
Quel temps fera-t-il demain ? Peut-on prévoir le cours de la bourse ? Peut-on « deviner » si un patient sera ou pas atteint d’une maladie ? Comment faire pour mieux comprendre le comportement des clients afin de leur proposer une offre adaptée ? Ce sont des questions auxquelles les data scientists et les statisticiens s’engagent à chercher des réponses en utilisant des méthodes de modélisation prédictive ou predictive modelling.
Cela a toujours été dans la nature de l’être humain de penser en termes de prédiction et de s’adapter au mieux aux conditions actuelles en utilisant les moyens qu’il a à sa disposition. L’évolution est basée sur la capacité d’êtres vivants de s’adapter et donc, implicitement de bien se préparer aux situations présentes afin de s’assurer des conditions favorables.
Parfois ces opérations de prédiction deviennent beaucoup trop complexes pour qu’elles soient réalisées par le cerveau humain, d’où l’intérêt de formaliser ces concepts et désigner la tâche à un algorithme.
Par ailleurs, notre cerveau est enclin à des biais cognitifs ou psychologiques qui peuvent nous conduire à des décisions irrationnelles et ces erreurs sont moins présentes lorsqu’on fait appel à un algorithme.
Aujourd’hui on a des outils qui permettent de modéliser (traduire en langage abstrait, mathématique) les phénomènes que l’on observe. La modélisation prédictive permet de trouver des réponses liées aux données qu’on a à notre disposition.
Comment fait-on de la modélisation prédictive ?
Les méthodes mathématiques et statistiques utilisées par les algorithmes reposent souvent sur des techniques qui utilisent des notions assez abstraites. Lorsqu’on veut faire du « prédictive modeling », il est utile de voir l’algorithme employé comme une fonction qui prend des données en entrée et qui rend des informations en sortie.
Il est également très important de bien comprendre l’intérêt des paramètres de l’algorithme pour pouvoir les ajuster en tenant compte des spécificités des données et des tâches à remplir.
La qualité des données a une forte importance sur les résultats obtenus. Avant de se lancer dans toute analyse, il faut penser à faire une analyse exploratoire des données et gérer les données manquantes, outliers, duplicatas, etc.
Il faut noter que chaque entreprise a ses propres protocoles et quand on cherche une réponse à une question, le travail est très souvent réalisé en équipe avec des spécialistes du domaine et cela permet aux scientifiques de bien comprendre les enjeux et appliquer les techniques les plus adaptées.
Concrètement ?
Comme décrit auparavant, la modélisation prédictive est utilisée pour prédire le comportement d’une métrique (mesure) à partir des données observées.
Tout d’abord il faut commencer par se poser les bonnes questions et être prêt à les changer au fil du temps parce qu’il n’y a pas une recette toute faite. Après avoir défini une problématique à partir d’un dataset, en fonction de sa spécificité, on choisit une approche adaptée qui nous permettra d’aboutir à des réponses ou à des éléments de réponse. Pour voir comment cela fonctionne en pratique, nous allons voir deux exemples.
Exemple 1 : données sociales et médicales
Analyse exploratoire
L’exemple suivant a été pris sur Kaggle, plateforme web organisant des compétitions en data science.
Pour faire simple, prenons un échantillon d’un dataset avec des données sur des personnes portant sur quelques indicateurs concernant leur milieu social et quelques informations médicales. On voit ici 5 individus (sur les lignes). Chaque individu a 12 caractéristiques (sur les colonnes) qui le caractérisent.

Par exemple, la personne avec l’id 29172 est une femme qui a 68 ans, qui a été mariée et qui vit dans un milieu rural, qui n’a jamais fumé et elle n’a pas eu de problèmes d’hypertension, ni de problèmes de cœur. On a également relevé son taux moyen de glycémie et son IMC.
Ce qui nous intéresse le plus c’est la dernière colonne, « stroke », qui permet de dire si la personne a eu ou pas un AVC dans le passé.
Avant de se lancer dans la classification, il est judicieux de faire de l’analyse exploratoire et voir la répartition des personnes atteintes par la maladie parmi les données.
Pour pouvoir répondre à un questionnement business ou lié à la recherche clinique, on souhaite savoir quel serait le profil qui est le plus enclin à développer cette maladie, ou bien prédire si une nouvelle personne a des chances de la développer.
