
Il est facile d'oublier tout ce que l'on sait du monde : on sait qu'il est composé d'environnements en 3D, d'objets qui bougent, entrent en collision, interagissent ; de personnes qui marchent, parlent et pensent ; d'écrans qui affichent des informations codées en langage sur la météo, le vainqueur d'un match de basket ou ce qui s'est passé dans le football dans le passé. Les modèles génératifs peuvent être très utiles pour exploiter ces données.
Cette énorme quantité d’informations existe et est, dans une large mesure, facilement accessible, que ce soit dans le monde physique des atomes ou dans le monde numérique des bits. La seule difficulté consiste à développer des modèles et des algorithmes capables d’analyser et de comprendre ce trésor de données.
Qu’est ce qu’un modèle génératif ?
Il existe deux types de modèles : les modèles discriminants et génératifs. Les modèles génératifs et discriminants sont deux approches différentes qui sont largement étudiées dans la tâche de classification. Ils suivent un itinéraire différent les uns des autres pour atteindre le résultat final. Les modèles discriminants sont très populaires et sont utilisés de manière plus comparative pour effectuer la tâche car ils donnent de meilleurs résultats lorsqu’ils sont fournis avec une bonne quantité de données.
Modèle discriminant
La tâche d’un modèle discriminant est simple, si on lui montre des données de différentes classes, il devrait être capable de les discriminer.
Par exemple, si je montre au modèle un ensemble d’ images de chien et de chat, il devrait pouvoir dire ce qu’est un chien et ce qu’est un chat en utilisant des caractéristiques discriminantes telles que la forme des yeux, la taille des oreilles, etc.
Modèle génératif
Le modèle génératif, quant à lui, a une tâche beaucoup plus complexe à accomplir. Il doit comprendre la distribution à partir de laquelle les données sont obtenues et doit ensuite utiliser cette compréhension pour effectuer la tâche de classification. Les modèles génératifs ont également la capacité de créer des données similaires aux données d’apprentissage qu’ils ont reçues, car ils ont appris la distribution à partir de laquelle les données sont fournies. Par exemple, si je montre à un modèle génératif un ensemble d’images de chiens et de chats, le modèle doit maintenant comprendre complètement quelles sont les caractéristiques qui appartiennent à une certaine classe et comment elles peuvent être utilisées pour générer des images similaires.
En utilisant ces informations, il peut faire plusieurs choses. Il peut comparer les attributs pour classer l’image de la même manière que l’algorithme discriminant peut classer une image. Cela peut générer une nouvelle image qui ressemble à l’une des images de classe qui lui ont été fournies pour la formation.
Les modèles génératifs constituent l’une des approches les plus prometteuses pour atteindre cet objectif. Pour former un modèle génératif, il faut commencer par collecter une grande quantité de données dans un domaine donné (pensez à des millions d’images, de phrases, de sons, etc.), puis former un modèle pour générer des données similaires.
Un exemple pour comprendre les modèles génératifs
Rendons cela plus concret à l’aide d’un exemple. Supposons que nous disposions d’une grande collection d’images, comme les 1,2 million d’images de l’ensemble de données ImageNet (mais n’oubliez pas qu’il pourrait s’agir d’une grande collection d’images ou de vidéos provenant d’Internet). Si nous redimensionnons chaque image pour qu’elle ait une largeur et une hauteur de 256 (comme cela se fait couramment), notre ensemble de données est un grand bloc de pixels de 1 200 000x256x256x3 (environ 200 Go). Voici quelques exemples d’images tirées de cet ensemble de données :

Ces images sont des exemples de ce à quoi ressemble notre monde visuel et nous les appelons des « échantillons de la vraie distribution de données ». Nous construisons maintenant notre modèle génératif que nous souhaitons entraîner à générer des images comme celles-ci à partir de zéro. Concrètement, un modèle génératif dans ce cas pourrait être un grand réseau neuronal qui produit des images, que nous appelons « échantillons du modèle ».
Pour avoir un aperçu du résultat, ce site crée des visages de façon aléatoire, grâce à l’IA, qui n’existent pas dans la réalité.
A présent, nous allons discuter de deux algorithmes génératifs célèbres, les autoencodeurs variationnels (ou vae) et les réseaux antagonistes génératifs.
Entraînement d'un modèle génératif
GANs
Supposons que nous utilisions un réseau nouvellement initialisé pour générer 200 images, en commençant chaque fois par un code aléatoire différent. La question est la suivante : comment ajuster les paramètres du réseau pour l’encourager à produire des échantillons légèrement plus crédibles à l’avenir ? Notez que nous ne sommes pas dans un cadre supervisé simple et que nous n’avons pas d’objectifs explicites pour nos 200 images générées ; nous voulons simplement qu’elles aient l’air réelles. Une façon intelligente de contourner ce problème consiste à suivre l’approche du réseau adversarial génératif : GAN.
