
Avec l’arrivée des bases de données NoSQL, Redis tire son épingle du jeu en proposant une gestion des données en mémoire.
Créée en 2009 par Salvatore Sanfilippo, Redis est devenue l’une des bases de données NoSQL les plus populaires. Nommé base de données la plus aimée par les développeurs pendant 5 années d’affilées d’après le sondage annuel « Stackoverflow Developer Survey », Redis est actuellement utilisé par de nombreuses compagnies comme Twitter, GitHub ou Snapchat. Découvrez tout ce que vous devez savoir sur cette base de données en mémoire rapide.
Qu'est-ce que Redis ?
Redis (Remote Dictionary Server) est un système de gestion de données open source écrit en C, conçu pour stocker, récupérer et manipuler différents types de données. Il s’agit d’une base de données NoSQL de type paire clé/valeur. Redis peut être configurée pour stocker des données sur disque, cependant, il est principalement utilisé pour la gestion de données en mémoire vive, ce qui la rend beaucoup plus rapide que les bases de données traditionnelles. Avec ses temps de réponse rapides permettant des millions de requêtes par seconde pour des applications en temps réel, Redis est utilisée en production dans des secteurs tels que les jeux vidéo, la publicité, les services financiers, la santé et l’IoT.
Comment fonctionne Redis ?
Redis est une base de données NoSQL dont le système de gestion repose sur une structure clé-valeur, où chaque valeur est associée à une clé unique. Les structures de données (data structure) de Redis supportent nativement différents types de valeurs comme des entiers (integers), des chaînes de caractères (strings), des hachages (hashes), des listes (lists), des ensembles (sets), des ensembles triés (sorted sets), des bitmaps, des bitfields, des hyperLogLog, des index spatiaux et des flux (streams).
