Vous avez déjà probablement entendu parler des réseaux convolutifs dans les contextes de reconnaissance d’image, de traitement vidéo ou encore dans le ciblage publicitaire et le NLP. Cet article a pour but de délivrer une première approche analytique et une compréhension de l’architecture de ces réseaux, et plus particulièrement sur l’architecture des réseaux DenseNets.
Les réseaux de neurones convolutifs - CNN
Prenons le cas de l’analyse d’image qui fait partie aujourd’hui d’une des grandes applications du machine learning. Chaque image est représentée par un très grand nombre de données et peut être visualisée comme un objet au sein d’un espace de très grande dimension.
Mais alors comment exploiter les propriétés de ces images de façon efficace compte tenu de la taille conséquentes des données qui les représentent ?
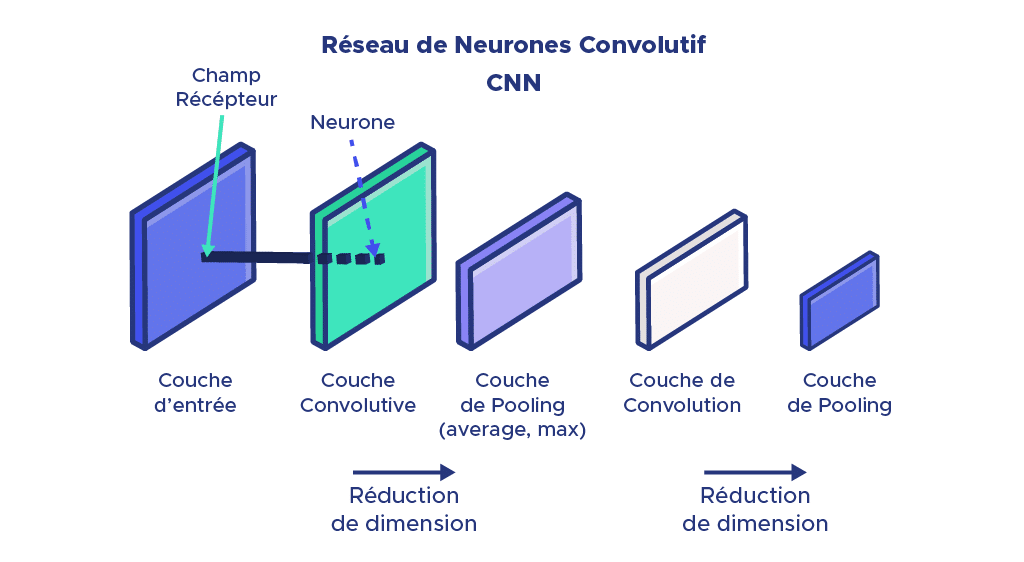
Les réseaux de convolution apportent une solution efficace à ce problème : chaque couche intermédiaire du réseau est exposée à une portion de l’image appelée champ récepteur pour lequel plusieurs neurones effectuant différentes actions, calculent une matrice de convolution correspondante.
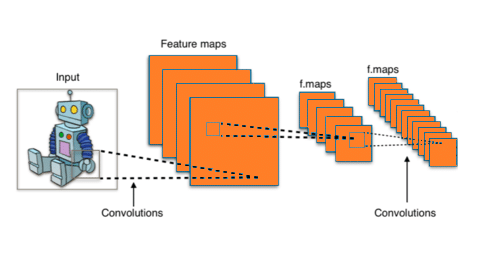
Ainsi, chaque couche intermédiaire génère plusieurs matrices de convolution : tout cela laisse penser que nous étendons l’information plutôt que de la restreindre ? Pas vraiment !
Le partage de poids synaptique (ou weight sharing), définit le partage de poids entre les neurones d’une même couche. Ceci correspond à une réduction considérable des paramètres au sein de chaque couche. L’information à la sortie de ces couches est également restreinte grâce à une phase de réduction de dimension qui permet de rassembler les informations provenant de plusieurs neurones voisins appartenant au même canal, en une information commune au travers de l’ajout systématique d’une couche d’extraction en sortie des couches convolutives.
