
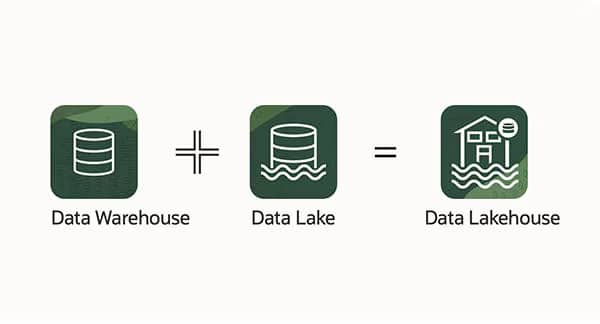
Um ihre Datenverwaltung und -analyse zu optimieren, setzen Unternehmen in der Regel zwei Data-Science-Lösungen ein, den Data Lake und das Data Warehouse. Diese beiden Technologien bieten zahlreiche Möglichkeiten zur Datenanalyse und -sicherung. Ein neues System bietet jedoch die Möglichkeit, die Stärken dieser beiden Methoden in einer einzigen Software, dem Data Lakehouse, zu verschmelzen.
In diesem Artikel erfährst du, welche Funktionen dieser neue Ansatz bietet und welche Vorteile es hat, ihn in dein Geschäft zu integrieren.
Was ist ein Data Lakehouse?
Ein Data Lakehouse ist eine Datenarchitektur, die die traditionellen Schwächen von Data Warehouses (Datenlager) und Data Lakes (Datenseen) beheben soll. Im Gegensatz zu Data Warehouses, die für große strukturierte Abfragen optimiert sind, und Data Lakes, die für die Speicherung unstrukturierter Rohdaten konzipiert sind, verbindet das Data Lakehouse beide Ansätze zu einer einheitlichen Plattform für die Datenspeicherung und -analyse. Mit ihm können Unternehmen ihre Daten leichter für Business Intelligence (BI) oder Machine Learning (ML) nutzen.
Was sind die Unterschiede zwischen einem Data Lake und einem Data Warehouse?
Das Data Warehouse :
📌Ein Data Warehouse funktioniert wie ein zentrales Verzeichnis. Die Informationen stammen aus einer oder mehreren Datenquellen, z. B. aus einem Transaktionssystem oder anderen relationalen Datenbanken. 📌
Die Daten können strukturiert, halbstrukturiert oder unstrukturiert sein. Sobald sie in das Warehouse eingepflegt sind, werden sie verarbeitet und umgewandelt. Die Nutzer können dann mithilfe von Business-Intelligence-Tools, SQL-Clients oder Tabellenkalkulationen darauf zugreifen.
Durch das Zusammenfassen von Informationen an einem Ort kann ein Unternehmen einen Überblick über seine Kunden oder andere wichtige Elemente erhalten. Das Warehousing stellt sicher, dass alle Informationen durchgesehen werden.
Darüber hinaus ermöglicht das Data Warehouse das sogenannte Data Mining. Bei diesem Verfahren werden die Daten nach Trends und Mustern durchsucht und darauf aufgebaut, um den Umsatz und die Einnahmen des Unternehmens zu steigern.
Der Data Lake:
👉Ein Data Lake kann Daten aus verschiedenen Quellen wie Datenbanken, Webservern oder verbundenen Objekten mithilfe von Konnektoren integrieren. Sie können als Stapel oder in Echtzeit geladen werden.
Der von einem Data Lake angebotene Speicher ist skalierbar und ermöglicht einen schnellen Zugriff für Data Mining. Sobald die Daten gespeichert sind, können die Daten in eine strukturierte Form umgewandelt werden, um die Analyse zu erleichtern. Sie können mit Tags versehen werden, um ihnen Metadaten zuzuordnen.
👉Man kann dann SQL- oder NoSQL-Abfragen oder sogar die Excel-Software verwenden, um die Daten zu analysieren. Sobald das Unternehmen eine Frage hat, kann eine Abfrage im Data Lake durchgeführt werden, wobei nur eine Teilmenge der relevanten Daten analysiert wird.
Der Data Lake ermöglicht auch die Verwaltung und Steuerung der Daten.
Das Data Lakehouse:
Data Lakehouses basieren auf einem innovativen Design. Es verfügt über ähnliche Strukturen und Datenverwaltungsfunktionen wie ein Data Warehouse und wird direkt in einen kostengünstigen Data-Lake-Speicher implementiert.
Durch diese Verschmelzung können die Teams die Daten auswerten, ohne auf mehrere Systeme zugreifen zu müssen, was ihre Arbeit erheblich beschleunigt.
👍Ein weiterer Vorteil von Data Lakehouses ist, dass die Mitarbeiter immer die vollständigsten und aktuellsten Daten für alle ihre Data Science-, Machine Learning- und Business Analytics-Projekte zur Verfügung haben.
