift ?
Le Data Drift est une variation des données du monde réel par rapport aux données utilisées pour tester et valider le modèle avant de le déployer en production.
De nombreux facteurs peuvent causer la dérive des données. L’une des causes principales est la dimension temporelle, car une longue période peut s’écouler entre le moment où les données d’entraînement sont collectées et le moment où le modèle entraîné sur ces données est utilisé pour la prédiction à partir des données réelles.
Une autre cause fréquente de Data Drift est la saisonnalité. Certaines données collectées pendant l’été peuvent fortement différer pendant l’hiver, si la température ou la longueur des journées les impactent par exemple.
De même, les données collectées avant un événement ne seront plus forcément valables après. Par exemple, beaucoup de données collectées avant l’émergence du Covid sont désormais obsolètes. Si un modèle de Machine Learning est entraîné sur ces données et testé sur des données actuelles, un problème de Data Drift surviendra très probablement une fois déployé.
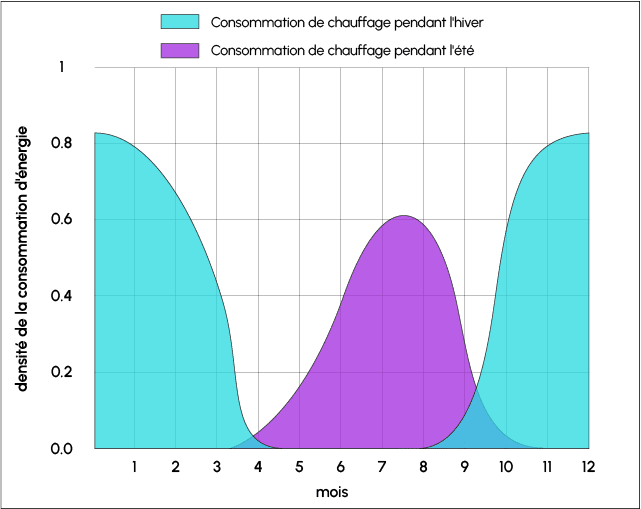
Autre exemple : un modèle de Computer Vision entraîné sur un dataset lié aux routes d’Europe ne sera pas adapté aux routes des États-Unis. Le choix des données d’entraînement est donc extrêmement important.
Quels sont les risques du Data Drift ?
Si un Data Drift n’est pas identifié à temps, les prédictions du modèle seront erronées. Les décisions prises à partir de ces prédictions auront donc un impact négatif.
Par exemple, si vos goûts ont changé et que Netflix n’a pas accès à vos données les plus récentes, son modèle risque de vous suggérer des films qui ne vous plairont pas ou en tous cas plus.
Cet exemple n’est pas très inquiétant, mais les conséquences peuvent être bien plus graves. Par exemple, un trader mal aiguillé à cause d’un Data Drift peut investir des sommes colossales dans une action sans valeur actuelle.
Selon la nature, l’ampleur et le type de Data Drift, les efforts à fournir varient. Il est parfois possible de résoudre le problème en entraînant à nouveau le modèle sur de nouvelles données. Toutefois, il peut aussi être nécessaire de tout recommencer depuis le début.
Outre les données, le modèle lui-même peut aussi dériver. C’est par exemple le cas d’un modèle qui aurait été utilisé avant le Covid pour prédire quels étudiants opteront pour des cours en ligne. En cas d’utilisation pendant la crise du Covid, ce modèle serait totalement inutile. C’est le « Concept Drift ». Ce problème peut être résolu grâce à l’apprentissage en ligne, en entraînant à nouveau le modèle sur chaque observation.
Il est important de construire un processus réutilisable pour identifier le Data Drift. On peut aussi définir des seuils pour le pourcentage de dérive à ne pas dépasser, ou configurer un système d’alerte pour prendre les mesures nécessaires avant qu’il ne soit trop tard.
Le Data Drift peut être détecté à partir de l’évolution des données elles-mêmes, ou lorsque les prédictions du modèle sont incorrectes.
Toutefois, les prédictions incorrectes ne peuvent être identifiées que si une méthode manuelle permettant de trouver la bonne étiquette est disponible.
Comment détecter les Data Drifts ?
Lors du déploiement d’un modèle de Machine Learning, il est important de surveiller régulièrement ses performances. Prenons l’exemple d’un modèle de Computer Vision construit à partir d’un dataset de 100 races de chiens différentes.
Pour vérifier si ses performances diminuent à cause d’un Data Drift, il est nécessaire de passer en revue toutes les nouvelles images et prédictions ingérées par le système de boucle de feedback. Les prédictions doivent ensuite être examinées, éditées ou validées.
En comparant les prédictions initiales et les prédictions éditées, il est possible de vérifier si les performances sont supérieures à la moyenne ou non. Toutefois, pour valider toutes les prédictions en temps réel, il est nécessaire de confier l’accès aux données à de nombreuses personnes. Une large main-d’œuvre est donc nécessaire pour cette opération.