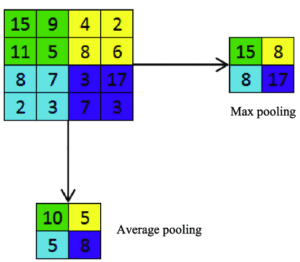
Il existe deux sortes de couche d’extraction :
- Average pooling : qui calcule la valeur moyenne des informations
- Max pooling : qui ne retient que la valeur maximale des informations et les utilise pour créer une feature map sous échantillonnée.
Nous obtenons donc en sortie de ces superpositions (couche concolutives et couche avg/max pooling), un vecteur de taille raisonnable et réduite représentant les informations extraites de l’image de façon certes, moins précise, mais beaucoup plus facilement exploitables.
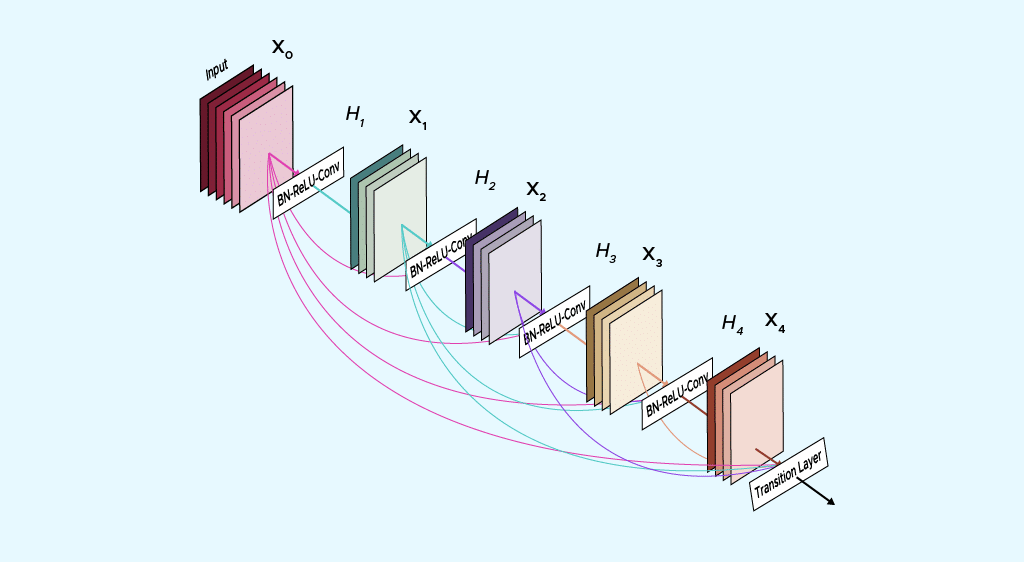
Les réseaux DenseNet
Les réseaux DenseNet sont des réseaux de neurones convolutifs répondant à une certaine architecture communément appelée réseaux de neurones densément connectés (‘densely connected convolutional network’ ou DenseNet).
Un challenge grandissant de ce type de réseau est l’optimisation des performances. Une solution naïve serait simplement d’empiler davantage de couches convolutives: un problème évident qui survient dès lors, est l’agrandissement de la profondeur du réseau. Lorsque l’on effectue la rétropropagation du gradient au travers des couches: on effectue en réalité une opération sur les dérivées partielles de chaque couche cachée du réseau et cela peut potentiellement compliquer les mises à jour des poids durant la phase d’entraînement.
La grande spécificité de cette architecture réside dans l’entrée des couches qui rassemble par concaténation toutes les entrées des couches précédentes (voir schéma) : créant ainsi une feature map, tout en conservant une résolution spatiale identique : on parle de channel-wise concatenation.

