
L’une des étapes les plus importantes d’un projet en Data Science, avant d’entamer la conception des modèles de Machine Learning, est le nettoyage de notre jeu de données. Cela implique la suppression des doublons, l’encodage de certaines variables, mais aussi et surtout le remplacement des valeurs manquantes.
Il n’est en effet pas rare que le jeu de données que nous manipulons ne soit pas entièrement complet, et qu’il contienne des valeurs manquantes appelées « NaN ». Ces valeurs, si elles ne sont pas supprimées ou remplacées par diverses techniques, peuvent altérer la performance de nos modèles.
C’est ici qu’intervient Missingno !
Outre le nom d’un célèbre Pokémon bug, Missingno est une librairie Python de « missing data visualization » vous permettant de mieux comprendre et analyser les valeurs manquantes de votre jeu de données ! Cette librairie développée par Aleksey « ResidentMario » Bilogur est disponible en accès libre sur son repository Github et est bien évidemment compatible avec le module Pandas.
Comme toutes les librairies, Missingno s’installe avec la commande pip install missingo, puis s’importe dans un programme Python avec import missingo as msno.
Voyons ensemble les quatre types de visualisation réalisables grâce à Missingno !
Le diagramme en barres (bar chart)
Le diagramme en barres proposé sur Missingno se trace avec la fonction msno.bar(df) et se présente comme suit :
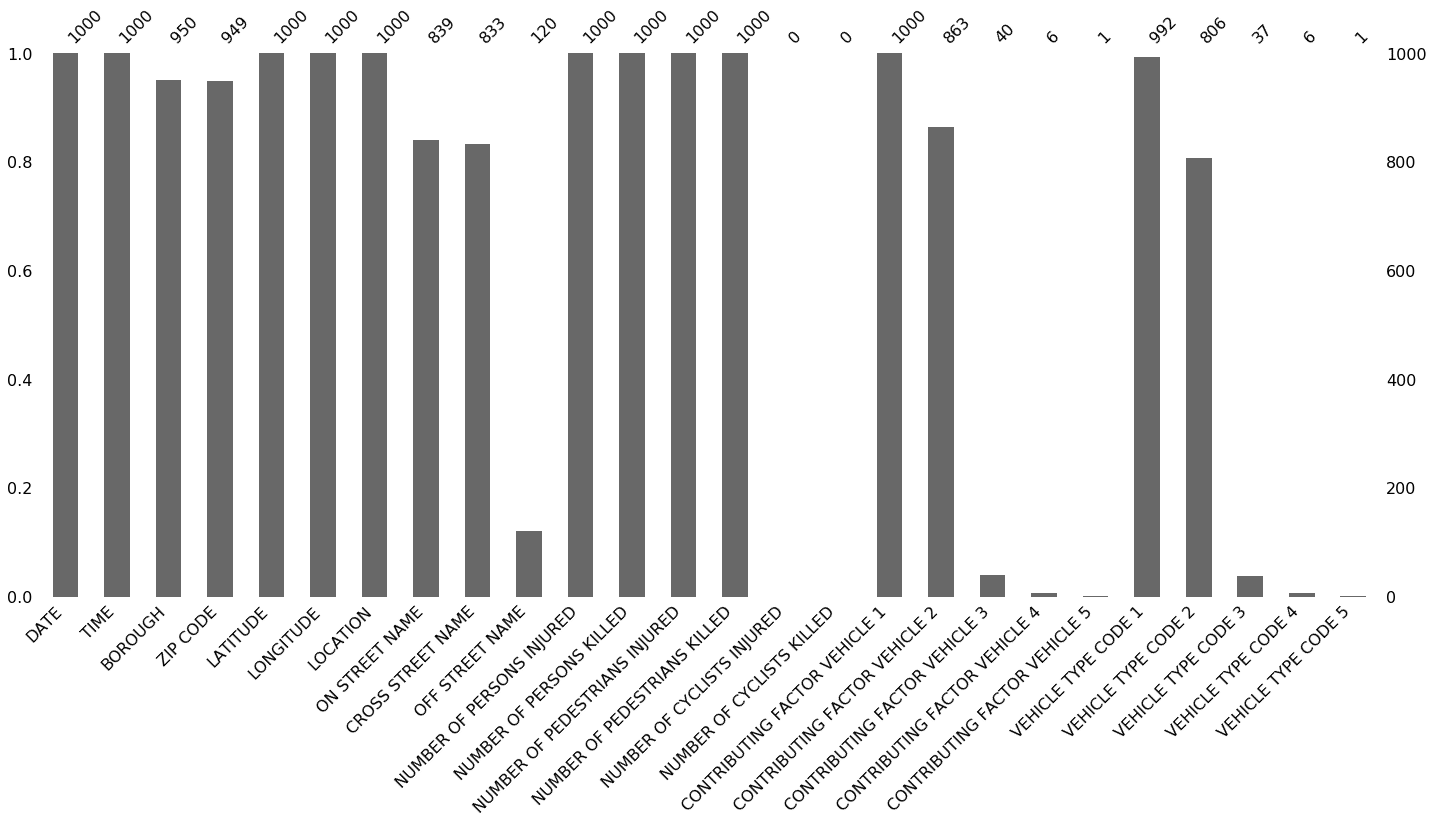
Dans ce graphique, chaque barre symbolise une colonne du jeu de données, et leur hauteur correspond au taux de valeurs non nulles dans chaque colonne. Nous avons à gauche le pourcentage de valeurs complètes, à droite les valeurs des index, et en haut le nombre de lignes.
