
A- Contexte
Cadre :
Ce projet a été réalisé dans le cadre de la formation de Data Scientist chez DataScientest, au sein de la promotion octobre 2021. Il s’agit du projet “fil rouge” qui permet de mettre en pratique une partie des notions qui sont apprises lors des modules.
Le but de ce projet est d’implémenter un tracker qui puisse suivre un ballon lors d’un match de football : nous avons une caméra qui pointe sur le terrain et nous devons mettre au point un système qui permette de garder le ballon au centre de l’image renvoyée par la caméra. Cette solution pourrait être mise en production dans des logiciels dans le but de fournir une assistance au guidage des caméras aux équipes de réalisation qui travaillent sur les évènements sportifs.
Pour créer la solution, nous allons faire de la détection d’objet associé à un algorithme de tracking. La détection d’objet est un domaine du deep learning dont le but est d’identifier la classe et la position d’un ou plusieurs objets donnés dans des images.
Problématique :
Nous pourrions implémenter un détecteur et tracker simplement avec les détections. Mais imaginons que le détecteur renvoie un faux positif où que le ballon disparaisse derrière un joueur alors le système entier serait en défaillance et nous perdrions la trace du ballon. Le détecteur seul n’est donc pas une solution assez robuste pour cette problématique. D’après les retours d’expérience disponible sur internet, nous devons combiner les détections du détecteur avec un système de tracking.
La problématique de ce projet est donc la suivante : « tracker des balles de sport en temps réel dans des vidéos ».
Cette problématique peut se diviser en deux problématique sous jacente :
- Détecter des balles de sport dans des images, c’est-à-dire leurs localisations dans l’image.
- Tracker des balles de sport dans des vidéos sur la base des détections successives dans les frames de la vidéo.
Objectifs :
- Créer un détecteur de ballons de sport satisfaisant les critères suivants :
- Bonne performance de détection (mAP a minima de 0.8).
- Temps d’inférence permettant de travailler en temps réel.
- Créer un détecteur de ballons de sport satisfaisant les critères suivants :