Woraus besteht ein Data Lakehouse?
Ein Data Lakehouse besteht aus zwei Hauptschichten.
Die Lakehouse-Schicht verwaltet die Speicherung der Daten im Data Lake, sodass die Verarbeitungsschicht die Daten im Speicher mithilfe verschiedener Tools direkt abfragen kann, ohne dass die Daten in ein Data Warehouse geladen oder in ein proprietäres Format umgewandelt werden müssen.
Die Daten können dann von Business-Intelligence-Anwendungen oder von Tools für künstliche Intelligenz und Machine Learning genutzt werden.
Diese Architektur bietet die Kosteneffizienz eines Data Lake, indem sie es jeder Art von Verarbeitungsmaschine ermöglicht, diese Daten zu lesen. Organisationen haben dann die Möglichkeit, die aufbereiteten Daten zu analysieren. Auf diese Weise kann die Verarbeitung und Analyse mit besserer Leistung und zu geringeren Kosten erfolgen.
Die Architektur ermöglicht es auch mehreren Parteien, gleichzeitig Daten im System zu lesen und zu schreiben, da sie Datenbanktransaktionen unterstützt, die den ACID-Prinzipien (Atomarität, Konsistenz, Isolation und Nachhaltigkeit) entsprechen:
- Atomarität bedeutet, dass bei der Verarbeitung von Transaktionen entweder die gesamte Transaktion erfolgreich ist oder nichts erfolgreich ist. Dadurch wird verhindert, dass Daten verloren gehen oder beschädigt werden, wenn ein Prozess unterbrochen wird.
- Konsistenz sorgt für einen vorhersehbaren und logischen Ablauf der Transaktionen. Sie stellt sicher, dass alle Daten nach bestimmten Regeln gültig sind, wobei die Datenintegrität gewahrt bleibt.
- Die Isolation stellt sicher, dass eine Transaktion nicht von einer anderen Transaktion beeinflusst werden kann, solange sie nicht abgeschlossen ist. Dadurch können mehrere Parteien im selben System lesen und schreiben, ohne dass sie sich gegenseitig stören.
- Nachhaltigkeit gewährleistet, dass Änderungen an Daten in einem System, die nach einer Transaktion vorgenommen werden, auch dann bestehen bleiben, wenn das System ausfällt. Alle Änderungen, die aus einer Transaktion resultieren, werden dauerhaft gespeichert.

Was sind die Vorteile eines Data Lakehouse? 🧐
- 👉Extreme Flexibilität: Data Lakehouses ermöglichen die Speicherung von rohen, halbstrukturierten und strukturierten Daten, ohne dass vordefinierte Schemata erforderlich sind. Dies bietet eine außergewöhnliche Flexibilität, um verschiedene Daten aufzunehmen und zu erforschen, ohne die Einschränkungen traditioneller Data Warehouses.
- 👉Verbesserte Leistung: Im Gegensatz zu Data Lakes enthalten Data Lakes Funktionen zur Indexierung und Abfrageoptimierung, wodurch die Analyseleistung erheblich verbessert wird. Die Daten können schneller verarbeitet werden, was zu schnelleren geschäftlichen Erkenntnissen führt.
- 👉Vereinheitlichung der Daten: Data Lakehouses beseitigen die Datenfragmentierung, indem sie einen Konvergenzpunkt bieten, an dem verschiedene Datensätze gespeichert und durchsucht werden können. Dies fördert eine ganzheitliche Sicht auf das Unternehmen, indem es den Nutzern ermöglicht, von einer einzigen Plattform aus auf relevante Informationen zuzugreifen.
- 👉Fundierte Entscheidungsfindung: Durch die Fähigkeit, Rohdaten zu speichern und in verwertbare Informationen umzuwandeln, können Unternehmen fundiertere Entscheidungen treffen, die auf konkreten Daten beruhen. Analysen können auf der Grundlage von Echtzeitdaten durchgeführt werden, was in der heutigen Geschäftswelt von entscheidender Bedeutung ist.
- 👉Skalierbarkeit: Data-Lakehouse-Architekturen sind so konzipiert, dass sie sich an die wachsenden Anforderungen an Datenspeicherung und -analyse anpassen lassen. Sie können leicht skaliert werden, um große Datenmengen zu verwalten, ohne die Leistung zu beeinträchtigen.

Du weißt jetzt alles, was du über Data Lakehouses wissen musst. Data Lakehouses sind eine Lösung für die Verwaltung und Analyse von Daten der nächsten Generation, die die Flexibilität von Data Lakes mit der optimierten Leistung traditioneller Data Warehouses verbindet.
Wenn dir dieser Artikel gefallen hat und du eine Karriere in der Datenwissenschaft und der Entwicklung von Algorithmen der nächsten Generation in Betracht ziehst, dann schau dir auch unsere Kurse auf DataScientest an.