Dans ce cas, nous introduisons un second réseau discriminant (généralement un réseau neuronal convolutif standard) qui tente de déterminer si une image d’entrée est réelle ou générée. Par exemple, nous pouvons introduire les 200 images générées et les 200 images réelles dans le discriminateur et l’entraîner comme un classificateur standard à distinguer les deux sources. Mais en plus de cela – et c’est là que réside l’astuce – nous pouvons également effectuer une rétropropagation à travers le discriminateur et le générateur pour trouver comment modifier les paramètres du générateur afin que ses 200 échantillons soient légèrement plus déroutants pour le discriminateur.
Ces deux réseaux sont donc engagés dans une bataille : le discriminateur essaie de distinguer les vraies images des fausses et le générateur essaie de créer des images qui font croire au discriminateur qu’elles sont réelles. En fin de compte, le réseau du générateur produit des images qui sont impossibles à distinguer des images réelles pour le discriminateur.
Pour plus d’informations sur les GANs, lisez cet article.
Autoencodeur
Un autocendoeur est un type de réseau de neurones utilisé pour apprendre des reprénsentations des jeux de données de manière non supervisée. Le but d’un autoencodeur est d’apprendre une représentation (encodage) pour un ensemble de données, typiquement pour la réduction de dimensionnalité.
En tant qu’humains, nous sommes capables de visualiser les choses en utilisant peu d’attributs. Par exemple, si nous décrivons un humain comme grand, blond, volumineux, sans moustache on peut créer une visualisation basée sur ces attributs. Si nous montrons une image d’une personne, un humain est capable d’apprendre tous les attributs (appelés attributs latents) tels que ceux ci-dessus nécessaires pour identifier la personne, puis peut les utiliser pour visualiser et/ou reconstruire la personne.
L’encodeur est similaire à n’importe quel réseau de neurones de classification sans la couche softmax de prédiction. Dans la figure ci-dessous du réseau, si nous supprimons la couche softmax finale, les 1000 valeurs finales que nous obtenons peuvent être considérées comme 1000 attributs latents d’une image.
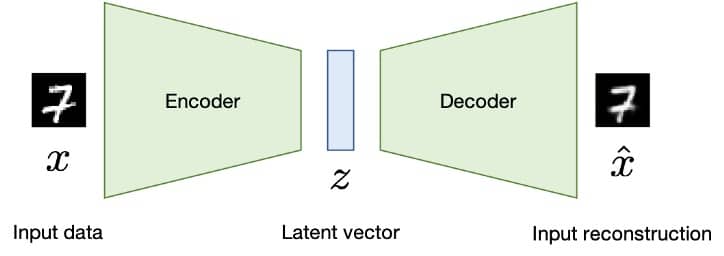
Le décodeur est l’opposé de l’encodeur, il prend les attributs latents de la sortie de l’encodeur et essaie de reconstruire l’image. Cela se fait à l’aide de couches de déconvolution qui peuvent déséchantillonner l’entrée.
Le goulot d’étranglement est le vecteur latent émis par le codeur (le vecteur z dans l’image) et suréchantillonné par le décodeur. Il contient les attributs latents produits par le décodeur tels que la taille, le poids, etc. décrits ci-dessus.
Le réseau d’encodeur et de décodeur est entraîné ensemble en utilisant la rétropropagation pour réduire la perte de reconstruction telle que l’erreur quadratique moyenne entre les pixels.
Un autre exemple concret pour illustrer l’utilité de la vae :
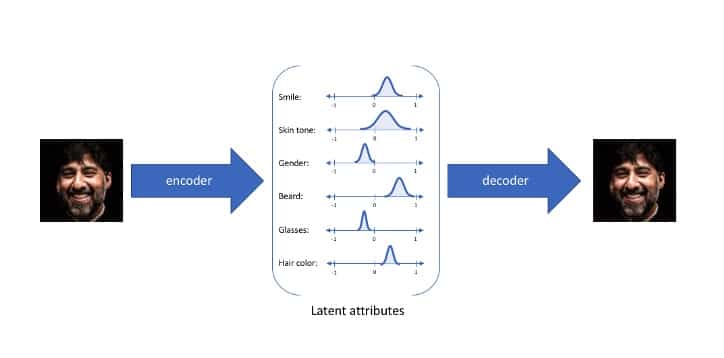
En utilisant les attributs latents, ce réseau est capable de générer une image en respectant à la lettre les attributs donnés.
La Data Science peut devenir un formidable outil de création et d’imagination. Les premières applications se sont surtout développées autour de la création d’images, mais les possibilités de cette nouvelle technologie restent très nombreuses.
Cet article vous a-t-il plus ? Si vous voulez en apprendre plus sur la computer vision et l’intelligence artificielle appliquée aux images : découvrez l’une de nos formations.









