Data Science
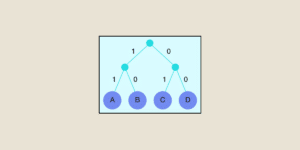
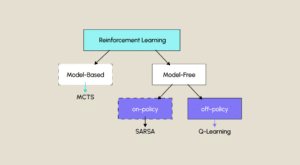
SARSA : Comment ça fonctionne en Machine Learning ?
Le Reinforcement Learning, ou apprentissage par renforcement en français, est, avec les apprentissages supervisé et non supervisé, l’une des trois grandes techniques d’apprentissage automatique. Cette