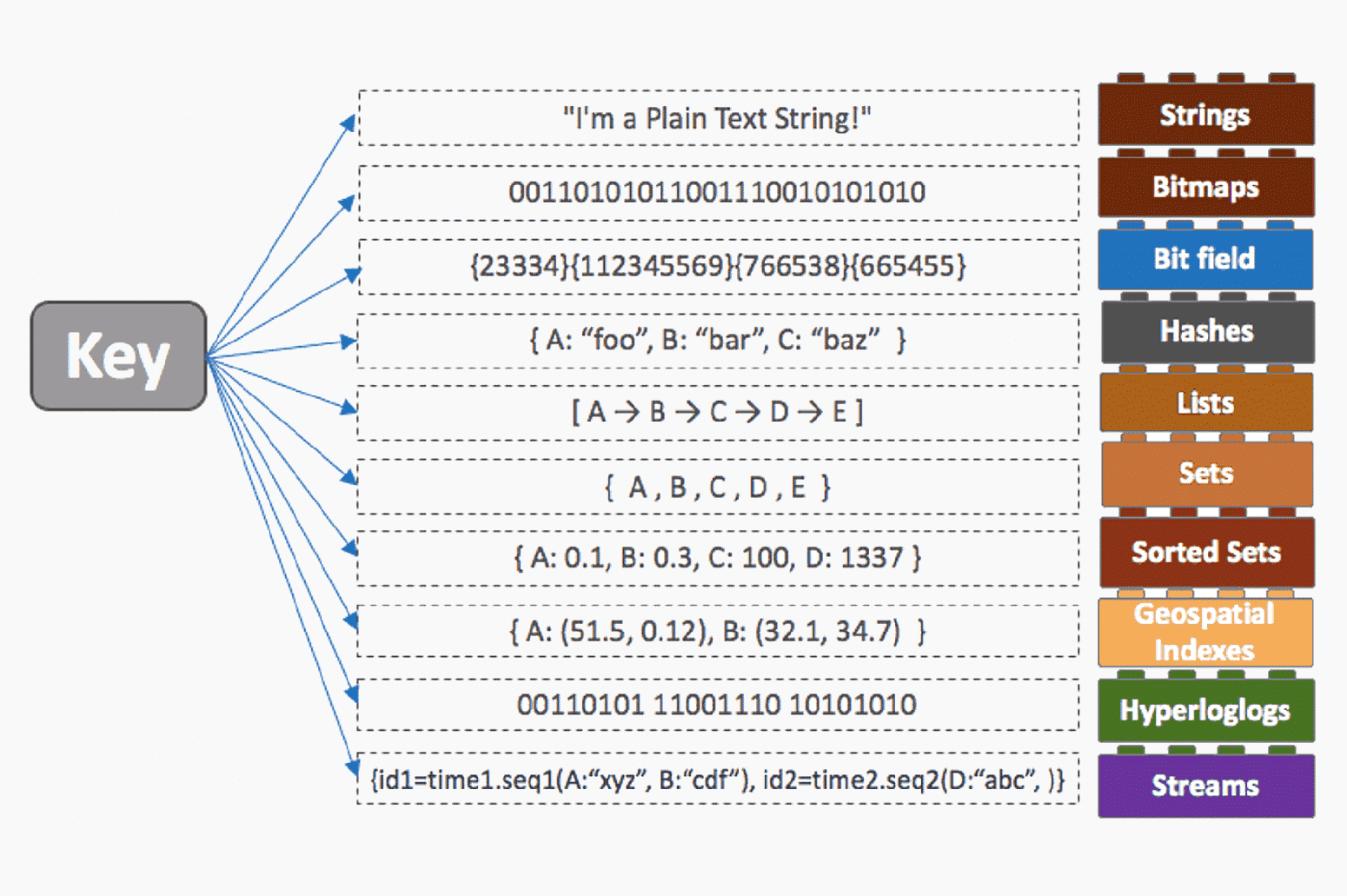
Chaque type de structure possède des commandes dédiées permettant de faciliter l’exécution d’opérations des différents types de valeur. Les données peuvent ensuite être stockées en mémoire vive ou en permanence sur le disque en utilisant la fonction de sauvegarde de Redis. La récupération des données en cas de panne du système se fait grâce à ces sauvegardes effectuées de manière automatique ou manuelle.
Différents moyens sont ainsi proposés par l’outil pour modéliser les données dans de nombreux cas d’utilisation modernes.
Redis n’est pas une base de données relationnelle, donc le concept ACID (Atomicité, Cohérence, Isolation, Durabilité) n’est pas applicable. Cependant, les transactions atomiques et l’isolation de données pour assurer l’intégrité des données sont assurées par le système de gestion de base de données.
Quelles sont les fonctionnalités de Redis ?
Si Redis est autant appréciée par les développeurs, cela est dû aux nombreuses fonctionnalités proposées par la base de données.
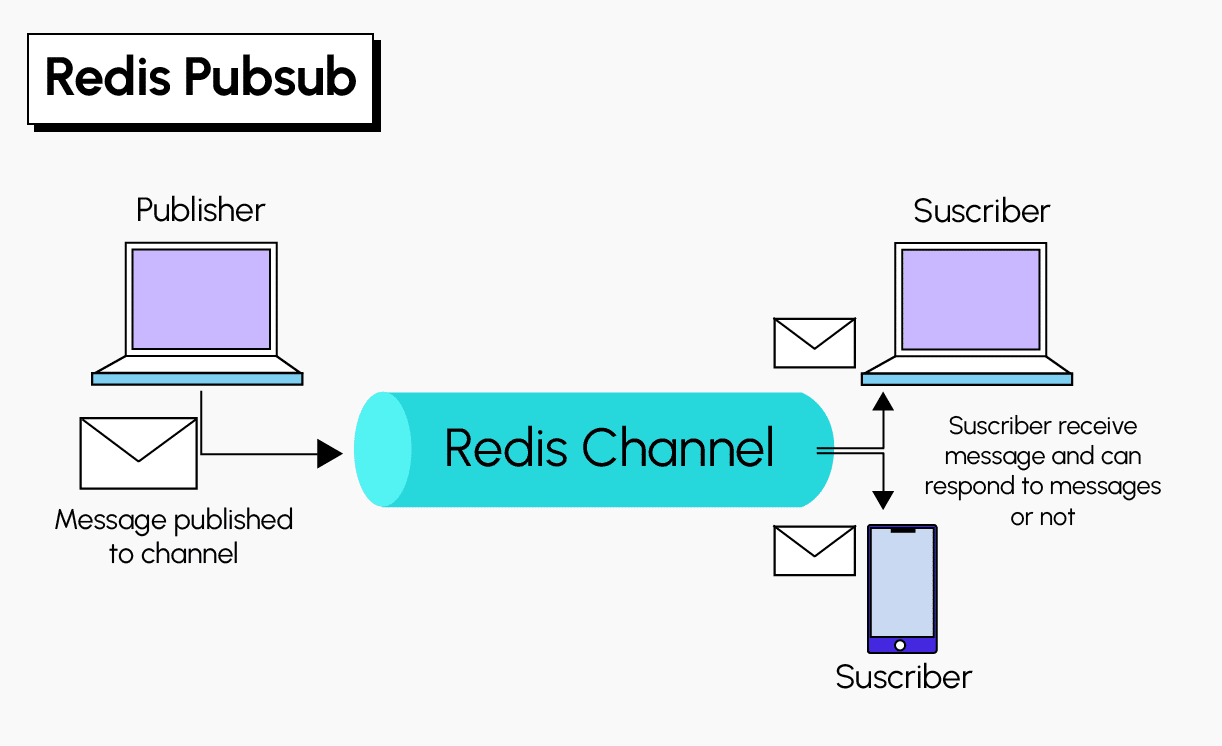
La fonction de Publish/Subscribe (pub/sub) de Redis permet la diffusion de messages en temps réel entre les différentes parties d’une application. Le fonctionnement de cette diffusion est simple. Les messages envoyés par les expéditeurs (publishers) ne sont pas directement envoyés à des destinataires spécifiques (subscribers) mais passent dans des canaux (channels). Seuls les abonnés du canal en question reçoivent le message qui est envoyé « au plus, une fois » (at-most-once). Cela signifie qu’une fois le message envoyé par le serveur Redis, il n’y a aucune chance qu’il soit envoyé à nouveau. En raison d’une erreur ou d’une déconnexion du réseau, le message est définitivement perdu. Ce découplage des éditeurs et des abonnés permet une plus grande évolutivité et une topologie de réseau plus dynamique.
