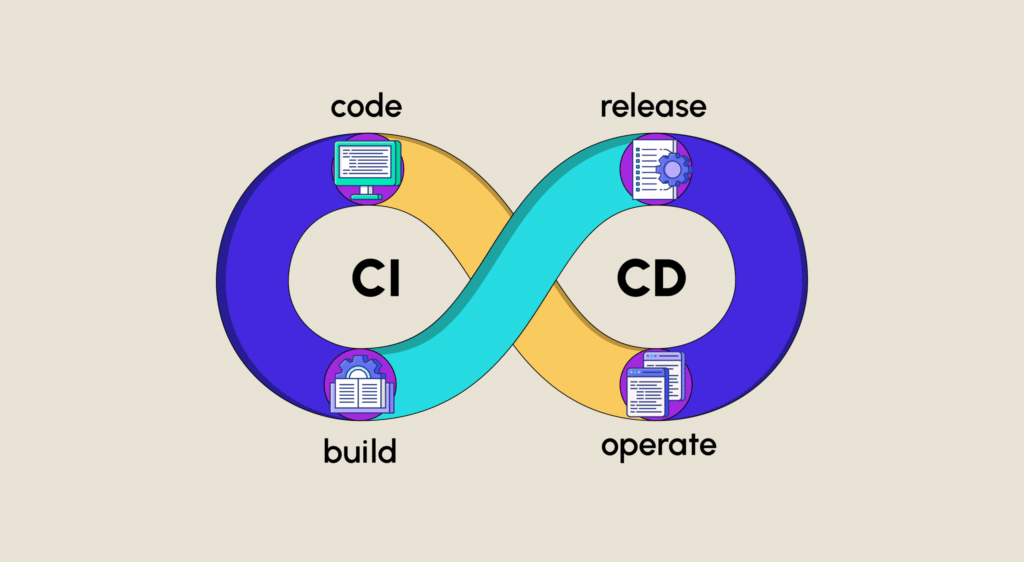
L’Intégration Continue (CI) et la Livraison Continue (CD) regroupent un ensemble de principes et de pratiques permettant aux équipes de développement d’apporter des changements au code informatique de façon plus fiable et plus fréquente.
L’implémentation du CI/CD est au coeur des méthodologies de développement agile et DevOps. Elle permet aux équipes de développement logiciel de se focaliser sur les besoins de l’entreprise, la qualité du code et la cybersécurité. Les étapes de déploiement sont automatisées.
Qu'est-ce que le CI/CD ?
L’Intégration Continue est une philosophie et un ensemble de pratiques consistant pour les équipes de développement à implémenter les changements progressivement et à vérifier fréquemment le code avant un ajout.
Les applications modernes reposent sur différents outils et plateformes de code. Par conséquent, les équipes ont besoin d’un mécanisme permettant d’intégrer et de valider les changements.
Le but de l’Intégration Continue est de mettre en place une façon automatisée de construire et de tester les applications. La constance du processus d’intégration permet aux équipes d’apporter des changements au code plus fréquemment. La collaboration est donc améliorée, au même titre que la qualité finale du logiciel.
La Livraison Continue ou CD est l’étape suivante. Elle automatise la livraison d’applications aux environnements d’infrastructure sélectionnés. Là encore, le but est d’harmoniser la livraison du code entre les différents environnements de production, de développement ou encore de testing sur lesquels travaillent simultanément la plupart des équipes de développement.
Les outils CI/CD permettent d’entreposer les paramètres spécifiques à chaque environnement, et l’automatisation permet ensuite d’effectuer les appels nécessaires vers les serveurs web, bases de données et autres services nécessitant des procédures comme un redémarrage lors du déploiement d’applications.
L’Intégration Continue et la Livraison Continue requièrent un Testing Continu. Cette procédure permet de s’assurer que la qualité du code et de l’application soit maintenue.
Comment fonctionne la CI ?
La philosophie d’Intégration Continue repose sur des mécanismes et sur l’automatisation. Les développeurs déposent fréquemment leur code dans un dossier de contrôle de version, afin de simplifier la détection de défauts et autres problèmes de qualité sur des petits morceaux de code. Cette approche réduit aussi le risque que plusieurs développeurs éditent le même code simultanément.
Différentes techniques sont utilisées par les équipes de développement CI pour contrôler le code et les fonctionnalités. On peut citer la technique de Feature Flags, ou celle du Version Control Branching. Après cette étape de validation, le code est envoyé en production.