Les Data Drifts peuvent être identifiés en utilisant des méthodes d’analyse séquentielles, des méthodes basées sur modèle, ou des méthodes basées sur la distribution temporelle.
Les méthodes d’analyse séquentielle comme la DDM (Drift Detection Method) ou la EDDM (Early DDM) permettent de détecter la dérive en se basant sur un taux d’erreur fixe.
Une méthode basée sur modèle quant à elle, utilise un modèle de Machine Learning customisé pour identifier la dérive, en déterminant la similarité entre un point ou un groupe de points et une ligne de base de référence.
Il est nécessaire de labelliser en tant que « 0 » les données ayant été utilisées pour construire le modèle actuel en production, et de labelliser en tant que « 1 » les données en temps réel.
On construit ensuite un modèle pour évaluer les résultats. Si le modèle offre une haute exactitude, cela signifie qu’il est capable de discriminer facilement entre les deux jeux de données. On peut en conclure qu’une dérive est survenue, et qu’il est nécessaire de recalibrer le modèle.
En revanche, si la précision du modèle est d’environ 0,5, ceci indique qu’il n’y a pas eu de dérive notable entre les deux jeux de données. On peut donc continuer à utiliser le modèle.
Cette méthode est efficace, mais requiert d’entraîner et de tester le modèle chaque fois que de nouvelles données sont disponibles, ce qui peut s’avérer très coûteux.
Enfin, une méthode basée sur la distribution de fenêtre temporelle prend en compte l’horodatage et l’occurrence des événements. La technique ADWIN (Adaptive Windowing) consiste par exemple à commencer à faire croître dynamiquement la fenêtre W tant qu’il n’y a pas de changement apparent dans le contexte, et à la réduire quand un changement est détecté. L’algorithme ADWIN tente de trouver deux sous-fenêtres présentant des moyennes distinctes, et abandonne la sous-fenêtre la plus ancienne.
Les principales méthodes permettant de calculer la différence entre deux populations sont l’Index de Stabilité de Population, la Divergence de Kullback-Leibler, la Divergence de Jensen-Shannon, le Test de Kolmogorov-Smirnov, ou encore la Distance de Wasserstein.
Qu'est-ce que le Test de Kolmogorov-Smirnov ?
Le Test de Kolmogorov-Smirnov (KS Test) est un test statistique ne nécessitant aucun input de l’utilisateur. Il est utilisé pour comparer les distributions de probabilité continues ou discontinues.
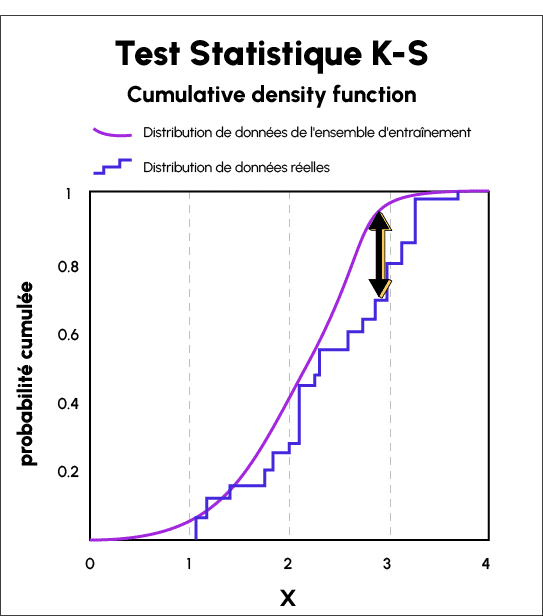
On peut l’appliquer pour comparer la distribution d’un échantillon avec la distribution de probabilité de référence, ou deux échantillons de distributions de populations ayant une variabilité égale, afin de vérifier si elles sont tirées de différentes distributions de population de paramètres inconnus.
Cette méthode tire son nom d’Andrey Kolmogorov et Nikolai Smirnov, qui furent les premiers à proposer son usage pour les très larges tableaux de chiffres aléatoires générés par les humains.
La statistique Kolmogorov-Smirnov est utilisée pour quantifier la distance entre les fonctions de distribution de données du monde réel d’échantillons, et les distributions de données de l’ensemble d’entraînement.
Elle permet d’obtenir une liste de valeurs « p » pour les données d’entraînement et les données du monde réel, et la distance entre les deux courbes révèle le Data Drift.
Comment résoudre un problème de Data Drift ?
Les différentes méthodes évoquées précédemment permettent de détecter rapidement un Data Drift. Par la suite, il est important de prendre des mesures pour résoudre le problème.
