
Le 23 février 2021, Alexandre Laloo, data product manager chez sennder, a présenté un webinar à notre communauté au sujet de l’utilisation de la data en startup.
Replay du Webinar
Alexandre Laloo et sennder
Diplômé d’une grande école de commerce, Alexandre Laloo a rejoint Everoad en 2017 lorsque l’entreprise ne comptait qu’une vingtaine de salariés. Cette startup, spécialisée dans la digitalisation du transport routier de marchandises, a fusionné en 2020 avec sennder, son concurrent allemand. L’entreprise, qui a gardé le nom de marque de sennder, compte aujourd’hui plus de 700 salariés et a levé plus de 260 millions d’euros. Alexandre a ainsi été témoin de la croissance de l’entreprise et de l’évolution de son approche vis-à-vis des données.
Initialement operation manager, son rôle était d’analyser l’activité de l’entreprise grâce aux données qu’elle récoltait. Son poste actuel de data product manager consiste à diriger la road map analytics, c’est-à-dire assurer une bonne diffusion de la donnée au sein de l’entreprise.
Le traitement des datas en startup
1. Le rapport de l’entreprise aux données dépend de son marché
Le terme « startup » est très utilisé dans l’actualité et englobe des typologies d’entreprise très différentes. On ne peut ainsi pas généraliser sur l’utilisation des datas dans ces organisations, car elles sont traitées pour répondre à des problématiques propres à chaque secteur. Dans certains domaines, comme le gaming ou la travel tech, les données sont une priorité dès le lancement, car l’entreprise en a besoin pour comprendre son marché et son produit. Dans d’autres secteurs, le besoin en Data Analysts ou Machine Learning Engineers est moins important au début de leur activité. Par exemple sennder n’a pas engagé de Machine Learning Engineer dans ses 3 premières années d’existence.
Le marché de chaque startup va ainsi déterminer ses besoins en data, c’est-à-dire la part du budget alloué à la donnée pour d’une part recruter des experts (Product Managers, Data Analysts, Data Scientists ou Data Engineers) et d’autre part pour s’équiper d’outils d’analyse et de traitement puissants. En effet, l’intégration d’un cloud d’entreprise représente un investissement conséquent.
La priorité de la data pour une startup va dépendre de plusieurs critères :
- La nature du produit : application mobile, site web, produit physique, etc.
- Le marché : transport, agroalimentaire, finance, etc.
- Le volume de données disponibles
- La culture data de l’entreprise : même si la data devient indispensable à un certain niveau de croissance, l’investissement va également dépendre de ce facteur
2. Cycles de financement des statups
Au-delà du marché sur lequel évolue l’entreprise, sa maturité, que l’on peut évaluer grâce aux cycles de financement, va également déterminer sa manière d’appréhender ses données.
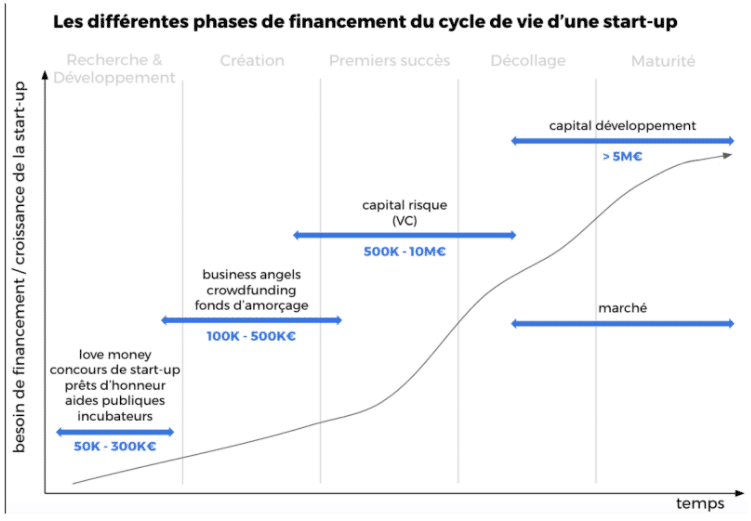
Alexandre nous propose un tableau prenant en compte le marché d’une part et la maturité de l’entreprise d’autre part, pour évaluer le besoin en data et l’ampleur de l’investissement consacré aux datas.
