
Today we take a look at Isolation Forest, a Machine Learning algorithm designed to solve binary classification problems such as fraud detection or disease diagnosis. This technique, presented at the Eighth IEEE International Conference in 2008, is the first classification technique dedicated to anomaly detection based on isolation.
The problem of the Accuracy Paradox
When faced with a class classification problem in Machine Learning, it sometimes happens that the dataset is unbalanced. Specifically, there is a much higher proportion of one class than the other in the training sample. This problem is a frequent feature of binary classification problems. At first glance, one might think of applying a classic classification algorithm, such as the decision trees, K-NN or SVM presented on our blog. However, in reality, these algorithms are unable to handle these atypical datasets where the disparities between classes are quite high. They tend to maximise quantities such as accuracy through their loss function, but without taking the distribution of the data into account.
In practice, this results in models which, when trained on a dataset dominated by one class, will report a high rate of correct predictions, called “accuracy”, during the evaluation phase, but will not be relevant in practice.
Let’s take an example to illustrate this paradox. Consider a bank fraud detection problem. A bank is trying to determine which of a large number of transactions are fraudulent, based on a certain number of explanatory variables. These fraudulent transactions represent around 11% of the transactions in our dataset. Classification using a simple model such as SVM using scikit learn gives, for example, the following score :
However, if we take a look at the confusion matrix, we soon notice that the algorithm’s behaviour is rather naive:

In fact, out of 219 fraudulent transactions, only 25 were identified as fraudulent by our model. This shows that the predictive power of the model is not as strong as accuracy might suggest. It is a metric that is overly biased by an imbalance of classes, a phenomenon known as the accuracy paradox.
A model with a higher accuracy score may have less predictive power than a model with a lower accuracy score.
What is Isolation Forest?
So how do you deal with this problem, which ruins the efforts of many well-trained classical algorithms? There are several solutions, such as resampling methods like undersampling or oversampling, which randomly select data in order to balance the class ratio.
However, when these methods are not effective enough, it is customary to rethink the problem and consider anomaly detection as an unsupervised classification problem. This is where the long-awaited Isolation Forest comes in!
In Isolation Forest, we find Isolation because it is an anomaly detection technique that directly identifies anomalies (commonly known as ‘outliers’), unlike the usual techniques that discriminate points against a global ‘standardised’ profile.
The principle of this algorithm is very simple:
- A feature is selected at random.
- The dataset is then randomly partitioned according to this variable to obtain two subsets of the data.
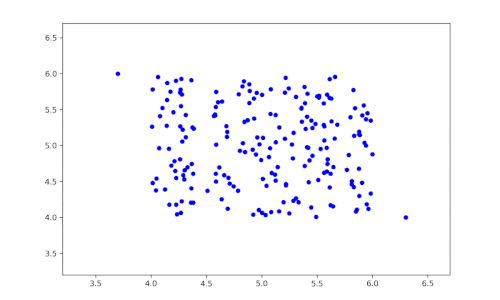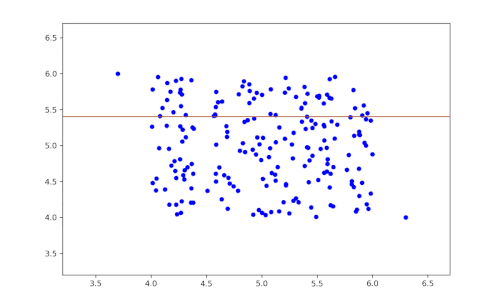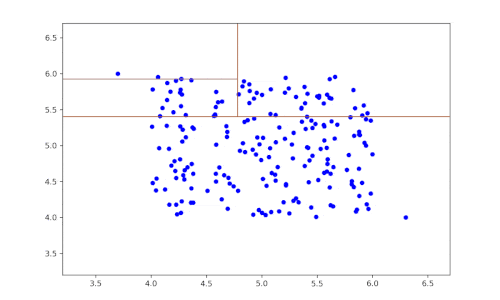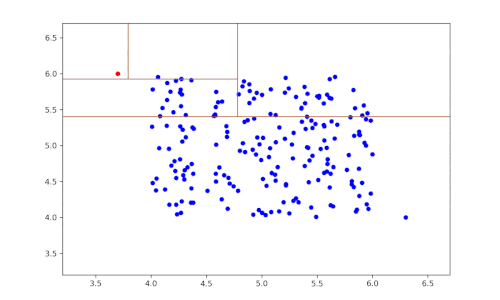
- The previous two steps are repeated until a dataset is isolated.
- The previous steps are repeated recursively.
In the same way as ensemblistic algorithms such as Random Forest, we create a forest (hence the name Isolation Forest) made up of dozens or hundreds of trees whose results we combine to obtain a better result.
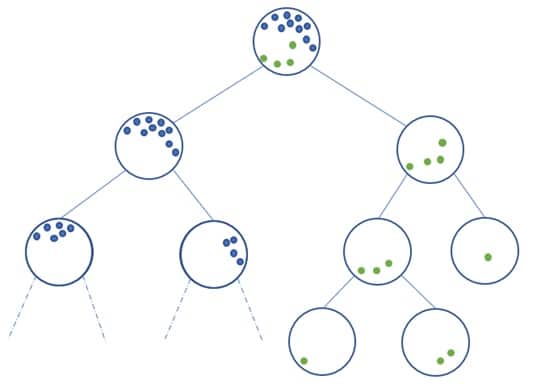
So how do you get the result on a tree? In other words, how do you define whether a point is an anomaly or not?
The construction of the algorithm gives rise to a tree structure, the nodes of which are the sets partitioned during the algorithm’s stages and the leaves of which are the isolated points. Intuitively, anomalies will tend to be the leaves closest to the root of the tree.
Depending on the distance to the root, an anomaly score is assigned to each leaf of a tree, and this anomaly score is averaged over all the trees that have been constructed recursively, to give a final result. Depending on the situation, parameters such as the number of trees or the proportion of anomalies to be considered can then be adjusted to obtain a more robust result.
The Isolation Forest is highly appreciated for its ability to detect anomalies in an unsupervised way, while obtaining satisfactory results in many fields. Applications can be found in banking fraud, medical diagnostics and structural fault analysis.
If you want to find out more, take a look at our Data Scientist, Data Analyst and Data Engineer training courses.