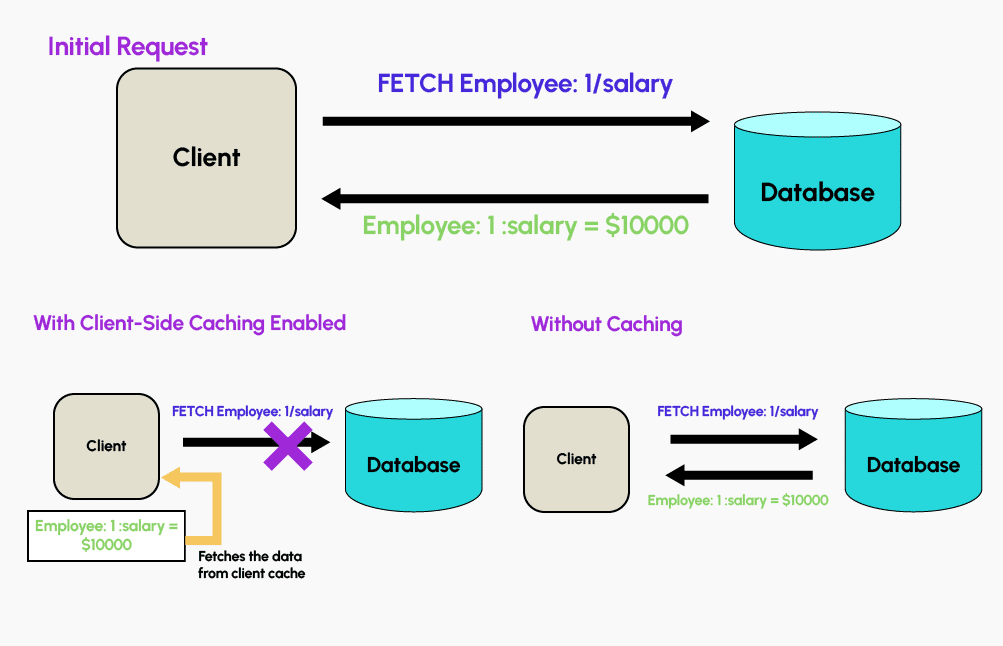
Redis propose une fonctionnalité de mise en cache côté client. En exploitant la mémoire disponible sur les serveurs d’application pour stocker un sous-ensemble des informations de la base de données directement dans l’application, elle va alors permettre de créer des services très performants. L’application va alors stocker la réponse aux requêtes les plus courantes directement dans sa mémoire de l’application et les réutiliser ultérieurement, sans avoir à recontacter la base de données. Il est possible d’assurer que les données en cache soient toujours à jour en configurant une expiration les données stockées après un certain temps.
Il est possible pour l’utilisateur d’envoyer plusieurs commandes Redis à la base de données en une seule opération réseau grâce au pipeline de Redis. Au lieu d’envoyer chaque commande Redis séparément, un pipeline permet d’envoyer toutes les commandes en une seule fois, en les encodant dans un seul paquet réseau. Le serveur Redis stocke alors ces commandes dans une file d’attente temporaire et les exécute toutes à la suite, puis renvoie les résultats au client dans le même ordre. C’est une fonctionnalité très utile pour les applications qui ont besoin de traiter un grand nombre de commandes à la fois et pour avoir un temps de latence considérablement réduit.
Redis possède également un support de tri automatique des données, ce qui va permettre un gain de temps et qui facilite la gestion des données. Cette fonctionnalité est particulièrement utile pour les applications nécessitant une récupération de données triées en temps réel, telles que des leaderboards.
En conclusion