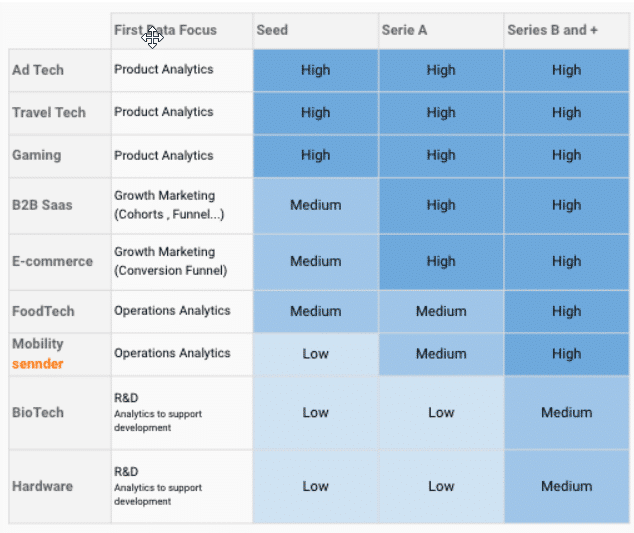
Par exemple, pour un site e-commerce, le besoin est « intermédiaire » car sa priorité est d’investir en digital marketing pour se lancer. Sa stratégie data va se concentrer sur l’analyse des campagnes marketing et de leur performance (calcul du ROI par exemple).
L’évolution des outils : des spreadsheets au data warehouse
Cette partie présente l’évolution des problématiques et des outils utilisés par Everoad et Sander de 2017 à aujourd’hui. Au début de son activité, le volume de données collecté par Everoad était relativement faible et la priorité de l’entreprise n’était pas d’analyser des données mais de développer son activité de transport routier de marchandises.
Aujourd’hui, le Machine Learning représente un investissement important pour sennder, notamment pour optimiser les trajets des transporteurs et proposer un pricing intelligent. Ce changement d’approche vis-à-vis des données a été progressif et cette partie décrit les étapes qui ont conduit l’entreprise à son niveau actuel d’expertise.
- Etape 0 : Fichiers Google Sheets
En 2017, Everoad était au début de son activité et n’avait pas encore fait sa serie A. L’entreprise utilisait un bot simple sur Slack pour récupérer quotidiennement un fichier csv qui donnait les informations sur l’activité de la veille, il n’y avait pas de visualisation, pas de collecte en temps réel. La collecte d’informations permettait d’avoir une compréhension basique des opérations de transport effectuées ce qui était suffisant à stade de croissance.
Cette solution ne permettait pas aux utilisateurs de travailler en autonomie, il fallait solliciter l’équipe technique au moindre besoin.
- Étape 1 : Activation du levier de distribution de la donnée
L’objectif suivant est de répondre à la problématique de distribution des données dans les outils de reporting. Cette étape repose sur Google sheets qui permet de faire des scripts pour envoyer des données automatiquement d’un fichier à un autre.
À cette étape, Everoad n’avait pas encore engagé d’experts en data, Alexandre était operation manager, son rôle était d’analyser l’activité et d’avoir une vue d’ensemble des opérations. La Data n’était pas encore une priorité jusqu’à un certain stade auquel le système de spreadsheets n’était pas suffisant au vu du volume croissant de données à traiter.
Ce système était fonctionnel et permettait de répondre aux besoins de reporting les plus élémentaires mais il se basait sur une seule source de données et permettait de voir ces données sous un seul angle d’analyse.
- Étape 2 : Outil de requêtes sur les bases de données
La prochaine étape concerne la mise en place d’un outil pour effectuer des requêtes sur différentes bases de données et fournir différents angles d’analyse. Everoad a opté pour Redash (depuis racheté par Databricks) pour exécuter ces requêtes et pour envoyer des données dans des google sheets différents.