Remarque : la mAP est un métrique d’évaluation courante en détection d’objet. Nous la définirons plus loin dans l’article.
- Utiliser les détections du détecteur pour alimenter un tracker robuste et léger, c’est-à-dire associer un ID à un objet détecté et le tracer tout au long de son parcours dans l’image.
B- Le projet
Data Exploration (Définition de la problématique, difficultés) :
- Type de données et target
Nous travaillons avec des images, qui sont des données non structurées. Elles sont modélisées par des tableaux à trois dimensions de taille (n,m,3).
Chaque pixel est représenté par une série de trois valeurs (niveau de rouge, niveau de vert, niveau de bleu) qui se combinent pour former la couleur d’un pixel.
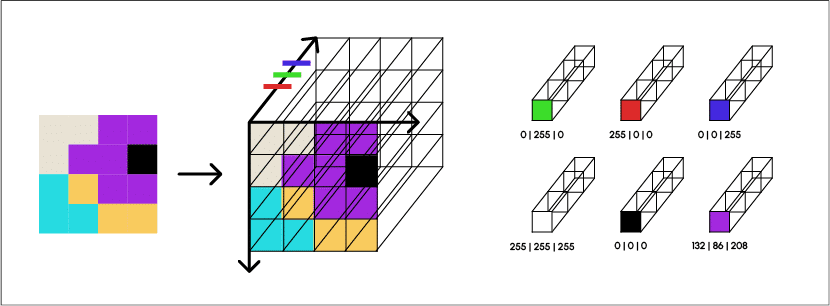
Ces objets sont les données d’entrée des modèles de Deep Learning que nous utiliserons par la suite. L’objectif est de prédire un rectangle d’encadrement pour les balles de football potentiellement présentes dans les images données au modèle. Ces rectangles sont définis par leurs centres, leurs hauteurs et leurs largeurs.
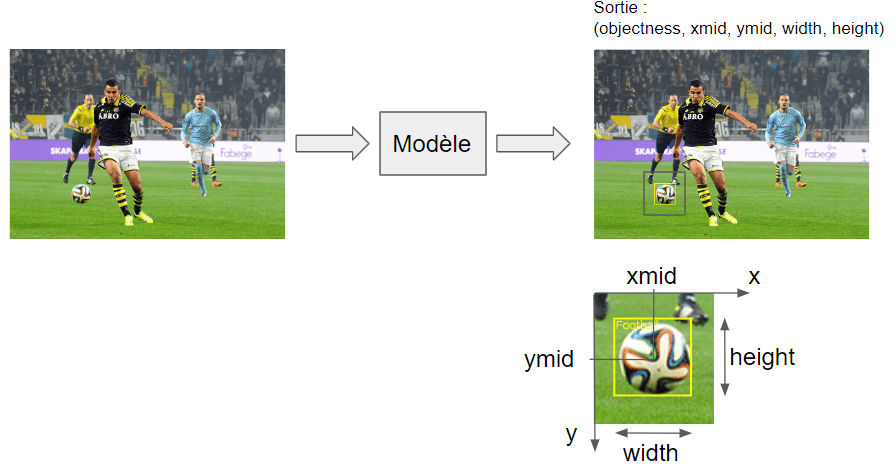
Ils vont représenter la sortie de nos réseaux de neurones c’est-à-dire les valeurs que nous cherchons à prédire.
- Source de données
Nous avons utilisé une partie du jeu de données Open Image V6 en ne prenant en compte que certains labels que l’on a catégorisé en « balle de sport ». Le jeu de données Open Image V6 a été développé par Google. Il contient presque 9 millions d’images avec leurs annotations et les bounding boxes (16 Millions) pour 600 catégories d’objets. Ces images ont été labellisées manuellement et vérifiées.
Nous avons pris toutes les classes qui appartiennent à la catégorie « balle de sport » afin d’augmenter le nombre d’images à notre disposition. C’est à dire :
- Football
- Golf Ball
- Rugby Ball
- Tennis Ball
- Volley Ball
Volume : 9 998 images pour 11773 annotations (1,18 annotations / image).
Après augmentation des données :
- Train : 27k images
- Test : 998 images
- Validation : 3000 images (pas d’augmentation de données sur ce split)
La répartition des dimension des images est la suivante :

