La définition du bon modèle est primordiale pour réaliser des prédictions pertinentes en Machine Learning. Mais un mauvais ajustement des données d’apprentissage peut affecter la performance des analyses prédictives. C’est justement ce qui se passe avec l’underfitting. Alors de quoi s’agit-il ? Et comment l’éviter ? Les réponses sont ici.
Qu’est-ce que l’underfitting ?
L’underfitting est une notion incontournable du Machine Learning, puisqu’il peut être responsable d’une mauvaise performance de l’apprentissage supervisé à partir des données. Alors avant de voir plus en détail cette notion, il convient de rappeler quelques éléments essentiels du fonctionnement du Machine Learning.
Rappel sur le fonctionnement du Machine Learning
Le Machine Learning a pour objectif de prédire un pattern à partir de modèles d’apprentissage sur des données encore inconnues.
Pour cela, l’apprentissage supervisé repose sur deux idées maîtresses. À savoir :
- L’approximation : il s’agit d’entraîner des données d’apprentissage (ou training set) pour obtenir un modèle présentant un taux d’erreur le plus faible possible.
- La généralisation : suite à cet entraînement, les Data Scientists utilisent des données de validation pour tester les différents modèles. Cela permet de concevoir un modèle capable de se généraliser à de nouvelles données jamais vues auparavant.
L’idée globale est d’obtenir des niveaux d’erreur en apprentissage et en validation similaire.

L’underfitting ou le sous-apprentissage
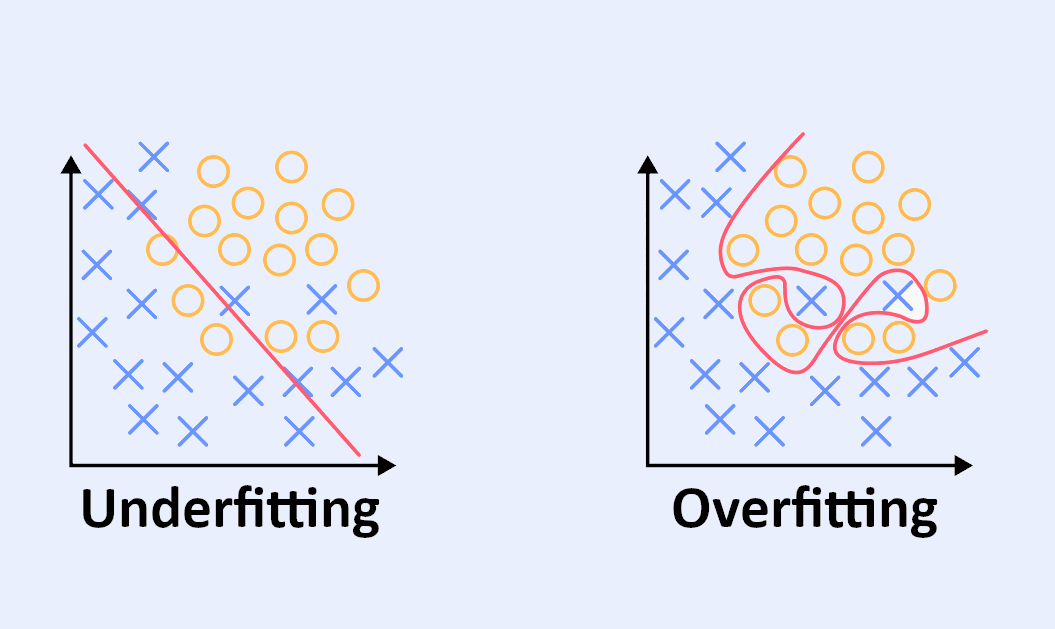
L’underfitting peut être traduit par le sous-ajustement ou le sous-apprentissage. Dans ce cas, on dit aussi que le modèle souffre d’un grand Bias (ou biais).
Cela survient lorsque l’on nomme uniquement des variables pertinentes en lien avec le problème ou lorsque l’on force le modèle à arrêter d’apprendre prématurément. Dès lors, le modèle créé est trop simpliste et risque de passer à côté de la tendance générale.
En effet, un modèle sous-ajusté s’adapte mal au training set. Il présentera des prédictions biaisées faute d’entraînement suffisant et laissera apparaître de nombreuses erreurs en phase d’apprentissage.
En d’autres termes, c’est un modèle d’apprentissage trop généraliste qui ne parvient pas à fournir des analyses prédictives précises.
Il est donc primordial de maîtriser ce concept en Machine Learning avant de concevoir des modèles adéquats. Mais avant de voir comment éviter l’underfitting, nous allons aussi étudier son contraire.