Pour ce jeu de données par exemple, les colonnes DATE, TIME ou NUMBERS OF PERSONS INJURED ne contiennent aucunes valeurs manquantes. Inversement, la colonne OFF STREET NAME ne contient que très peu de valeurs, tandis que NUMBER OF CYCLISTS INJURED / KILLED en sont totalement dénuées.
La matrice de nullité
La matrice de nullité, ou « nullity matrix », se trace avec la fonction msno.matrix(df) :

Cette matrice s’interprète presque comme le premier histogramme plus haut : pour chaque colonne, plus la case est grisée, plus elle contient de valeurs non nulles. Inversement, la présence de barres blanches, plus ou moins importantes, symbolise l’absence de valeurs.
On retrouve également, à droite de la matrice, une fine courbe qui oscille de gauche à droite, la droite étant le nombre de colonnes du jeu de données, et la gauche étant donc à zéro. Ainsi, pour une ligne donnée, lorsqu’elle comporte une valeur dans chaque colonne, la courbe penchera vers la droite. Sinon, si les valeurs commencent à manquer, elle penchera vers la gauche.
La matrice de corrélation (heatmap)
À l’instar de Seaborn, la matrice de corrélation de Missingno se trace avec msno.heatmap(df) :
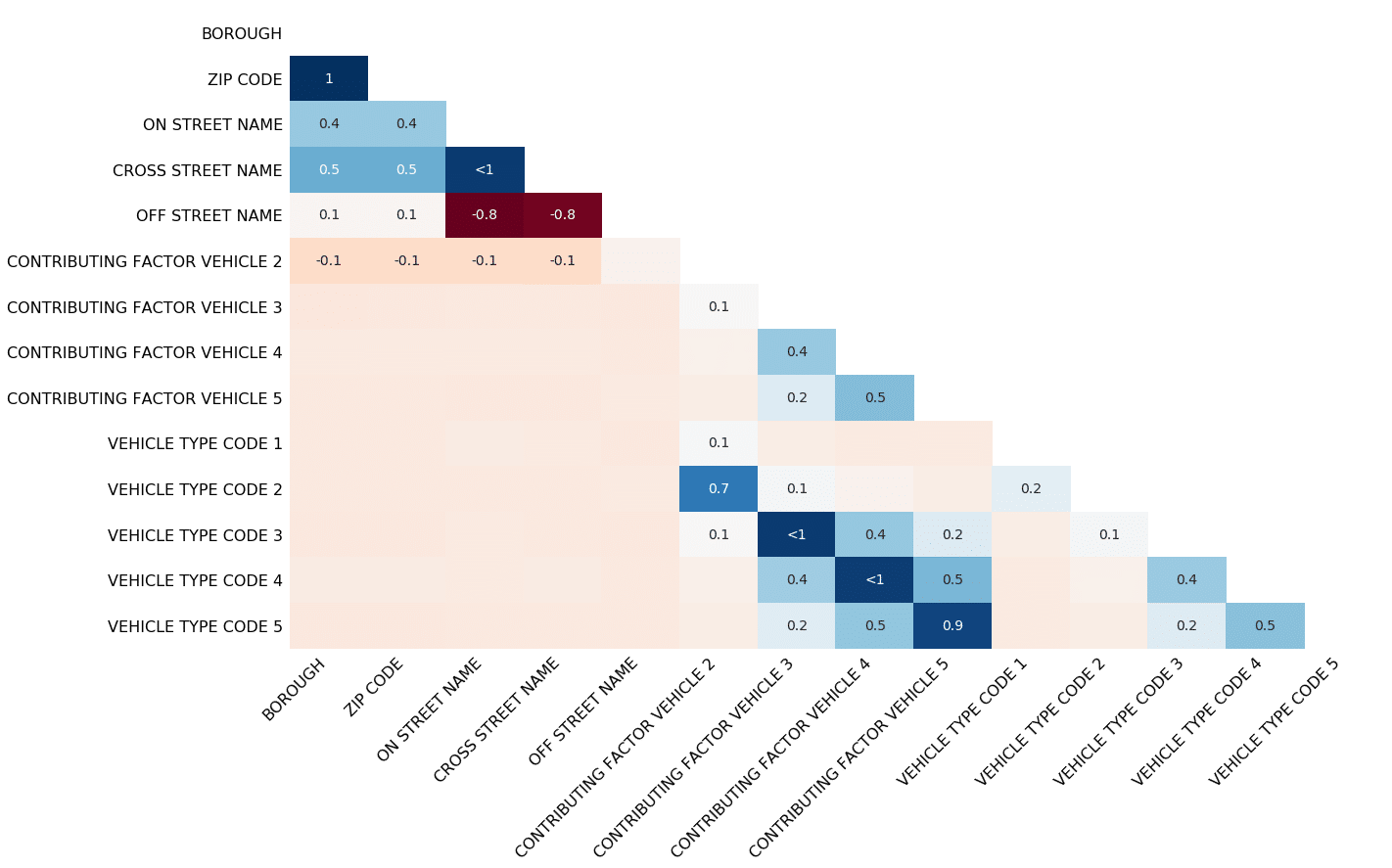
Les valeurs de la matrice de corrélation, aussi appelées « corrélations de nullité » ou « nullity correlations », sont comprises entre -1 et 1 :
- Une valeur proche de -1 signifie que si une variable apparaît, il est très probable que l’autre variable soit manquante.
- Une valeur proche de 0 signifie qu’il n’y a pas de corrélation particulière sur la présence ou non de valeurs entre deux variables.
- Une valeur proche de 1 signifie que si une variable apparaît, il est très probable que l’autre variable soit présente.
Par exemple, pour la matrice ci-dessus, on observe de très fortes corrélations entre certaines colonnes VEHICLE TYPE CODE et CONTRIBUTING FACTOR VEHICLE, ce qui signifie que les informations à propos des véhicules semblent avoir le même taux de complétion de valeurs (présentes comme absentes). Inversement, OFF STREET NAME est très anti-corrélée avec ON / CROSS STREET NAME, donc là où cette première colonne manque de données, les deux autres sont au contraire très complètes.
