À l’ère du Big Data, plusieurs métiers ont émergé, notamment celui du Data Scientist.
Si vous n’en avez jamais entendu parler alors je vous recommande d’aller lire cet article en premier, mais pour ceux qui savent déjà ce que fait le Data Scientist nous allons nous intéresser au panel d’outils qu’il utilise.
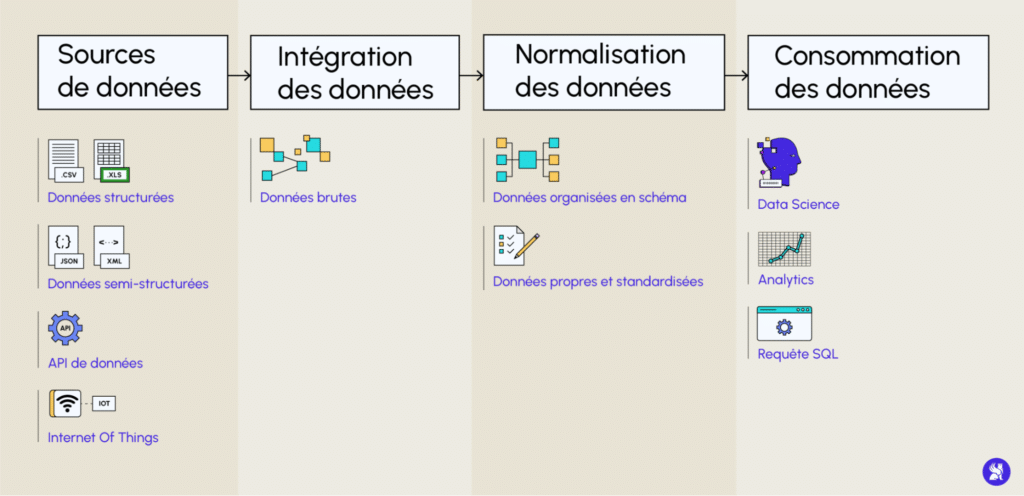
Partons de ce schéma, pour avoir les différentes étapes que traversent la donnée. Le Data Scientist va surtout intervenir dans la dernière étape. Nous allons évoquer les outils utilisés dans ces étapes mais ils peuvent différer selon les entreprises.
Récupération de la donnée
La première étape consiste à récolter les données à travers des sources de données. Il est commun de retrouver ici le langage phare de la Data Science : Python pour collecter cette donnée. Il est tout à fait possible aussi de faire du webscraping pour récupérer des données depuis des pages web via Selenium.
Vous pouvez aussi interroger des données d’entreprise via le langage SQL
Outils utilisés :
Qu'est-ce que la Visualisation ? Un des outils du data scientist
La visualisation des données permet de découvrir des informations dissimulées dans vos données et de découvrir des tendances au sein de votre jeu de données. Matplotlib,Seaborn sont des outils quotidiens du Data Scientist. La visualisation permet en un seul coup d’œil de donner un sens à vos données. C’est un moyen rapide d’obtenir des informations à travers l’exploration visuelle, des rapports fiables et un partage d’informations. Toutes catégories d’utilisateurs peuvent ainsi donner un sens au nombre croissant de données de votre entreprise. Grâce à la visualisation, le cerveau parvient à traiter, absorber et interpréter de grandes quantités d’informations.
Outils utilisés :
Analyse de données / Preprocessing
Le traitement des données est généralement effectué par un data scientist (ou une équipe de data scientists). Il est important qu’il soit effectué correctement afin de ne pas impacter négativement les étapes suivantes.
Lorsqu’il travaille avec des données brutes, le data scientist les convertit sous une forme plus lisible en leur donnant le format et contexte nécessaires pour qu’elles puissent être interprétées et utilisées par des modèles de Machine Learning ou Deep Learning.
Bien que l’on puisse naïvement penser qu’il suffit d’un grand nombre de données pour avoir un algorithme performant, les données dont nous disposons sont la plupart du temps non adaptées et il faut les traiter préalablement pour pouvoir ensuite les utiliser : c’est l’étape de preprocessing.
Outils utilisés :
Modeling
La modélisation constitue une manière de modéliser des phénomènes, dans le but de prendre des décisions stratégiques.
Modéliser signifie représenter le comportement d’un phénomène, afin de pouvoir aider à la résolution d’un problème concret de l’entreprise.
En machine learning, l’algorithme se construit sur une « représentation interne » afin de pouvoir effectuer la tâche qui lui est demandée (prédiction, identification, etc.). Pour cela, il va d’abord falloir entrer un jeu de données d’exemples afin qu’il puisse s’entraîner et s’améliorer, d’où le mot apprentissage. Ce jeu de données s’appelle le training set. On peut appeler une entrée dans le jeu de données une instance ou une observation.
Il y a donc deux façons possibles de modéliser :
Pour analyser et expliquer
Pour prédire
Ces deux dimensions peuvent être présentes dans des proportions variables : ce n’est pas uniquement l’une ou l’autre. Mais il y a une tension entre elles : les modèles les plus prédictifs ne sont généralement pas les plus explicatifs, et réciproquement.
Outils utilisés :
Déploiement (MLOps)
MLOps est l’acronyme de Machine Learning Operations. La définition de MLOps est un ensemble de pratiques et d’outils qui relèvent du domaine de la Data. C’est une spécialisation du métier de Data Scientist
ML pour Machine Learning
Ops pour Operations
Le développement des méthodes MLOps répond aux besoins croissants des entreprises pour mener des projets data, en adoptant des méthodes efficaces pour le développement, le déploiement et le contrôle d’un système de Machine Learning.
Les outils et pratiques de Machine Learning Operations servent avant tout à augmenter la productivité de l’entreprise en rendant exploitables un maximum de projets grâce à la data. En effet, le MLOps permet d’optimiser chaque mise en production, en facilitant la transition entre le mode concept et le projet réel. Il surveille et actualise en continu le procédé à suivre en fonction des nouvelles données. On parle destratégie “data-driven”.
Le MLOps est surtout une culture à développer. Une culture qui capitalise sur la faculté d’automatiser et d’agir sur tout le cycle de vie d’un modèle.
Outils utilisés :
Conclusion :
Si vous voulez apprendre à utiliser l’ensemble des outils que vous venez de voir, n’hésitez pas à consulter le détail de la formation Data Scientist chez DataScientest.