Ainsi, il devient inutile d’effectuer un processus de sélection d’information, contrairement à d’autres réseaux pour lesquels il est nécessaire de choisir quelles informations sont à transmettre aux couches suivantes.
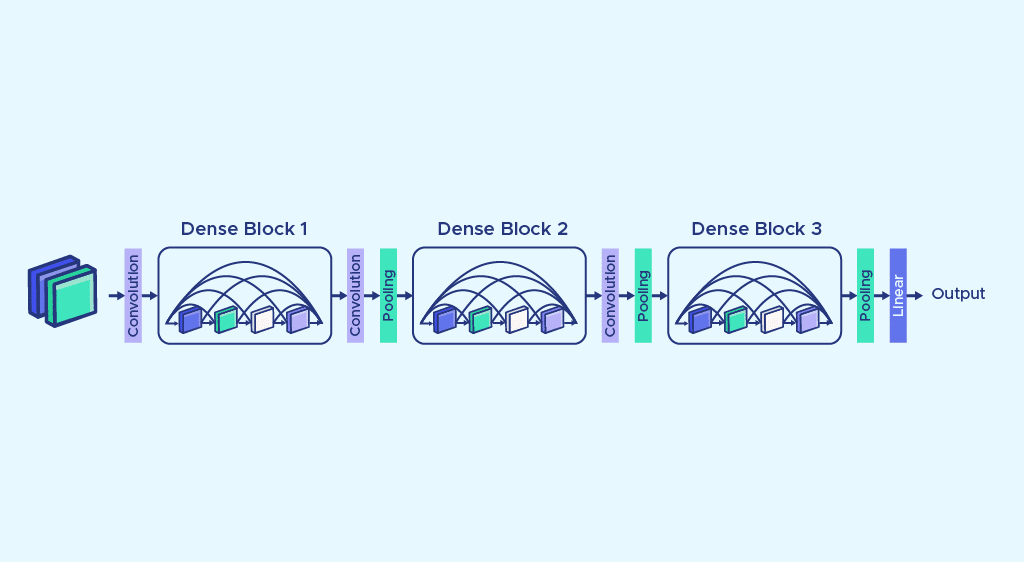
L’addition des dense blocs rend le réseau profond et peut parfois s’avérer problématique. Ceci peut être solutionné par la scission de ces blocs et par l’introduction de couches de convolution 1-by-1 qui conservent la résolution spatiale tout en réduisant la profondeur de la feature map.
Comme explicité dans la partie précédente, une couche de Pooling (MaxPool ou AvgPool) est souvent empilée à la sortie de ces couches dans le but de réduire la dimension de la feature map et de faciliter l’exploitation des données.
Il est important de noter que les feature map sont de même taille à l’intérieur de chaque bloc, ce qui rend la concatenation moins complexe.
Parmi les avantages du réseau DenseNet, nous pouvons mentionner la rétropropagation facilitée du signal d’erreur de manière directe. Nous pouvons également mettre en évidence l’efficacité computationnelle de ce système notamment grâce à la gestion du nombre de paramètres, DenseNet assure la diversité des features en comparaison avec un réseau convolutif traditionnel ainsi que leur faible complexité ce qui permet des performances optimales.
En conclusion, l’architecture de réseau DenseNet s’inscrit dans la famille des réseaux de neurones convolutifs et permet une optimisation des performances notamment dans les domaines de traitement d’images.
Sa structure singulière se compose d’un empilement de dense block, de couches de convolution et de pooling successivement. Les couches de Pooling (average ou max) permettent de garantir une restriction de la dimension des données ce qui justifie l’efficacité de traitement de ce type de réseau.
De la reconnaissance faciale jusqu’au traitement de langues naturelles, les applications du réseau convolutif DenseNet à l’AI en sont très larges.
Si vous voulez en savoir plus sur ces sujets d’applications, vous pouvez lire notre article sur le NLP et l’analyse de sentimentsou alors découvrir nos différents cursus de formation pour apprendre à maitriser ces sujets.








