
L'une des fonctionnalités les plus populaires d'Instagram est sa page d'exploration, elle recommande chaque jour des milliards de contenus pour les 500 millions d’utilisateur quotidien de l’application. Dans un récent billet de blog, Vladislav Vorotilov et Ilnur Shugaepov, deux ingénieurs chez Meta, ont expliqué comment fonctionne cet algorithme hautement évolutif.
Qu’est-ce qu’un algorithme de recommandation ?
C’est une question totalement légitime à laquelle il est primordial de répondre avant d’aller plus loin. Pour faire simple, un algorithme de recommandation est une suite de calcul qui va analyser et sauvegarder tout le contenu d’Instagram avant de le trier et de proposer des résultats selon vos préférences et vos abonnements antérieurs de sorte à accroître votre réseau d’abonnement sur l’application.
Remarquable n’est-ce pas ? Mais alors comment ça marche ? A savoir que tous les réseaux sociaux utilisent un algorithme de recommandation et qu’ils fonctionnent tous, globalement, de la même façon. Un algorithme de recommandation possède une architecture en couche décrite comme ceci :
- Récupération – Réduire le nombre de candidats à montrer à un utilisateur parmi des millions d’éléments potentiels.
- Première étape du classement – Appliquer un système de classement de bas niveau pour classer rapidement les millions de photos/vidéos potentielles et les réduire aux 100 meilleurs candidats.
- Deuxième étape – Appliquer un modèle de machine learning (ML) plus lourd pour classer les 100 éléments en fonction de la probabilité que l’utilisateur s’engage avec la photo/vidéo.
- Reclassement final – Filtrer et déclasser les éléments en fonction des règles de l’entreprise (par exemple, ne pas montrer le contenu du même auteur à plusieurs reprises, etc.)
Les détails spécifiques diffèrent, mais la plupart des systèmes de recommandation utilisent ce type d’architecture : génération de candidats, classement, filtrage final.
LANCEZ VOTRE CARRIÈRE :
DEVENEZ DATA SCIENTIST !
Une reconversion dans le big data vous intéresse, mais vous ne savez pas par où commencer ? Découvrez notre formation de Data Scientist.
LANCEZ VOTRE CARRIÈRE :
DEVENEZ DATA SCIENTIST !
Une reconversion dans le big data vous intéresse, mais vous ne savez pas par où commencer ?
Comment fonctionne l’algorithme d’Instagram ?
Pour entrer dans les détails, passons en revue chaque étape de classement pour expliquer quels éléments ou techniques de data science sont mis en œuvre.
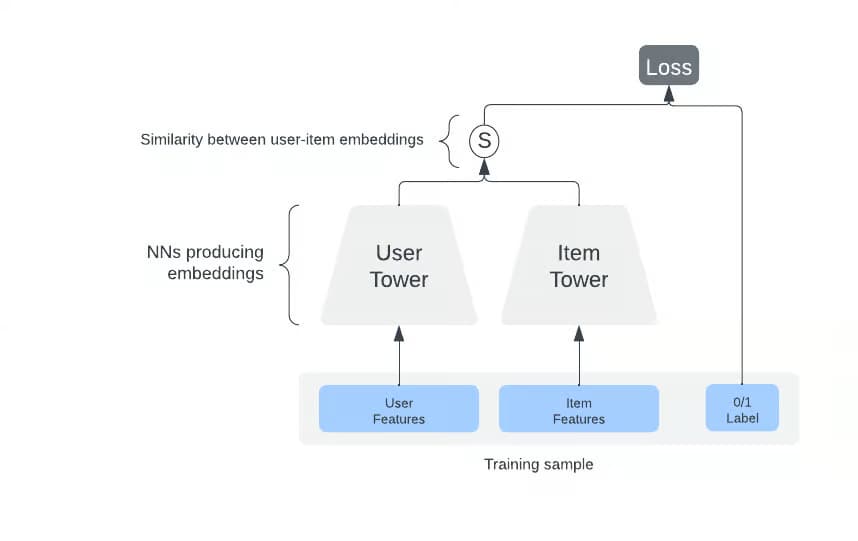
Récupération – L’étape de génération des candidats utilise un ensemble de critères et de modèles ML comme les modèles neuronaux à deux tours pour réduire les éléments potentiels à des milliers de photos/vidéos.
En termes de critères, Instagram utilise des éléments tels que : les comptes que vous suivez, les sujets qui vous intéressent et les comptes avec lesquels vous vous êtes déjà engagé.
Première étape – Une fois les candidats récupérés, le système doit les classer en fonction de leur valeur pour l’utilisateur. Cette « valeur » est déterminée par la probabilité que l’utilisateur s’intéresse à la photo ou à la vidéo. L’engagement est mesuré par le fait que l’utilisateur aime/commente la photo/vidéo, la partage, la regarde entièrement, etc.
Pour ce faire, Instagram utilise à nouveau le modèle NN à deux tours. Sur cette base, les 100 meilleurs articles sont transmis au modèle de classement de deuxième étape.
Deuxième étape – Instagram utilise ici un modèle de réseau neuronal multitâche et multiétiquette (MTML). Pour les systèmes de recommandation, cela signifie prédire différents types d’engagement de l’utilisateur vis-à-vis d’un contenu (probabilité qu’un utilisateur aime, partage, commente, bloque, etc.). Le modèle MTML est beaucoup plus lourd que le modèle NN à deux tours du premier classement. Prédire tous les différents types d’engagement nécessite beaucoup plus de caractéristiques et un réseau neuronal plus puissant.
Reclassement final – À ce stade, Facebook applique des règles commerciales pour filtrer certains types de contenu. Par exemple, éviter d’envoyer trop de contenu provenant du même auteur, rétrograder les posts/contenus qui pourraient être considérés comme nuisibles et ainsi de suite.
Si cet article vous a plu et si vous envisagez une carrière dans la Data Science, n’hésitez pas à découvrir nos articles ou nos offres de formations sur DataScientest.
Source : engineering.fb.com