L’overfitting, antinomique de l’underfitting
À l’inverse de l’underfitting, l’overfitting se traduit par le sur-ajustement ou sur-apprentissage.
Ici, on utilise un maximum de variables pour être préparé à toutes les hypothèses. Mais attention, le risque est d’utiliser trop de variables non pertinentes par rapport à l’étude en cours.
Si cette méthode permet d’obtenir des niveaux d’erreur en apprentissage et en validation similaire, cela complexifie fortement le modèle. Ce qui implique une augmentation du nombre de paramètres à estimer. De ce fait, le modèle va détecter plus de corrélations fallacieuses.
Le modèle sur-ajusté s’attache à la mémorisation des particularités très spécifiques des données. On dit qu’il s’ajuste au bruit dans les données. À terme, il trouvera des liens de causalité entre des données qui n’ont aucun rapport. Il pourra alors se montrer très performant sur les données d’apprentissage, mais cela au détriment de la tendance générale.
Comment éviter l’underfitting ?
L’enjeu pour les Data Scientists est de concevoir le modèle adéquat, ni trop simple, ni trop complexe. À savoir, éviter l’underfitting, sans tomber dans l’overfitting.
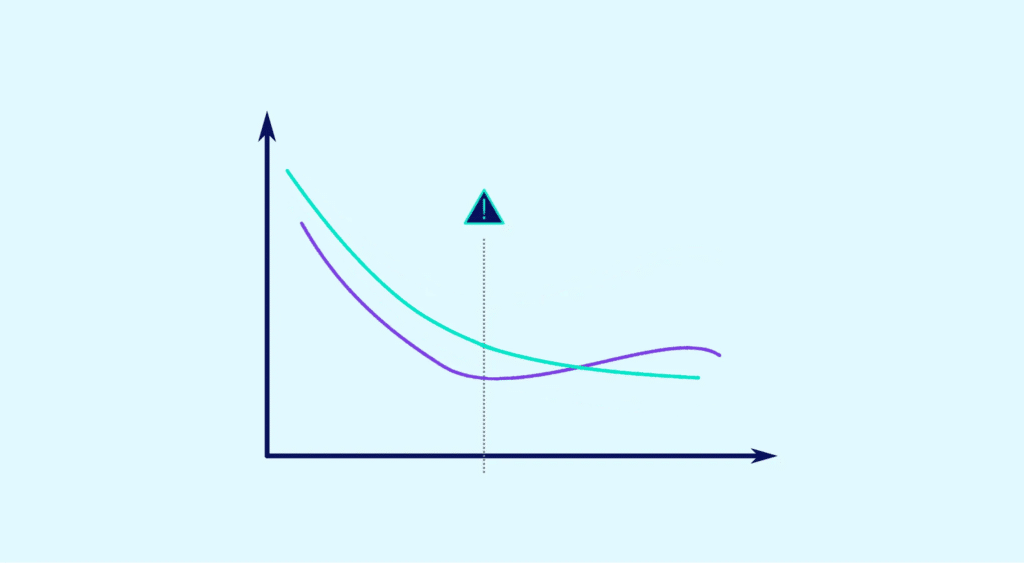
Pour cela, il convient d’identifier le sweet spot permettant de trouver le juste équilibre. Mais avant cela, vous devez apprendre à détecter l’underfitting et l’overfitting.
Si les données de test ont un faible taux d’erreur, mais que les données d’entraînement ont un taux d’erreur élevé, il y a probablement un sous-ajustement.
Dans ce cas, attention à ne pas trop complexifier le modèle. Ici, c’est la situation inverse qui se produira, à savoir : des données d’entraînement avec un faible taux d’erreur et des données de tests avec un taux d’erreur élevé. L’overfitting est caractérisé.
Dès lors que vous êtes en mesure d’identifier l’un ou l’autre, vous pouvez affiner le modèle prédictif lors de la phase d’apprentissage. Cela permet de réduire progressivement les erreurs sur le training set.
Les Data Scientists doivent continuer à affiner le modèle jusqu’à ce que les erreurs augmentent dans la phase de validation. L’équilibre se situe juste avant que ces erreurs n’augmentent à cette étape.
En appliquant cette méthode, vous pourrez détecter la tendance dominante et l’appliquer largement aux nouveaux ensembles de données.
DataScientest pour maîtriser les modèles de Machine Learning
Trouver le juste équilibre entre l’underfitting et l’overfitting nécessite de la pratique et des connaissances accrues en analyse des données.
C’est justement pour cette raison que DataScientest propose différentes formations en Machine Learning. N’hésitez pas à consulter nos programmes.








