
Neural networks are now ubiquitous in the data world, but if there’s one innovative concept that has emerged in recent years, it’s GANs. These networks, which learn by confronting each other, are particularly effective, and if this concept is combined with state-of-the-art image processing techniques, you get what we are going to discuss in this article, DCGANs or Deep Convolutional Generative Adversarial Networks.
What is the GAN concept?
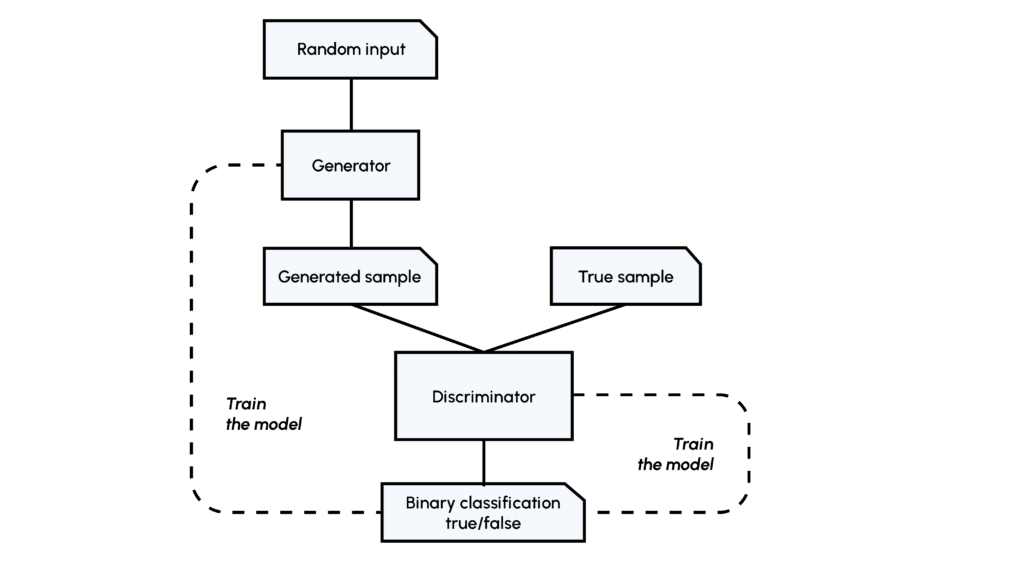
As a reminder, the concept of GANs lies in the confrontation of two networks, the Generator (G) and the Discriminator (D). The Generator learns to generate from scratch a realistic image (similar to those in a dataset) which will be judged by the Discriminator, which has already encountered images in the dataset. If the D network is wrong, then it will have to learn from its mistake, and if the D network is right, then it is the G network that will have to improve.
This method puts us in a supervised classification situation and the learning is done through the loss functions of the two networks, as with traditional networks.
If you’d like to find out more, we have an article on the concept of GANs and their uses.
The limitations of this method were soon revealed: the images generated were not sufficiently realistic, particularly when we tried to increase their quality or sharpness.
This limitation is due to the structure of the Generator and Discriminator networks themselves: simple dense networks (feed-forward or fully connected) do not allow all the specific features of an image to be exploited to the full. To do this, we need to use more complex networks called Convolutional Neural Networks (CNNs or ConvNets).
Before going into the details of DCGAN implementation, it is necessary to understand the key concepts that make up CNNs. If you are unfamiliar with convolution layers, you can read about them in one of our articles.
How do you build a discriminator?
In our DCGAN, the Discriminator network has to establish a classification from a real or false image. It could therefore be reduced to a classic LeNet-type CNN, but the creators of the DCGAN architecture have established that certain specific parameters are more interesting, so let’s take a look at them.
