
En octobre 2018 la filière d’intelligence artificielle de Google (Google AI) a publié un modèle de deep learning pré-entraîné, appelé BERT, capable de résoudre plusieurs problématiques de NLP.
Le Natural Language Processing (Traitement automatique du Langage) est un sous domaine du Machine learning qui a pour objectif de donner à des programmes informatiques la capacité de comprendre et traiter le langage humain.
Dès sa sortie BERT a attiré l’attention de la communauté de data science de par ses résultats « State-of-the-art » c’est-à-dire que, pour une grande partie des tâches de NLP, Bert offre les meilleurs résultats actuellement. Google a même avancé que ce modèle dépassait les performances humaines sur certaines tâches, ce qui est une grande étape pour tout algorithme de Machine Learning.
Le monde avant BERT :
Pour comprendre ce qu’est BERT et quelle est l’idée innovante derrière ce modèle nous allons nous baser sur une tâche typique de NLP. Prenons la phrase suivante :
« La personne va au supermarché et achète une ____ de chaussures. »
Il est clair qu’ici l’objectif est de compléter cette phrase, la réponse est évidente pour un humain, mais moins pour un algorithme.
Les modèles pré-BERT auraient regardé cette séquence de texte de gauche à droite ou bien en combinant de gauche à droite et de droite à gauche. Cette approche unidirectionnelle fonctionne bien pour générer des phrases : nous pouvons prédire le mot suivant, l’ajouter à la séquence, puis prédire le mot suivant jusqu’à obtenir une phrase complète. Ici des modèles pre-BERT donnerait environ 70% du temps le mot (paire) et le reste du temps des mots comme « caddie » ou « valise ».
Bert lui ne procède pas de cette façon. BERT signifie Bidirectional Encoder Representations from Transformers. Comme son nom l’indique ce modèle procède de façon bi-directionnel, ce qui lui permet d’avoir une bien meilleure compréhension du texte.
La méthode BERT :
Reprenons la même tâche et regardons ce que fait BERT. Au lieu de prédire le mot suivant dans une séquence, BERT utilise une nouvelle technique appelée Masked LM (MLM) : il masque aléatoirement des mots dans la phrase, puis il essaie de les prédire. Le masquage signifie que le modèle regarde dans les deux sens et qu’il utilise le contexte complet de la phrase, à gauche et à droite, afin de prédire le mot masqué. Contrairement aux modèles de langage précédents, il prend en compte les mots précédents et suivants en même temps. Les modèles existants manquaient cette approche « simultanée ».
Comment ça fonctionne techniquement ?
Bert est un modèle de type Transformers. Un transformer est un modèle qui fonctionne en effectuant un petit nombre constant d’étapes. À chaque étape, il applique un mécanisme d’attention pour comprendre les relations entre les mots de la phrase, quelles que soient leurs positions respectives. Prenons un exemple simple :
« Tu as une nouvelle souris pour ton ordinateur ? »
Pour déterminer le sens du mot souris, l’objet et non l’animal, le transformer va prêter attention au mot « ordinateur » et prendre une décision en une étape basée sur ça.
Pour permettre cela, BERT se base donc sur l’architecture des transformers, c’est-à-dire consistant en un encodeur pour lire le texte et un décodeur pour faire une prédiction. BERT se limite à un encodeur, car son objectif est de créer un modèle de représentation du langage qui sera ensuite utilisable pour des tâches de NLP. (Il permet de comprendre le langage).
Comment utiliser le BERT ?
Avant d’utiliser BERT il est crucial de faire la préparation des données suivantes :
- Tokenisation des mots et ajout de tokens de début et de fin de phrase
- Marqueur ajouté à chaque phrase pour les distinguer
Un marqueur de position est ajouté à chaque token (mots) pour indiquer sa position.
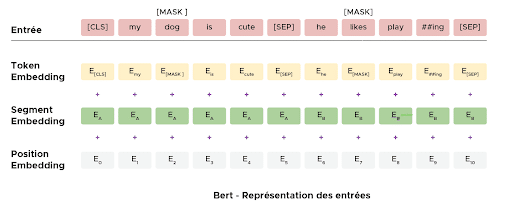
Après cela il faut choisir son modèle BERT. Il y en a plusieurs types de différentes tailles, il revient à l’utilisateur de choisir la complexité qui lui convient pour sa tâche. Enfin, il reste à importer le modèle et l’incorporer à votre architecture. Une fois ces étapes passées, il ne reste plus qu’à faire les prédictions !
BERT est un modèle de représentation du langage très puissant qui a marqué une étape importante dans le domaine du traitement automatique du langage – il a considérablement augmenté notre capacité à faire de l’apprentissage par transfert en NLP. Bert vous permettra par exemple de classifier les tweets selon le sentiment qu’ils renvoient ou encore de créer un assistant virtuel capable de répondre aux questions de façon intelligente.
Pour mieux comprendre comment fonctionne BERT et les transformers ou encore découvrir le Deep Learning et le NLP pour en faire votre métier rejoignez les formations professionnalisantes de Datascientest.








