
Dans son article de recherche publié en mars 2021, Yann LeCun, vice-président et scientifique en chef de l’intelligence artificielle chez Facebook, décrit l’apprentissage auto-supervisé comme “l’un des moyens les plus prometteurs de construire des machines dotées de connaissances de base, ou de “bon sens”, pour s’attaquer à des tâches qui dépassent de loin les capacités de l’IA d’aujourd’hui”.
Cette méthode, vue comme « la matière noire de l’intelligence », étiquette les données de manière automatique. Ainsi, elle semble très prometteuse, à une époque où disposer de données étiquetées se révèle coûteux.
Comment fonctionne l’apprentissage auto-supervisé ?
L’apprentissage auto-supervisé se base sur un réseau de neurones artificiels et peut être considéré à mi-chemin entre l’apprentissage supervisé et non supervisé. Il a l’avantage majeur de traiter des données non-étiquetées et de générer automatiquement les étiquettes associées, sans intervention humaine. Cette méthode fonctionne en masquant une partie des données d’apprentissage et en entraînant le modèle à identifier ces données cachées. Cette identification se fait en analysant la structure et les caractéristiques des données qui n’ont pas été occultées. Ces données labellisées sont ensuite utilisées pour l’étape d’apprentissage supervisé.
Quelles sont ses différences avec l’apprentissage supervisé et le non supervisé et ses avantages ?
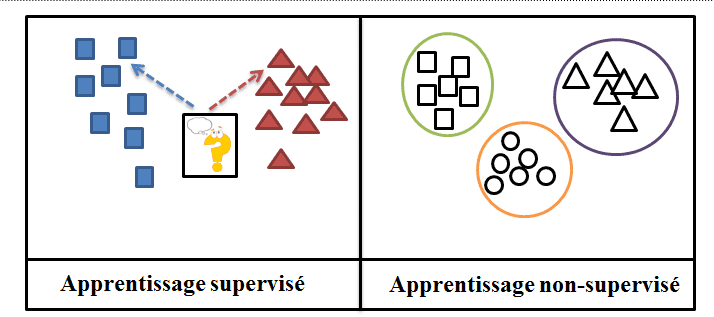
Les méthodes d’apprentissage supervisé disposent de labels prédéfinis. Souvent ces labels ont été attribués grâce à l’intervention humaine. Or ce travail d’étiquetage est souvent assez chronophage et coûteux, les données étiquetées sont rares de ce fait. D’autant plus que les algorithmes d’apprentissage automatique nécessitent souvent une quantité massive de données au préalable, pour permettre de fournir des résultats précis.
Dans certains domaines comme la médecine par exemple, ce travail d’étiquetage nécessite des connaissances spécifiques, rendant cette tâche d’autant plus complexe. En proposant une alternative à ce travail redondant, l’apprentissage auto-supervisé se place ainsi en haut du tableau.
D’autres méthodes permettent également de contourner le problème d’étiquetage des données notamment l’apprentissage semi-supervisé qui travaille majoritairement avec des données non-étiquetées auxquelles s’ajoutent une petite partie de données étiquetées.
L’apprentissage auto-supervisé peut s’apparenter à une sous-catégorie de l’apprentissage non supervisé, car les deux approches travaillent avec des jeux de données non-étiquetées. Cependant, l’apprentissage non supervisé diffère dans son but, il se focalise exclusivement sur le regroupement des données et la réduction des dimensions. Au contraire, le but final de l’apprentissage auto-supervisé est de prédire une sortie classifiée.
Un autre avantage de l’apprentissage auto-supervisé réside dans une compréhension plus profonde des données et des motifs et structures les composant. Les représentations apprises sont ainsi facilement généralisables.
L’apprentissage auto-supervisé dans le traitement naturel du langage
Dans le cas du Natural Language Processing (NLP), on utilise l’apprentissage auto-supervisé en entraînant le modèle sur des phrases auxquelles on a oté aléatoirement des mots. Il doit alors prédire ces mots enlevés. Cette méthode appliquée au NLP s’est révélée efficace et très pertinente. Par exemple, les modèles wav2vec et BERT développées respectivement par Facebook et Google AI font partie des plus révolutionnaires en NLP. Wav2vec a fait ses preuves dans le domaine de la reconnaissance de la parole ou Automatic Speech Recognition (ASR).
Ainsi, certaines parties des audios sont masquées et le modèle est entraîné à prédire ces parties. BERT, acronyme pour Bidirectional Encoder Representations from Transformers, est un modèle de Deep Learning qui offre actuellement les meilleurs résultats pour la plupart des tâches de NLP. Contrairement aux modèles établis avant lui, qui parcouraient le texte de manière unidimensionnelle pour prédire le mot suivant, l’algorithme BERT cache des mots aléatoirement dans la phrase et essaie de les prédire. Pour cela, il utilise le contexte complet de la phrase, à gauche et à droite.

Du NLP à la Computer Vision
Après avoir fait ses preuves en traitement naturel du langage, l’apprentissage auto-supervisé s’est également imposé en Computer Vision. Facebook AI a présenté un nouveau modèle basé sur l’apprentissage auto-supervisé, appliqué à la Computer Vision nommé SEER (pour SElf-supERvised). Il a été entraîné sur un milliard d’images issues d’Instagram non étiquetées. Le modèle a ainsi atteint un taux de précision record de 84,2% sur la base de données d’images ImageNet.
En Computer Vision, l’apprentissage auto-supervisé a également été largement utile pour la colorisation d’images, la rotation 3D et le remplissage de contexte.
Quelles sont les limites de l’apprentissage auto-supervisé ?
La construction de modèle peut être plus gourmande en temps de calcul. En effet, étant donné que l’apprentissage auto-supervisé génère de lui-même les étiquettes associées aux données, cela ajoute du temps de calcul supplémentaire en comparaison à un modèle d’apprentissage avec étiquettes.
L’apprentissage auto-supervisé se révèle utile lorsque l’on dispose d’un jeu de données non étiquetées et que nous devons les attribuer manuellement. Cependant, cette méthode peut générer des erreurs lors de l’étiquetage causant des résultats inexacts.
Conclusion
L’apprentissage auto-supervisé constitue un pas de plus vers une intelligence artificielle dotée d’un « bon sens ». En travaillant avec des données non-étiquetées, cette méthode solutionne la tâche longue et fastidieuse que constitue la labellisation des données. Elle ouvre alors de nouvelles approches révolutionnaires dans de nombreux domaines de l’intelligence artificielle comme le NLP ou la Computer Vision.
Si vous souhaitez en savoir plus sur les algorithmes de Machine Learning et Deep Learning, n’hésitez pas à consulter notre offre de formations aux métiers de la data.










