
Retour de Daniel, le personnage emblématique de nos formations qui guide nos apprenants jusqu'à leur diplôme. Aujourd'hui il va vous présenter un modèle fréquemment utilisé en Computer Vision : VGG.
Nous avons déjà eu l’occasion, il y a quelque temps de détailler la notion de Transfer Learning ou apprentissage par transfert en français. Si vous avez raté notre article sur le sujet, je vous invite à le relire ici. Ce qu’il faut avoir en tête, c’est que le Transfer Learning correspond à la capacité à utiliser des connaissances existantes, développées pour la résolution de problématiques données, pour résoudre une nouvelle problématique.
Un peu d’histoire
VGG est un réseau de neurones convolutionnels proposés par K. Simonyan et A. Zisserman de l’université d’Oxford et qui a acquis une notoriété en gagnant la compétition ILSVRC (ImageNet Large Scale Visual Recognition Challenge) en 2014. Le modèle a atteint une précision de 92.7% sur Imagenet ce qui est un des meilleurs scores obtenus. Il a marqué une progression par rapport aux modèles précédents en proposant, dans les couches de convolution, des noyaux de convolution de plus petites dimensions (3×3) que ce qui avait été fait jusque-là. Le modèle a été entraîné sur des semaines en utilisant des cartes graphiques de pointe.
ImageNet
ImageNet est une gigantesque base de données de plus de 14 millions d’images labellisées réparties dans plus de 1000 classes, en 2014. En 2007, une chercheuse du nom de Fei-Fei Li a commencé à travailler sur l’idée de créer un tel jeu de données. Certes la modélisation est un aspect très important pour obtenir des bonnes performances, mais disposer de données de grande qualité l’est tout autant pour avoir un apprentissage de qualité. Les données ont été collectées et étiquetées depuis le web par des humains. Elles sont donc open source et n’appartiennent pas à une entreprise en particulier.
Depuis 2010 s’organise, chaque année, une compétition ImageNet Large Scale Visual Recognition Challenge dont le but est de challenger des modèles de traitement d’images. La compétition s’effectue sur un sous-ensemble d’ImageNet composé de : 1,2 million d’images d’entraînement, 50000 pour validation et 150000 pour tester le modèle.
L’architecture
Dans les faits, il existe deux algorithmes disponibles : VGG16 et VGG19. Dans cet article, nous allons nous concentrer sur l’architecture du premier. Si les deux architectures sont très proches et respectent la même logique, VGG19 présente un plus grand nombre de couches de convolution.

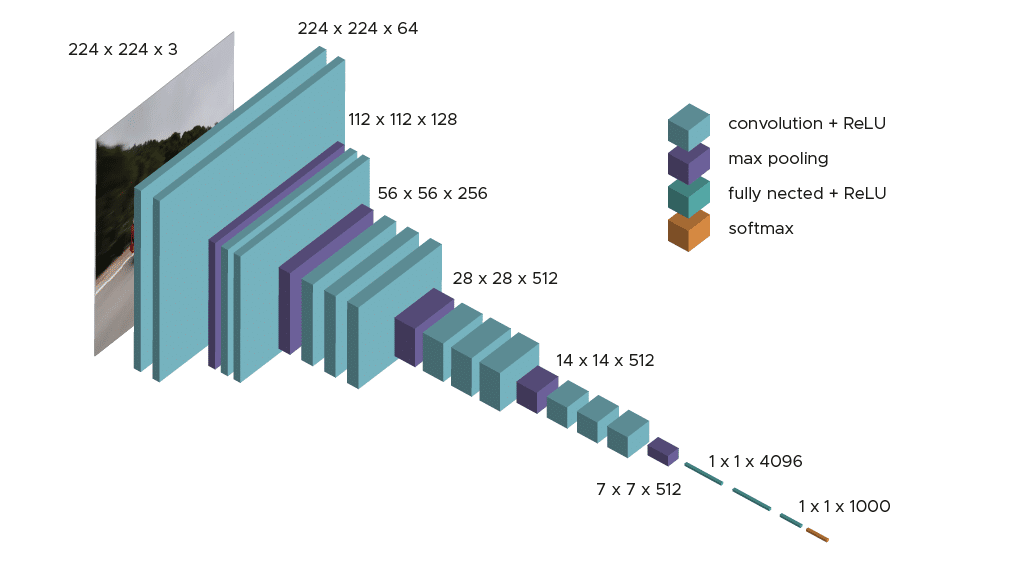
Le modèle ne demande qu’un prétraitement spécifique qui consiste à soustraire la valeur RGB moyenne, calculée sur l’ensemble d’apprentissage, de chaque pixel.