Pour déterminer les caractéristiques qui influent le plus sur la maladie, on peut faire une représentation graphique avec les pourcentages des personnes malades selon leur profil.
On constate ici que les personnes qui fument et qui ont fumé avant, ont une prédilection à l’AVC plus forte que les personnes qui n’ont jamais fumé.
Pour les personnes qui présentent une hypertension, elles ont plus de chances d’avoir un AVC.
Pour cette analyse il est donc intéressant de faire ressortir des profils qui sont à risques et donc adapter son discours pour pouvoir prendre des décisions optimales.
Classification
Après avoir fait une étude exploratoire, on peut avoir une approche de classification. La classification, comme son nom le dit, sert à créer des classes (groupes) parmi les individus.
Maintenant on voudrait renseigner des nouvelles données et prédire si par exemple une personne avec un profil spécifique remplit les conditions pour avoir un AVC. Dans ce cas, on aura donc une approche de classification, c’est-à-dire qu’on veut attribuer un label à la personne : 0 si le sujet est sain ou 1 si le sujet est malade.
Selon la problématique et les données on a différentes méthodes ou modèles. Parmi les algorithmes de classification on peut utiliser KNN, K-means, Random Forest, régression logistique, etc. L’apprentissage automatique (en anglais : Machine Learning) permet à l’ordinateur d’apprendre à partir des données.
Pour avoir une idée sur la confiance qu’on peut faire au modèle, on passe par une phase « test », où on teste l’algorithme sur une partie des données. Il est important que l’erreur de test soit petite pour pouvoir faire confiance au modèle. Tester plusieurs algorithmes sert à comparer les erreurs et faire le bon choix.
Pour résumer, comme précisé dans la partie introductive, un algorithme de classification peut être visualisé comme une fonction qui prend en argument des individus dans notre exemple, et qui attribue à chaque individu une valeur 1 (malade) ou 0 (sain).
Exemple 2 : nombre des passagers
Un autre exemple très populaire pour l’analyse prédictive est l’étude des séries temporelles. Elles permettent de représenter l’évolution d’une quantité au cours du temps. On rencontre ce type de données dans les graphiques du cours de la bourse. La prévision des séries temporelles consiste à chercher un modèle adapté afin de prédire les valeurs futures sur la base des valeurs observées précédemment.
La structure du dataset est différente. Dans l’analyse de séries temporelles, on a une dimension temporalité, en d’autres termes les données sont ordonnées chronologiquement.
Comme il s’agit uniquement de deux variables, ici la date et le nombre de passagers à une date précise, on peut afficher une visualisation dans le plan :
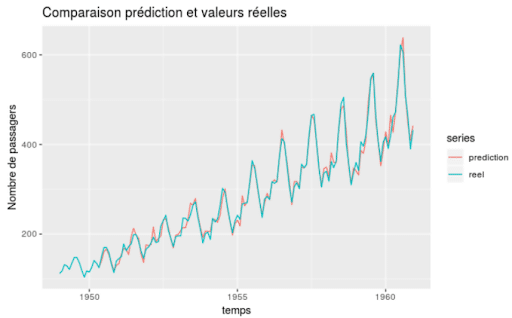
En turquoise on voit les données réelles et en rouge on a les estimations proposées par le modèle.
Le fait que les données soient ordonnées en fonction du temps entraîne une corrélation entre les variables voisines. L’étude des séries temporelles repose sur une décomposition en plusieurs éléments (tendance, saisonnalité et bruit).
Conclusion
Pour résumer, la modélisation prédictive apporte des réponses liées à une problématique spécifique et propose des méthodes qui permettent d’anticiper les comportements futurs. Il existe plein de façons possibles pour faire de la prévision et il est important de bien comprendre le contexte, bien définir les questions afin de proposer un modèle adapté au contexte.
Lors d’une analyse prédictive, il est donc essentiel d’avoir des connaissances dans les statistiques pour pouvoir mettre en place une étude adaptée et bien interpréter les résultats obtenus.
Si vous souhaitez vous former en statistiques et gagner en compétences techniques liées à ces sujets, n’hésitez pas à vous inscrire pour la formation de Data Scientist.