Le dendrogramme
Derrière ce nom un peu barbare se cache un diagramme en arborescence qui très utilisé en Machine Learning non supervisée afin de représenter la hiérarchie des clusters. Avec Missingno, nous le traçons grâce la méthode msno.dendrogram(df) :
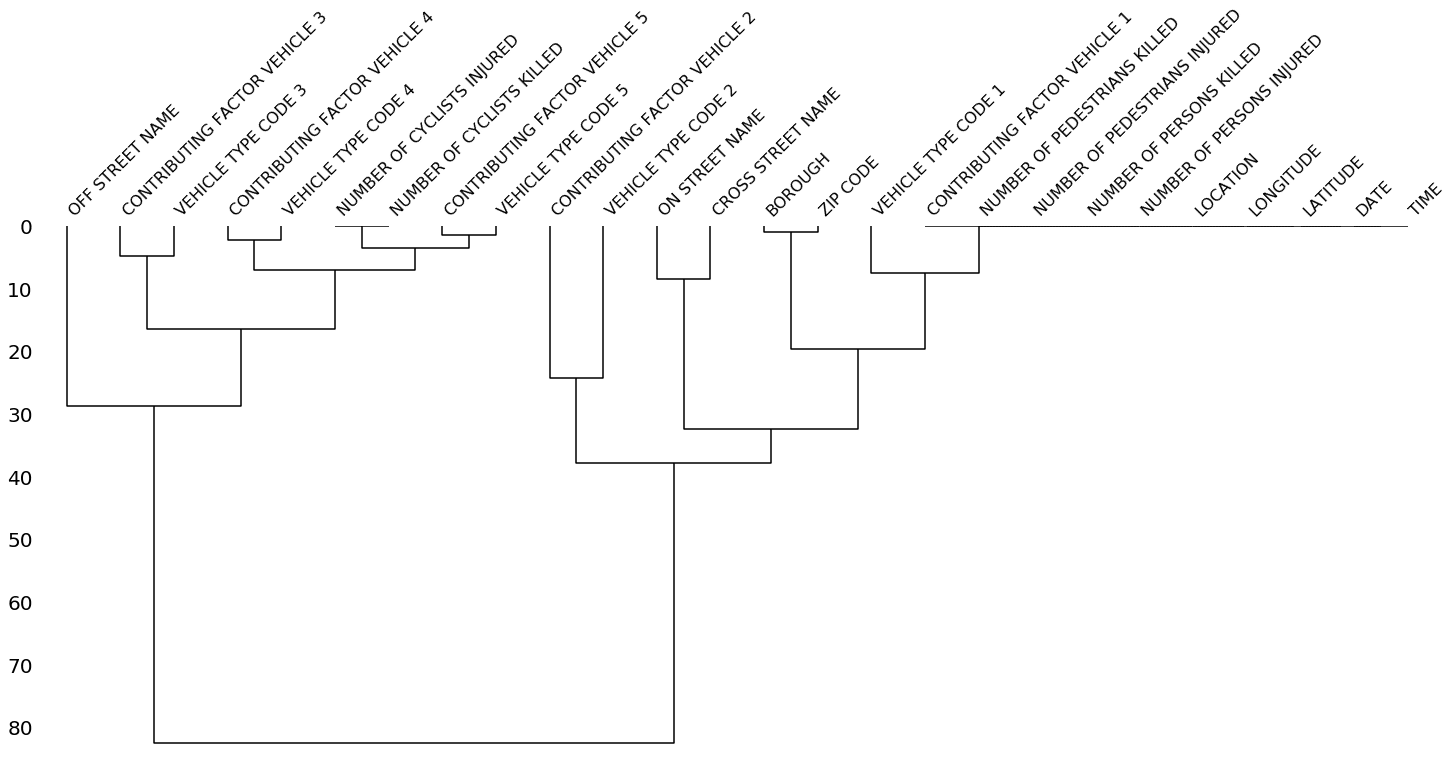
Le dendrogramme permet de regrouper les colonnes selon leurs corrélations de nullité. Plus les colonnes sont rapprochées, plus cette corrélation est importante (plus il y a un lien entre leur présence ou absence de valeurs).
Ici par exemple, nous pouvons distinguer trois groupes :
- les colonnes tout à droite, de CONTRIBUTING FACTOR VEHICLE 1 à TIME, pour lesquelles on ne retrouve aucune valeur manquante ;
- les colonnes au milieu, de CONTRIBUTING FACTOR VEHICLE 2 à VEHICLE TYPE CODE 1, qui contiennent une légère proportion de valeurs manquantes ;
- les colonnes tout à gauche, d’OFF STREET NAME à VEHICLE TYPE CODE 5, qui sont quasiment vides.
En conclusion
La librairie Missingno est ainsi idéale, lorsque nous rencontrons des valeurs manquantes dans notre jeu de données, pour visualiser où ces valeurs se situent et comment elles impactent nos variables.
On peut distinguer les graphiques disponibles en deux catégories : ceux qui permettent de visualiser les proportions de présence et d’absence de valeurs dans chaque colonne (diagramme en barres, matrice de nullité), et ceux qui permettent d’étudier les corrélations de nullité entre les variables (matrice de corrélation, dendrogramme).
Pour devenir un expert en manipulation de données, n’hésitez pas à suivre les formations Data Scientist & Data Analyst proposées par DataScientest !