Le processus de build est automatisé par le packaging de tout le logiciel, les bases de données et autres composants. L’exécution des tests est aussi automatisée, pour apporter un feedback aux développeurs sur les changements apportés au code.
De nombreux outils CI/CD permettent aux développeurs de créer des builds sur demande, en déposant du code dans le dossier de contrôle de version ou à une date définie. La stratégie d’intégration doit être discutée par l’équipe, notamment concernant la fréquence des builds et des dépôts de code.
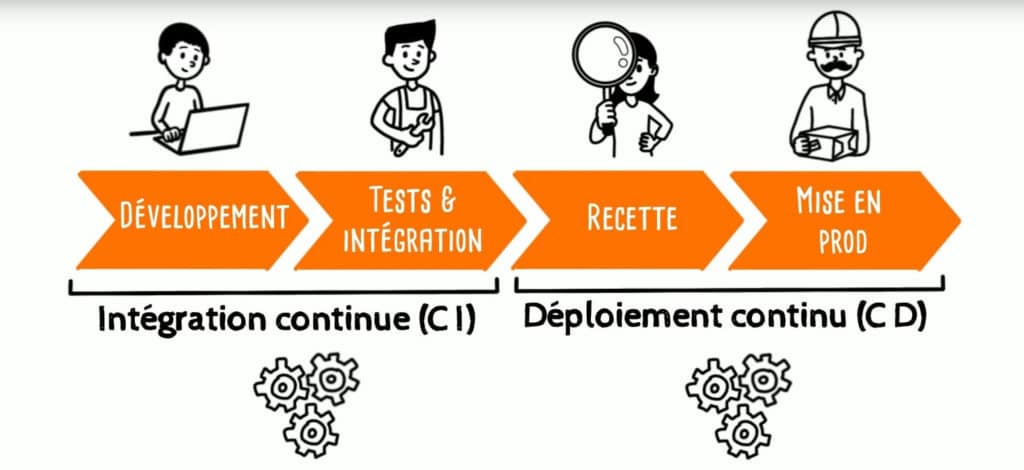
Comment fonctionne la CD ?
La Livraison Continue automatise le » push » des applications vers les environnements de livraison. Des outils comme Jenkins, CircleCI, AWS CodeBuild, Azure DevOps ou Atlassian Bamboo permettent d’automatiser les étapes de testing et d’évaluation des changements apportés aux applications.
Habituellement, le pipeline de Livraison Continue est décomposé en plusieurs étapes de build, de test et de déploiement. Des étapes supplémentaires peuvent être ajoutées comme l’extraction du code en provenance du dossier de contrôle de version, le transfert du code, le pushing des composants d’applications vers les services appropriés ou le testing continu.
Au sein des environnements Cloud, les pipelines CI/CD utilisent aussi les conteneurs logiciels comme Docker et les systèmes d’orchestration comme Kubernetes. Les architectures serverless sont aussi très utilisées, et consistent à laisser le fournisseur de service Cloud gérer l’infrastructure. L’application consomme les ressources en fonction de ses besoins.
Quels sont les avantages du CI/CD ?
L’intégration et la livraison continue permettent une meilleure collaboration, et une productivité accrue. La qualité du code s’en trouve améliorée grâce à un meilleur contrôle, et la qualité du logiciel final est également renforcée.
Par ailleurs, les pipelines CI/CD permettent aux entreprises d’améliorer fréquemment leurs applications tout en s’appuyant sur un processus de livraison fiable. La standardisation des builds, les tests, l’automatisation du déploiement laissent les équipes se focaliser sur l’amélioration des applications plutôt que sur des détails techniques.
Cette pratique est idéale pour la méthode DevOps, car elle évite un mauvais alignement entre des développeurs désirant pousser le code trop fréquemment et les équipes ops en quête de stabilité des applications. L’automatisation permet de pousser des changements de code plus fréquemment, tandis que les configurations standardisées et le testing continu améliorent la stabilité.
CI/CD et Data Science
Comme dans le domaine du développement logiciel, le CI/CD est utilisé dans le domaine de la Data Science pour transférer les données en production. Cette approche permet un déploiement automatique.
Les processus de Data Science sont construits par différents experts en collaboration comme les Data Engineers, les experts en Machine Learning et les spécialistes de la visualisation. Ils consistent à appliquer des algorithmes de Machine Learning aux données.