Durant l’apprentissage du modèle, l’input de la première couche de convolution est une image RGB de taille 224 x 224. Pour toutes les couches de convolution, le noyau de convolution est de taille 3×3: la plus petite dimension pour capturer les notions de haut, bas, gauche/droite et centre. C’était une spécificité du modèle au moment de sa publication. Jusqu’à VGG16 beaucoup de modèles s’orientaient vers des noyaux de convolution de plus grande dimension (de taille 11 ou bien de taille 5 par exemple). Rappelons que ces couches ont pour but de filtrer l’image en ne gardant que des informations discriminantes comme des formes géométriques atypiques.
Ces couches de convolution s’accompagnent de couche de Max-Pooling, chacune de taille 2×2, pour réduire la taille des filtres au cours de l’apprentissage.
En sortie des couches de convolution et pooling, nous avons 3 couches de neurones Fully-Connected. Les deux premières sont composées de 4096 neurones et la dernière de 1000 neurones avec une fonction d’activation softmax pour déterminer la classe de l’image.
Comme vous avez pu le constater l’architecture est claire et simple à comprendre ce qui est aussi une force de ce modèle.
Résultats obtenus sur ImageNet
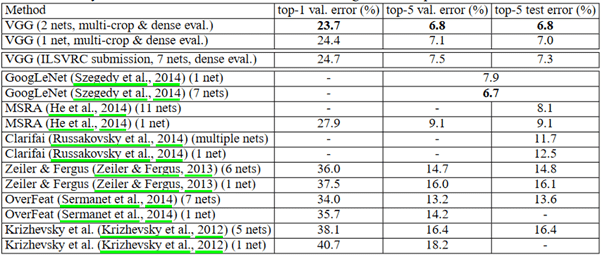
La figure ci-dessus compare les résultats de différents modèles de 2014 ou bien des années précédentes. Nous pouvons voir que VGG donne les meilleurs résultats aussi bien sur le jeu de validation que sur le jeu de test. Remarquons également que le modèle donne de bien meilleurs résultats que lors des sessions 2012 et 2013.
Et le Transfer learning dans tout ça ?
Comme nous l’avons déjà mentionné précédemment, le temps d’entraînement d’un modèle comme VGG peut être très long surtout si vous n’avez pas beaucoup de ressources à votre disposition. De plus étant donné qu’il a été entraîné sur ImageNet il peut être intéressant de récupérer les poids du modèle déjà entraîné et notamment les filtres dans les couches de convolution issus de l’apprentissage sur ImageNet. C’est d’ailleurs ce qui est fait dans la pratique : nous récupérons les poids issus des couches de convolution et nous avons simplement à entraîner les 3 couches que nous ajoutons. Le principe restant le même : utiliser les connaissances acquises sur ImageNet pour résoudre une problématique proche.
Il est notamment possible de récupérer directement le modèle pré-entraîné très facilement et d’appliquer le prétraitement spécifique demandé par le modèle.
Un peu de pratique
Dans les faits il existe deux algorithmes disponibles : VGG16 et VGG19.
Grâce à la librairie keras de Tensorflow, il est simple de récupérer le modèle déjà entraîné, par défaut, sur ImageNet.
Dans un premier temps, nous avons besoin d’appliquer le même traitement spécifique que celui appliqué au moment de l’entraînement du modèle. En plus de cela nous ajoutons de l’augmentation de données sur les données d’apprentissage pour prévenir un risque de sur-apprentissage. Il est aussi important de vérifier que les images données en input sont des images RGB de taille 224×224.
Nous pouvons alors récupérer les poids optimisés issus des couches de convolution et entraîner les 3 couches Dense que nous ajoutons et compiler :
Après entraînement, si les résultats ne sont pas assez bons, il est possible de ne plus figer les dernières couches de convolution et de les ré-entraîner pour essayer d’avoir de meilleures performances. Là aussi tout dépend des ressources dont vous disposez, cette étape supplémentaire peut être coûteuse en temps.
Conclusion
VGG est un algorithme connu en Computer Vision très souvent utilisé par transfert d’apprentissage pour éviter d’avoir à le réentraîner et résoudre des problématiques proches sur lesquelles VGG a déjà été entraîné. Il existe bien d’autres algorithmes du même type que VGG comme ResNet ou bien encore Xception disponible dans la librairie Keras. Si vous souhaitez vous former sur des problématiques de Deep Learning/Computer Vision, rejoignez-nous en Bootcamp ou bien en formation continue.