Redis est une base de données utilisée principalement en production qui est beaucoup plus rapide que les bases de données traditionnelles grâce à son stockage en mémoire, n’utilisant le disque que pour la persistance. Elle peut traiter des millions de requêtes par seconde, ce qui la rend idéale pour les applications en temps réel. Nonobstant, sa force ne permet pas à Redis de répondre parfaitement aux besoins du Big Data, car l’ensemble des données réside toujours dans la RAM. Pour les ensembles de données très volumineux, vous pouvez vous attendre à des problèmes de performance et des coûts élevés pour l’achat de serveurs avec une quantité de RAM suffisante.
Redis est simple à utiliser, tant dans la mise en place de l’environnement que dans son utilisation pratique. Cependant, il est possible de résoudre des problèmes complexes avec cette technologie, et même l’utiliser pour les APIs ou pour de l’intelligence artificielle comme la reconnaissance faciale.
La technologie fait preuve de grande flexibilité car elle est supportée par de nombreux langages de programmation tels que C, C#, C++, Java, Python, Perl, PHP, Node.js et supporte nativement la plupart des types de données déjà connus des utilisateurs.
Dans l’ensemble, Redis est un excellent choix pour les applications nécessitant une base de données rapide et fiable, et celles qui ne nécessitent pas la manipulation de grandes quantités de données. Appréciée pour la phase de production, il est néanmoins parfois préférable de choisir des technologies conçues spécifiquement pour répondre aux besoins du Big data telles que Apache Hadoop, Apache Spark, ou Cassandra. La maîtrise de ces outils est recherchée par de nombreuses entreprises. N’hésitez pas à consulter la formation Data Engineer proposée DataScientest pour acquérir des compétences indispensables dans le monde du Big Data.