Data visualisation :
Répartition des variables cibles : xmid, ymid, width, height et relations entre elles.
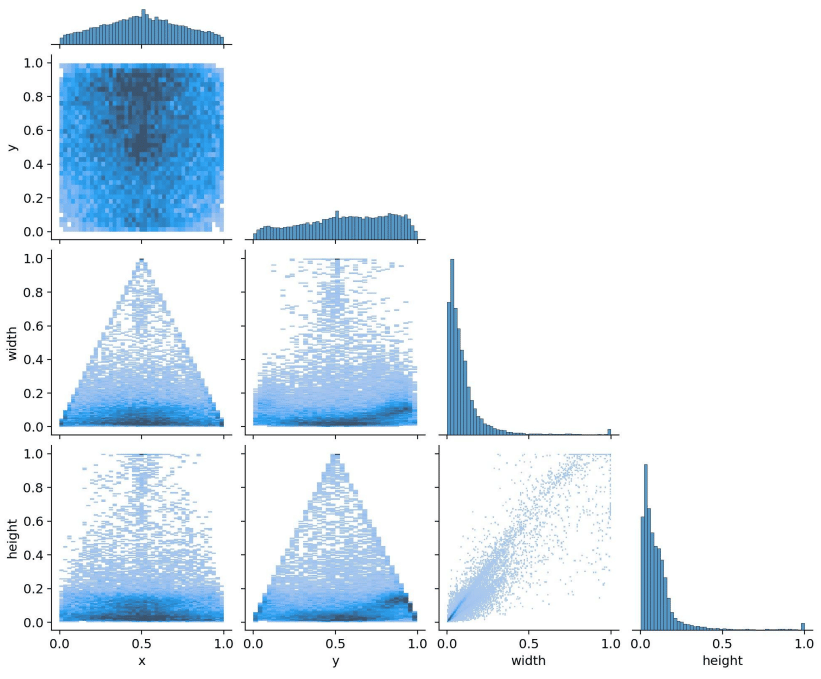
Nous constatons que la répartition des variables dans les deux jeu de données sont semblables :
- XMid : la majorité des balles sont situées au milieu de l’image. La répartition est en forme de pyramide.
- YMid : la majorité des balles sont situées dans la partie supérieure de l’image.
- w : les balles sont globalement petites avec un maximum de densité à 1/10 de la taille de l’image.
- h : même constat.
Au vu de cette répartition des variables cibles, les modèles qui seront entraînés vont développer un biais :
- Ils vont avoir tendance à détecter les balles plutôt dans la zone milieu haute de l’image (cf carte de densité).
- Ils vont avoir tendance à détecter des balles de taille allant de 0.1 à 0.2 fois la taille de l’image.
Afin de contrer ce biais nous allons avoir recours à de l’augmentation de données. L’augmentation de données consiste à appliquer des transformations aux images de base (translation, zoom, rotation, blur, contraste, bruits, etc.). À chaque nouvelle époque d’apprentissage, le jeu de données d’entraînement est modifié par ces transformations.
Cela permet de réduire le surapprentissage en réduisant le biais.
Nous avons appliqué les augmentations suivantes :
- Translation : translation de l’image dans chaque direction.
- Crop : rajoute de la variabilité dans la position et la taille.
- Rotation : rajoute de la variabilité dans l’alignement caméra, objet.
- Blur : rend le modèle plus résilient à la qualité des images.
- Bounding Box Blur : pour améliorer les capacité de détection des balles en mouvement.
Certains objets sont très petits (objet < 0.01 fois la taille de l’image). Même si ces objets sont présents dans les données d’entraînement à une proportion non négligeable, ils sont difficiles à détecter en pratique.
Deep Learning (Modèles et améliorations, Différentes itérations avec leurs apports respectifs)
1/ MLP classique
On a commencé par entraîner un modèle basé sur l’architecture MLP (Multi Layers Perceptron) classique. Le modèle prend en entrée le vecteur des pixels des images en niveau de gris (48*48 pixels) et sort 4 valeurs : XMid, YMid, w, h.