Dans ce domaine, l’intégration consiste généralement à assembler les pièces sous-jacentes. Ceci permet de s’assurer que les bibliothèques d’un toolkit spécifique ou les bonnes versions d’un module soient bien comprises dans le processus de Data Science final.
Pendant le développement, les fonctions sont générées et le modèle est entraîné. Pendant l’intégration, le processus de génération de fonctions optimisées est combiné avec le modèle entraîné. L’intégration comprend aussi le processus de production.
Le déploiement continu en Data Science est similaire à celui du développement logiciel, et consiste à remplacer automatiquement une application existante ou une API. On retrouve la capacité de restaurer une version précédente en cas de problème pendant la production.
Pendant le processus de production Data Science, les performances du modèle doivent être surveillées en continu. La détection de changement est cruciale, et doit être assurée par des mécanismes. Les modèles peuvent ensuite être automatiquement ré-entraînés et redéployés, tandis que l’équipe Data Science peut être alertée pour créer un nouveau processus.
Git et GitHub
Le contrôle de version est au coeur de l’approche CI/CD. Il consiste à sauvegarder tout changement apporté à un projet de développement logiciel ou de Data Science, dans le but de pouvoir revenir en arrière en cas d’erreur ou de problème. Il est toujours possible de restaurer une version précédente.
Développé en 2005, Git est un système de contrôle de version extrêmement populaire. Installé et maintenu sur un système local, il permet de sauvegarder les versions sans même avoir besoin d’accéder à internet.
Ce système se distingue par sa réactivité, sa simplicité d’utilisation et sa gratuité. Il fonctionne particulièrement bien avec les fichiers textes comme le code informatique. Son véritable point fort est toutefois son modèle de branching, permettant de créer des branches locales indépendantes au sein du code. Ceci permet de tester de nouvelles idées sans forcément les mettre en production.
Le service d’hébergement et de dépôt de code GitHub permet de partager des projets de contrôle de version Git en ligne, au-delà de l’ordinateur ou du serveur local. Ce service est entièrement basé sur le Cloud.
L’interface utilisateur graphique de GitHub est extrêmement intuitive, et offre des outils natifs de gestion de tâche et de contrôle pour les programmeurs. Une marketplace permet d’implémenter des fonctionnalités additionnelles.
Ainsi, le service GitHub permet de partager du code et de collaborer avec d’autres utilisateurs sur un même projet de logiciel ou de Data Science. Chaque changement introduit crée une nouvelle branche, et chaque membre de l’équipe peut donc travailler en simultané sans interférer avec les progrès des autres.
Comment se former au CI/CD ?
L’intégration continue et la livraison continue sont désormais très utilisées en entreprise, pour le développement logiciel ou la Data Science. Il s’agit d’une compétence très recherchée en entreprise. Afin de maîtriser le CI/CD, vous pouvez choisir DataScientest.
Notre formation Data Engineer comporte un module CI/CD abordant notamment Git, GitHub et l’assurance qualité. Les autres modules du programme couvrent la programmation en Python, les bases de données, la Data Science, le Big Data, l’automatisation et le déploiement.
À l’issue du cursus, vous aurez toutes les compétences requises pour devenir Data Engineer. Vous serez en mesure de stocker, transformer et transmettre de larges volumes de données, de déployer des modèles de Machine Learning pour une mise en production, et de créer des pipelines de traitement de la Data en streaming.
Ce parcours à distance peut se compléter en Formation Continue de 9 mois, ou en mode BootCamp intensif de 11 semaines. Notre approche Blended Learning combine coaching individuel sur notre plateforme en ligne, et Masterclass.
Finir ce programme permet d’obtenir un certificat délivré par MINES ParisTech / PSL Executive Education dans le cadre de notre partenariat. Parmi nos alumnis, 80% ont trouvé un emploi immédiatement.
Cette formation est accessible avec un Bac+3 en mathématiques ou un Bac+5 en sciences, ainsi qu’une compréhension du langage SQL et des systèmes Linux. Concernant le financement, toutes nos formations sont éligibles au CPF. N’attendez plus et découvrez la formation Data Engineer !
Vous savez tout sur le CI/CD. Pour plus d’informations, découvrez notre dossier complet sur Git et notre dossier sur le DevOps.