Toutefois, plusieurs éléments doivent être pris en compte avant de passer à l’action. Tout d’abord, vérifiez les données de la boucle de feedback. Il est essentiel de ne pas injecter de données détériorées dans le pipeline.
Si la qualité des données est correcte, vérifiez les performances du modèle pour un cas d’usage métier spécifique. Si le modèle est toujours capable de générer des prédictions fiables, vous pouvez envisager d’ajouter un pourcentage de nouvelles données ingérées via la boucle de feedback à l’ensemble de données et d’entraîner à nouveau le modèle. Ceci permet d’obtenir une meilleure représentation de la réalité, tout en conservant le même degré d’exactitude.
Si le modèle ne fonctionne plus comme attendu, cela signifie que les données utilisées pour l’entraînement et la validation n’étaient pas représentatives de la réalité de votre cas d’usage. Il est donc nécessaire de reconstruire un dataset complet avec les nouvelles données ingérées, ou d’attendre d’avoir suffisamment de données pour entraîner à nouveau le modèle.
Data Drift vs Concept Drift : quelle est la différence ?
Un Data Drift survient en cas de décalage entre les données d’entraînement d’un modèle et les données du monde réel. Ce changement dans les données dégrade les performances du modèle.
De son côté, le Concept Drift survient quand la cible des prédictions du modèle ou ses propriétés statistiques changent au fil du temps. Le modèle a appris une fonction cartographiant la variable cible pendant l’entraînement, mais les a oubliés au fil du temps ou est incapable d’utiliser les patterns dans un nouvel environnement.
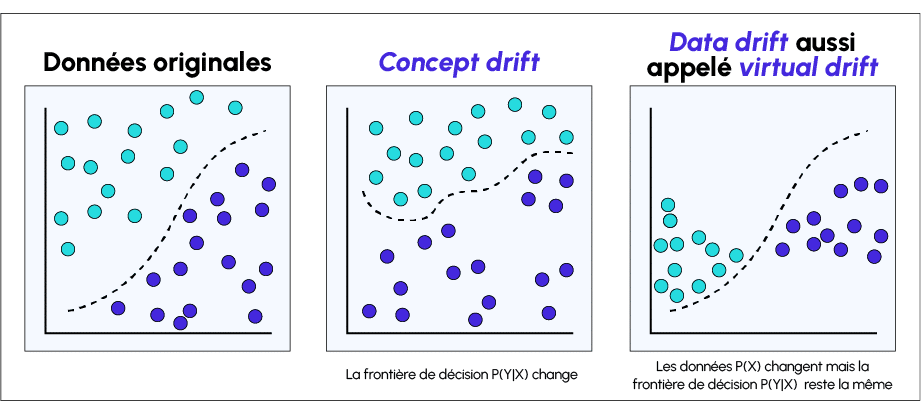
Par exemple, les modèles de détection de spam peuvent avoir besoin d’ajustements si la définition de spam évolue. Le Concept Drift peut survenir de façon saisonnière (comme la mode vestimentaire), soudaine (comme le comportement des consommateurs après la pandémie de Covid) ou progressive.
Pour mesurer le Concept Drift, on peut surveiller continuellement les données d’entraînement et identifier les changements au sein des relations du dataset. Parmi les algorithmes de détection de Concept Drift les plus populaires, on compte ADWIN (ADaptive WINdowing) pour les données en streaming, et le test KS ou le test du khi carré pour les données en batch.
Conclusion
Et voilà, vous savez maintenant d’où provient le data drift, ses causes, ses caractéristiques et les éventuelles solutions à tester pour le résoudre. Le Data Drift et le Concept Drift comptent parmi les problèmes les plus fréquents dans l’entraînement des modèles de Machine Learning.
Afin de devenir expert de ce domaine, vous pouvez choisir DataScientest.
Nos différentes formations permettent de maîtriser la Data Science et le Machine Learning. En choisissant parmi nos programmes, vous pourrez acquérir les compétences requises pour exercer les métiers de Data Analyst, Data Scientist, Data Engineer ou encore Machine Learning Engineer.
À l’issue du parcours, la gestion des datasets et l’entraînement des modèles de Machine Learning n’auront plus de secrets pour vous. Vous serez directement prêt à appliquer vos connaissances en entreprise, à l’instar des 80% de nos alumnis ayant trouvé un emploi immédiatement.
Notre approche Blended Learning innovante combine apprentissage en ligne sur une plateforme coachée et Masterclasses collectives. En outre, vous pouvez choisir entre un BootCamp intensif, une Formation Continue ou une alternance. Toutes nos formations s’effectuent intégralement à distance.
Notre organisme reconnu par l’État est éligible au Compte Personnel de Formation pour le financement, tandis que les demandeurs d’emploi peuvent bénéficier du soutien de Pôle Emploi. N’attendez plus, et découvrez DataScientest !