Ce modèle n’a pas produit de résultat concluant. Les MLP ne sont pas adaptés à la tâche de détection d’objets en raison du nombre de paramètres dans un MLP. Pour un image de 200*200 pixels et si nous prenons une première couche égal au nombre de variable de l’image cela fait 40000 * 40000 = 1,6e9 connexions uniquement pour la première couche. Nous verrons que les CNN (Convolutional Neural Network) permettent de résoudre ce problème.
2/ CNN de régression
Les CNN ont montré leur efficacité pour le traitement de tâche visuelle. Ils ont été employés dans les systèmes des voitures autonomes ou dans la classification des vidéos entre autres.
Dans un CNN une couche est représentée en deux dimensions donc on peut donner directement nos images en entrée sans avoir besoin de les aplatir.
Nous avons implémenté une architecture de CNN, l’EfficientNet, pré-entraîné sur le jeu de données imagenet et nous avons fait un transfert d’apprentissage pour l’adapter à notre problème.

Le réseau n’est pas capable de bien détecter les objets dans les images. De plus, nous sommes toujours limités à une détection par image, ce qui est très restrictif.
3/ YOLO simplifié
L’algorithme est connu pour sa rapidité et sa précision. Il permet de prédire en temps réel une multitude de boundings boxes par image. L’idée du détecteur YOLO (You Only Look Once) est d’exécuter l’image sur un modèle CNN et obtenir en sortie la détection en un seul passage.
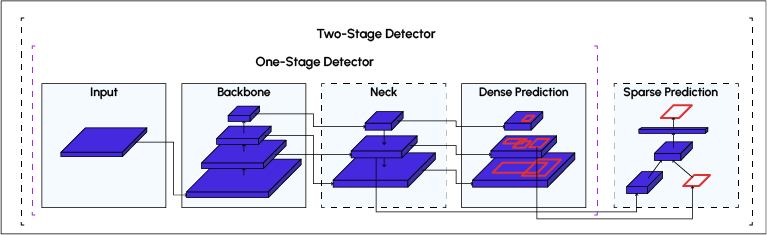
L’architecture de YOLO se compose de trois éléments principaux :
- Backbone – Un réseau neuronal convolutif qui agrège et forme des caractéristiques d’image .
- Neck – Une série de couches pour mélanger et combiner les caractéristiques de l’image pour les transmettre à la prédiction.
- Head – Consomme les fonctionnalités du Neck et contient des étapes de prédiction de bounding boxes et de classe.
Version simplifiée que nous avons mise en place :
- nous avons quadrillé les images en 16*16 donc nous avons 256 cellules,
- nous avons utilisé l’architecture efficientnetB0 comme backbone,
- nous n’avons pas de Neck puisque nous faisons directement nos prédictions à la sortie du backbone.
Voici l’architecture du modèle :

Interférence :
TRAIN

TEST

VALIDATION

Le modèle localise bien les objets lorsqu’ils sont isolés et de taille suffisante. On constate un biais sur la taille de rectangle d’encadrement lorsque l’objet devient trop grand et trop petit. Nous calculons une mAP de 0.31 pour ce modèle. Ce n’est pas suffisamment performant comme détecteur par rapport à notre cahier des charges.
Focus sur la métrique mAP - mean Average Precision
Nous vous avions promis une définition de la métrique mAP, nous y voilà.
Précision : taux de vrai positif par rapport à l’ensemble de ce que le modèle a prédit comme positif, elle mesure la capacité du détecteur à correctement prédire les rectangles d’encadrement, c’est à dire ne pas avoir de faux positif.
Recall : taux de bonnes prédictions parmi tous nos vrais rectangles d’encadrement. Il mesure la capacité du détecteur à détecter tous les rectangles d’encadrement, c’est-à-dire ne pas avoir de faux positif.
En détection d’objet, le seuil pour trancher entre un vrai positif et un faux positif se base sur l’IoU :
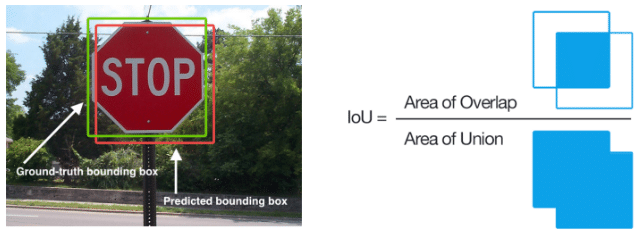
Quand un modèle de classification fait une prédiction, il nous donne généralement un indice de confiance, c’est-à-dire la probabilité qu’un objet appartienne à une classe donnée. Nous pouvons donc arbitrairement choisir le seuil à partir duquel on considère qu’une détection appartient à la classe donnée.
Nous devons donc faire un compromis en précision et rappel en jouant sur ce seuil.
Plus le seuil de confiance est haut, plus la précision est proche de 1, moins le recall est proche de 1. Plus le seuil est bas, moins la précision est proche de 1, plus le recall est proche de 1.
Il est possible de plotter la précision et le recall du modèle comme une fonction du seuil de confiance. Elle diminue au fur et à mesure que le seuil de confiance diminue, car plus on fait de prédiction, plus le recall augmente mais les prédictions sont moins précises.
Voici un exemple de courbe précision/rappel :

