Data Science
Data Exploration ou exploration de données : définition, outils, formations…
La Data Exploration ou exploration de données est la première étape de l’analyse de données. Découvrez tout ce que vous devez savoir à ce sujet,
La Data Exploration ou exploration de données est la première étape de l’analyse de données. Découvrez tout ce que vous devez savoir à ce sujet,

Dans cet article, vous allez découvrir une dizaine de fonctions natives Python (buit-in) qui vous seront à coup sûr très utiles ! Vous démarrez en Python ? N’hésitez
Le domaine de l’apprentissage automatique (plus communément appelé Machine Learning) comprend des problématiques d’apprentissage supervisé, non supervisé et semi-supervisé. Si vous souhaitez en savoir plus

La Data Science est une véritable révolution pour l’industrie de l’aéronautique et le secteur aérien. Découvrez comment les données sont exploitées par les compagnies aériennes
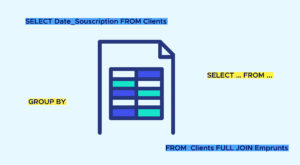
Le SQL ou « Structured Query Language » est un langage de programmation aujourd’hui quasiment indispensable pour gérer des bases de données. (Retrouvez la fiche mémo SQL).
Table des matières: Episode 1 – Introduction –Variables –types Episode 2–Opérateurs–Boucles–Fonctions Episode 3 – Import des données –Data cleaning – Data processing Episode 4 Import

Aujourd’hui nous nous retrouvons pour un deuxième article pour apprendre à trouver des jeux de données (ou datasets en anglais) pour entraîner vos algorithmes de

L’algorithme des K plus proches voisins ou K-nearest neighbors (kNN) est un algorithme de Machine Learning qui appartient à la classe des algorithmes d’apprentissage supervisé
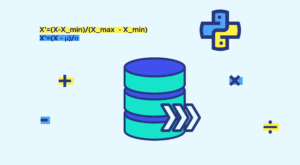
Table des matières: Episode 1 – Introduction –Variables –types Episode 2–Opérateurs–Boucles–Fonctions Episode 3 Import des données Data Cleaning Data processing Episode 4 – Import des bibliothèques
La réalisation de jeux fait partie des applications populaires des méthodes d’intelligence artificielle. 2019 a vu naitre l’un des jeux les plus intéressants qui utilisent

Si vous vous intéressez un tant soit peu au Machine Learning et aux problèmes de classification, vous avez déjà dû avoir affaire au modèle de
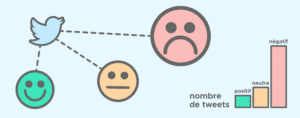
Aujourd’hui, Twitter est utilisé par des centaines de millions de personnes dans le monde entier. Plus précisément, l’estimation actuelle s’élève à environ 330 millions d’utilisateurs