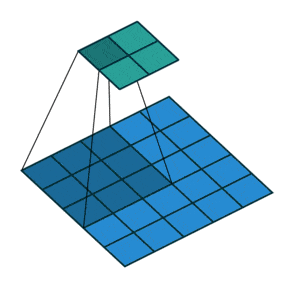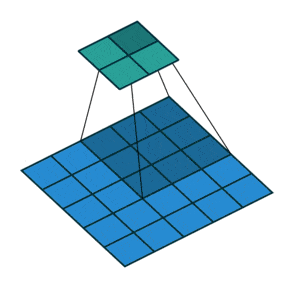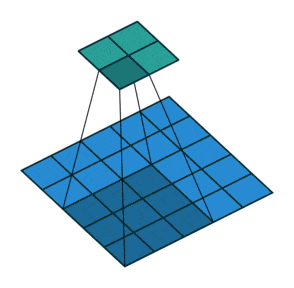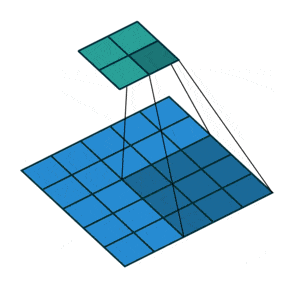
Downsampling: to progressively reduce the size of our convolution layers and avoid overlearning, it is customary to use pooling layers.
Here, convolution layers with stride have proved to be more effective, meaning that the convolution filter will move more than 1 square each time. Here is a representation to help you better understand how they work:
- Batch Normalization: this normalization of the weights after each convolution layer (per stride, in other words) enables the network to be learned more stably and more quickly, so there’s no need to use biases in our various layers!
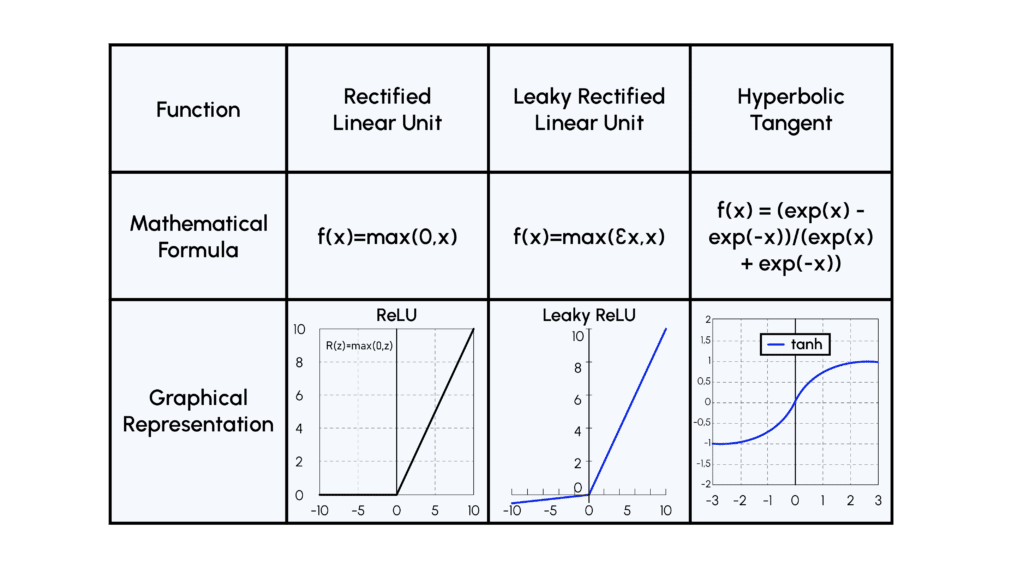
- Activation Function: when training the Discriminator, the ReLU function seemed to converge towards a state where all the weights in the network were inactive, so we use a variant of this function called LeakyReLU.