Pour la mAP, nous regardons la précision maximale que nous pouvons avoir avec un rappel d’au moins 10%, puis de 20%, puis de 30%, et ainsi de suite jusqu’à 100%, et on calcul la moyenne de ces précisions maximale.
Cette métrique peut être calculée à différent seuil d’IoU. Dans les différents benchmark dans le domaine de la détection d’objet, nous utilisons la valeur de 0.5 comme seuil, noté MAP:0.5.
YOLOV5
Nous avons utilisé le modèle YOLOV5 développé par Ultra Analytics et publié le 9 Juin 2020 sur le FrameWork PyTorch. Cette version est bien meilleure que les versions précédentes : on peut voir que l’on peut traiter des images en 2,5 à 7,5 ms/images avec un GPU tout en obtenant des performances comparables aux détecteurs à l’état de l’art.
Nous avons entraîné et testé 6 modèles yolov5 (combinaison de taille des images en entrée et profondeur du réseau) :
Récapitulatif :
| Taille des images | Profondeur | AP : 0.5 (IoU threshold | F1 score | Conf threshold |
|---|---|---|---|---|
| 640px | large | 0,674 | 0,69 | 0,216 |
| extra large | 0,658 | 0,69 | 0,286 | |
| 960px | small | 0,477 | 0,53 | 0,119 |
| medium | 0,503 | 0,54 | 0,156 | |
| 1280px | small | 0,832 | 0,8 | 0,398 |
| medium | 0,8 | 0,78 | 0,273 |
Le modèle de détection retenu est le modèle YOLO V5 small entraîné à 1280*1280 pixels. Ce choix a été décidé de par les performances (mAP) et de vitesse d’inférence offertes par le modèle.
Partie tracker : filtre de Kalman
Le filtre de kalman est un algorithme de traitement de données récursif qui estime l’état d’un objet à l’aide de mesure (les détections du détecteur).
Il y a deux étapes :
- Une étape de prédiction : permet de prédire le dernier état estimé (la position du ballon à l’instant t) par rapport à la mesure (ou détection) faite à l’instant t-1. En faisant l’hypothèse d’un modèle de déplacement à vitesse constante, l’algorithme estime la position future du ballon.
- Une étape de correction : utilise la mesure faite à l’instant t (détection) pour corriger l’état estimé à l’étape de prédiction. S’il n’y a pas de détection alors cette étape n’a pas lieu et l’on se base uniquement sur l’état prédit par le filtre. L’étape de prédiction suivante se base alors sur la prédiction et non pas sur la détection.
Fonctionnement du tracker :
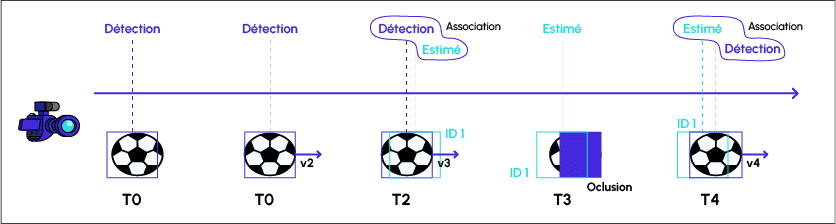
Dans le cas du suivi d’objet, les filtres de kalman sont pratiques pour compenser les défaillances du détecteur (voir figure ci-dessus).
- T0 : Le détecteur réalise une première détection.
- T1 : Le détecteur réalise une seconde détection. A cette étape le filtre de kalman s’initialise, c’est-à-dire qu’il met à jour le paramètre de vitesse du ballon : v2.
- T2 : le filtre de kalman fait une estimation de la position du ballon (rectangle vert), le détecteur fait une détection (rectangle bleu). La détection est utilisée par le filtre de kalman pour mettre à jour ses paramètres (v3) : l’étape de correction à lieu. Le tracker calcule la distance entre les deux rectangles, ils sont suffisamment proches donc le tracker affecte l’identifiant 1 à l’objet suivi.
- T3 : le ballon est caché donc le détecteur ne réalise pas de détection. Le filtre de kalman fait l’estimation de la position du ballon. Il n’y a pas d’étape de correction. Dans ce cas, on associe l’identifiant 1 à l’estimé de kalman.
- T4 : Le filtre de kalman fait l’estimation de la position du ballon sur la base des mêmes paramètres de vitesse qu’à l’instant précédent (v3). Le détecteur réalise une détection. Ces deux rectangles sont suffisamment proches. On associe les deux et l’identifiant 1 est ré-affecté à l’objet détecté.
Illustration :