Cet outil permettait d’extraire de la valeur de plusieurs sources de données, d’effectuer des requêtes plus flexibles et d’être plus autonome par rapport à l’équipe technique, qui était malgré tout indispensable aux processus mis en place. Les données étaient actualisées automatiquement toutes les 2/3h.
Un Data Analyst a rejoint l’équipe et différents reportings étaient produits (commerciaux et opérationnels). Ce fonctionnement a duré 8 mois avant de devenir trop fragile face à la croissance d’Everoad.
- Étape 3 : Data Warehouse
L’étape 3 consiste à l’intégration de Airflow et Big Query pour gérer les couches de données : le stockage, le traitement et le partage des données aux utilisateurs. Cette étape constitue un tournant dans le traitement des données pour Everoad qui a recruté trois Data Analysts et un Data Engineer, ce qui témoigne de l’intérêt de l’entreprise pour ses données.
L’équipe data pouvait alors faire de la modélisation et du data modeling sur ses bases de données. Les reportings étaient automatisés et des analyses produit pouvaient être produites.
Cependant, aucune plateforme analytique de visualisation n’avait été mise en place et les outils de business intelligence étaient fragiles, l’entreprise utilisait encore des spreadsheets et Google data studio. Les équipes ne traitaient pas encore les problématiques de gouvernance, c’est-à-dire la gestion des accès aux données et leur distribution au sein de l’entreprise. Cette étape a duré deux ans jusqu’à la fusion avec sennder.
- Étape 4 : Gouvernance, Data mart et Data Library
Après avoir rejoint sennder, l’entreprise a recruté 4 data engineers et sa stack d’outils a beaucoup évolué. La gouvernance des données a été mise en place avec Looker, le flux données arrive en temps réel et est directement exploitable. Les bases de données sont automatiquement actualisées toutes les 30 minutes.
L’équipe data couvre 100% du business : tous les départements obtiennent des rapports analytiques sur leurs activités avec des KPIs qui les concernent, ainsi 600 utilisateurs consomment de la donnée au sein de l’entreprise.
L’entreprise possède un Data mart (ou magasin de données) qui permet de définir qui a besoin de quelles données et comment les distribuer. Des modules de training ont également été mis en place pour permettre aux utilisateurs de monter en compétence.
Les process data à suivre ont été définis, avec des « best practices » et une data library pour documenter ce qui est fait avec la data, toujours dans l’optique de servir 3 types de users : business user, product user, data team user.
Conclusion
L’exploitation des données collectées est désormais indispensable en entreprise et constitue un levier de croissance considérable. Cependant, le niveau de priorité du traitement des datas dépend d’une part du secteur d’activité et d’autre part de la maturité de l’entreprise. Ainsi, selon les startups, l’intérêt porté aux données intervient plus ou moins tôt dans leur croissance comme le montrent les étapes décrites par Alexandre pour Everoad et sennder.
Dans ce webinar, Alexandre Laloo nous a montré qu’on peut s’intéresser aux datas, commencer à intégrer des bases de données et fournir des premières analyses basiques sans budget, avec des outils gratuits ou en freemiums. Le processus qui a conduit sennder jusqu’à son fonctionnement actuel a été progressif et a toujours répondu aux besoins provoqués par sa croissance. C’est un message encourageant pour les startups dont la data n’a pas de place dans leur budget, car un traitement simple de leurs données peut leur permettre d’optimiser leurs produits et services sans demander beaucoup de ressources.
DataScientest remercie vivement Alexandre Laloo pour son temps et la qualité de sa présentation lors de ce webinar qui nous a montré que l’utilisation des data sciences concerne désormais tous les secteurs d’activité, de la finance à l’agroalimentaire en passant par le transport routier de marchandises.
Vous êtes une start-up et cherchez à exploiter vos données ? DataScientest le fait gratuitement pour vous !