Generator construction
The role of the Generator network is to go from a random vector to an image capable of fooling the Discriminator, so we need to use new techniques that could be described as an inverted convolutional network:
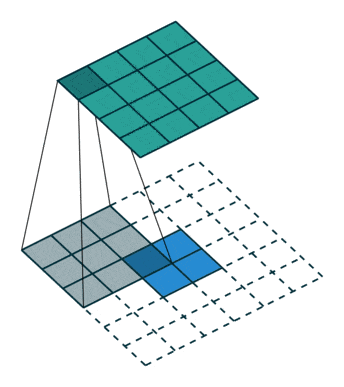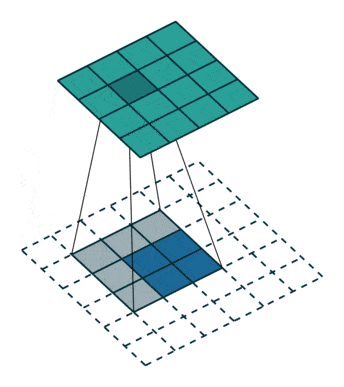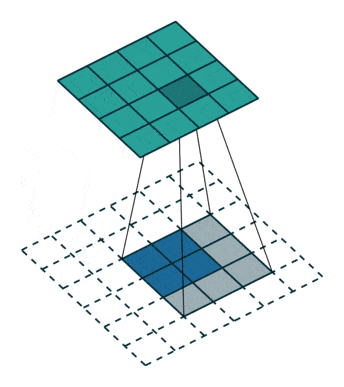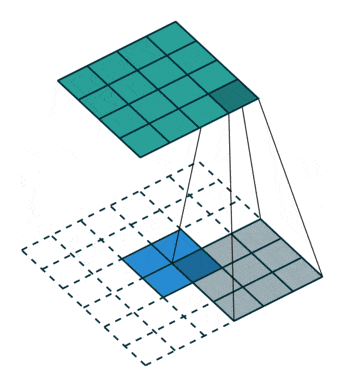
Upsampling: to increase the size of our vector to an image, we need to use what are known as transposed convolutions, as shown below:
- Batch Normalization: the same logic is applied as for the Discriminator
- Activation Function: here we use the ReLU function in all layers except the last, where we use a tanh function, because it’s more efficient to use normalized images as input to the Discriminator!
Here are some illustrations of activation functions:
Par ailleurs, les constructions particulières des Discriminateurs et Générateurs rendent inutiles les couches denses qu’on retrouve habituellement dans les CNNs.
Entraînement ou training loop
Si vous avez bien suivi jusqu’ici vous avez remarqué qu’il y a une étape essentielle dont nous n’avons pas encore parlé, c’est la training loop, ou phase d’entraînement. Si vous êtes déjà familier avec le training des réseaux de neurones vous savez qu’il existe un nombre quasi-infini d’hyperparamètres à
If you’ve been following along so far, you’ll have noticed that there’s one essential stage that we haven’t yet mentioned: the training loop. If you’re already familiar with neural network training, you’ll know that there is an almost infinite number of hyperparameters to test. This problem is logically twice as present with DCGAN training, which is why it is customary to use parameters that have been empirically proven to be effective, particularly by the authors of the paper.
We will simply outline them here:
- Initialization: all the weights are initialized according to a specific Gaussian distribution to avoid convergence problems during training.
- Gradient descent: this is done stochastically on mini-batches, for the same reason as initialisation: it stabilises the training.
- Optimizer: the Adam optimizer is used, which allows continuous updating of the learning rate. Specific parameters for momentum β1 and learning rate initialisation are used to stabilise the training.
Many technical details have been discussed, however these are parameters that are increasingly used in Deep Learning. For example, transposed or stride convolutions are used in many deep learning applications such as image inpainting, semantic segmentation or image super-resolution. Similarly, the Adam optimizer is a very robust optimizer that is ubiquitous in Deep Learning.
The ‘simplicity’ of DCGAN contributes to its success. However, a certain bottleneck has been reached: increasing the complexity of the generator does not necessarily improve image quality. This is why there have been a number of recent improvements: cGANs, styleGANs, cycleGANs and so on.
You can find GANs, DCGANs and the improvements that have since been made to these networks in the “Generative Adversarial Network” module of our Deep Learning for Computer Vision course.