Fonctionnement du tracker
Résultats
Modèle de détecteur retenu :
Le modèle de détection retenu est le modèle YOLO V5 small entraîné à 1280*1280 pixels. Ce choix a été décidé de par les performances (mAP) et de vitesse d’inférence offertes par le modèle : mAP = 0,832 & vitesse d’inférence = 30,8ms soit une capacité de traitement de 32,46 fps (GPU TESLA T4).
Tracker :
On constate que le tracker fonctionne très bien lorsque :
- Les vidéos en entrée sont de bonne qualité.
- Les ballons de foot sont d’une taille suffisamment grande (varie en fonction du détecteur), lorsqu’ils sont trop petits, notre détecteur n’arrive pas à faire les détections.
- Ils ne bougent pas trop rapidement et ne sont pas déformés.
- Il n’y a pas de changement brusque dans la trajectoire du ballon.
En effet, lorsqu’elles sont trop petites, notre détecteur n’arrive pas à faire les détections. Et lorsque les balles bougent trop rapidement, l’aspect du ballon est trop déformé pour que le détecteur réussisse à détecter le ballon.
Lorsque le ballon change brusquement de direction : les détections et les estimations du filtre de kalman diverge l’une de l’autre : les associations ne se font plus.
Il faut aussi que les vidéos soient en haute définition pour que le détecteur fonctionne correctement.
Cas idéal :

Cas limite de déformation

Cas limite : changement brusque de la trajectoire du ballon

C- Limites
Nous avons identifiés plusieurs limites, les principales sont :
- Le détecteur n’est pas assez robuste :
- On constate qualitativement que les objets de petite taille ne sont pas assez bien détectés. Dans cet exemple, le détecteur indique le point de penalty et non le ballon de football.

- On constate que le détecteur ne détecte pas les ballons lorsqu’ils sont déformés suite à une forte frappe.

- Le tracker n’est pas assez performant : il y a de nombreux objets et joueurs en mouvement dans plusieurs directions avec des vitesses différentes et des trajectoires difficilement prédictibles en utilisant l’hypothèse d’un mouvement à vitesse constante.

D- Axes d'amélioration
Si nous avions eu plus de temps pour mener le projet lors de la formation, nous aurions réitéré en réalisant les étapes suivantes :
- Enrichissement de la base de données avec des images à plus forte résolution, contenant des objets de petite taille et des objets en mouvement.
- Utilisation d’un réseau YOLO plus large.
- Mise en œuvre d’une architecture RNN et entraînement sur des séquences vidéos labellisées.
- Mise en œuvre de l’algorithme de tracking plus sophistiqué (ex : DeepSORT).
E- Conclusion
Pour la partie détection :
On peut considérer que l’objectif est atteint, on a retenu un modèle qui arrive plutôt bien à détecter les ballons de football, mais qui peut encore être amélioré.
Pour la partie Tracking :
Le tracker que nous avons utilisé répond bien à la problématique du single object tracking dans le cas où l’objet suivi n’est pas trop petit, dans la mesure où il permet de compenser lorsque notre détecteur est en défaillance sur quelques frames.
Son grand avantage est la faible complexité algorithmique qui allonge très peu le processus de traitement d’une vidéo (versus détecteur seul).
Sa faiblesse est sa robustesse : il ne permet pas de compenser le détecteur lorsque la période de défaillance est longue. Par exemple, lorsqu’un joueur tape avec puissance dans un ballon, la vitesse et la déformation du ballon rend impossible le tracking
Nous n’avons pas essayé de mettre en œuvre un tracker basé sur une technologie de deep learning, je pense notamment à DeepSORT. Cela aurait pu être une solution.
Le mot de la fin :
Ce projet pratique vient démontrer que l’on peut aboutir à des résultats concrets sur un sujet de Machine Learning en mettant en œuvre les notions étudiées au cours du cursus Data Science chez DataScientest tout en partant d’un niveau débutant.
Nous souhaitions remercier tous les intervenants de chez DataScientest pour la qualité des cours dispensés. Nous souhaitons remercier particulièrement notre responsable de projet Thomas BOEHLER pour sa disponibilité et ses conseils pertinents.








