
Am 23. Februar 2021 hielt Alexandre Laloo, Data Product Manager bei sennder, ein Webinar für unsere Community über die Nutzung von Daten in Startups.
Replay (Auf Französisch - Aber die Erklärungen auf Deutsch findet Ihr im Text! 💡 )
Alexandre Laloo und sennder
Alexandre Laloo, Absolvent einer namhaften Business School, kam 2017 zu Everoad, als das Unternehmen nur etwa 20 Mitarbeiter hatte. Das Startup, das sich auf die Digitalisierung des Straßengüterverkehrs spezialisiert hat, fusionierte 2020 mit sennder, seinem deutschen Konkurrenten. Das Unternehmen, das den Markennamen von sennder beibehalten hat, hat heute mehr als 700 Mitarbeiter und hat mehr als 260 Millionen Euro aufgebracht. Alexandre hat also das Wachstum des Unternehmens und die Entwicklung seiner Herangehensweise an Daten miterlebt.
Als Betriebsmanager war es seine Aufgabe, die Aktivitäten des Unternehmens anhand der von ihm gesammelten Daten zu analysieren. Seine aktuelle Position als Data Product Manager besteht darin, die Analytics Roadmap zu leiten, d. h. dafür zu sorgen, dass die Daten innerhalb des Unternehmens gut verbreitet werden.
Datenverarbeitung in Startups
1. Die Beziehung eines Unternehmens zu Daten hängt von seinem Markt ab
Der Begriff „Startup“ wird in den Nachrichten häufig verwendet und umfasst sehr unterschiedliche Unternehmenstypologien. Die Verwendung von Daten in diesen Organisationen kann nicht verallgemeinert werden, da sie für die Bewältigung der Probleme jedes Sektors verarbeitet werden. In einigen Bereichen, wie z. B. Gaming oder Travel Tech, sind Daten von Anfang an eine Priorität, da das Unternehmen sie braucht, um seinen Markt und sein Produkt zu verstehen. In anderen Branchen ist der Bedarf an Data Analysts oder Machine Learning Engineers zu Beginn ihrer Tätigkeit weniger wichtig. Zum Beispiel hat sennder in den ersten drei Jahren seines Bestehens keinen Machine Learning Engineer eingestellt.
Der Markt jedes Startups wird somit seinen Datenbedarf bestimmen, d. h. den Anteil des Budgets, der für Daten aufgewendet wird, um einerseits Experten (Product Manager, Data Analysts, Data Scientists oder Data Engineers) einzustellen und andererseits leistungsfähige Analyse- und Verarbeitungswerkzeuge zu beschaffen. Die Integration einer Unternehmens-Cloud stellt nämlich eine erhebliche Investition dar.
Die Priorität der Daten für ein Startup wird von mehreren Kriterien abhängen:
- Die Art des Produkts: mobile App, Website, physisches Produkt, etc.
- Der Markt: Transport, Lebensmittel, Finanzen, etc.
- Die Menge der verfügbaren Daten
- Die Datenkultur des Unternehmens: Auch wenn Daten ab einem bestimmten Wachstumsniveau unverzichtbar werden, hängen die Investitionen auch von diesem Faktor ab.
2. Finanzierungszyklen von Start-ups
Neben dem Markt, auf dem ein Unternehmen tätig ist, bestimmt auch seine Reife, die sich anhand von Finanzierungszyklen ermitteln lässt, wie es mit seinen Daten umgeht.
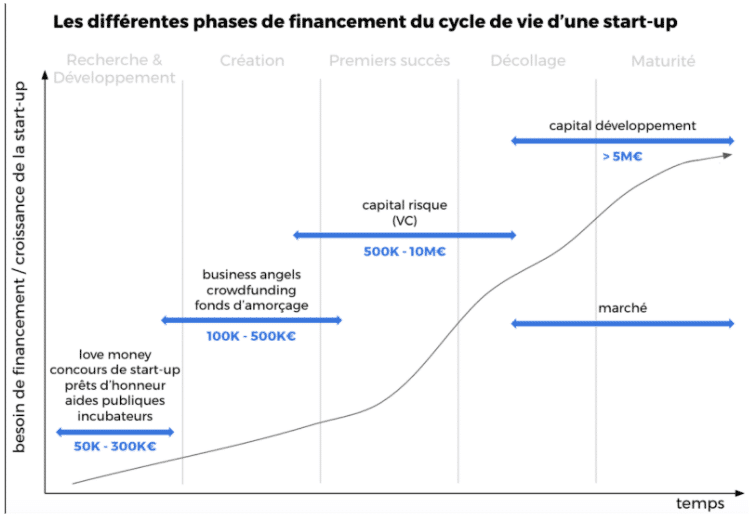
Neben dem Markt, auf dem ein Unternehmen tätig ist, bestimmt auch seine Reife, die sich anhand von Finanzierungszyklen ermitteln lässt, wie es mit seinen Daten umgeht.
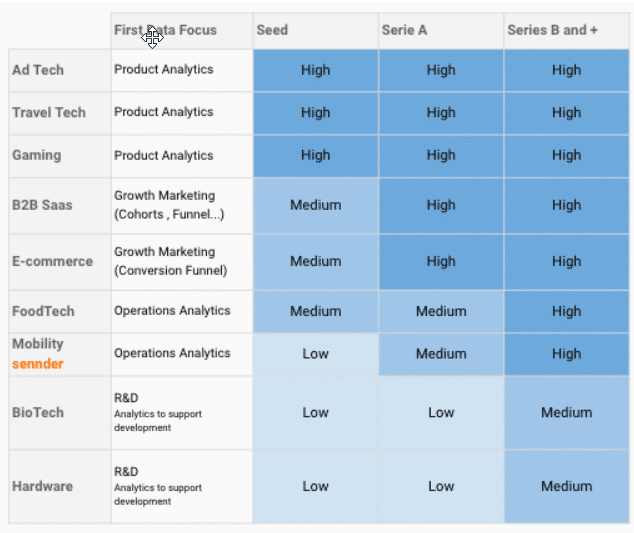
Für eine E-Commerce-Website zum Beispiel ist der Bedarf „mittel“, da ihre Priorität darin besteht, in digitales Marketing zu investieren, um loszulegen. Seine Datenstrategie wird sich auf die Analyse von Marketingkampagnen und deren Leistung (z. B. Berechnung des ROI) konzentrieren.
Die Entwicklung der Werkzeuge: von Spreadsheets zu Data Warehouses
In diesem Teil wird die Entwicklung der von Everoad und sennder verwendeten Probleme und Werkzeuge von 2017 bis heute dargestellt.
Zu Beginn ihrer Tätigkeit war das von Everoad gesammelte Datenvolumen relativ gering und die Priorität des Unternehmens lag nicht auf der Analyse von Daten, sondern auf der Entwicklung ihres Straßengüterverkehrsgeschäfts.
Heute stellt Machine Learning eine wichtige Investition für sennder dar, insbesondere um die Routen der Spediteure zu optimieren und eine intelligente Preisgestaltung anzubieten. Dieser Teil beschreibt die Schritte, die das Unternehmen zu seinem heutigen Kenntnisstand geführt haben.
- Schritt 0: Google Sheets-Dateien
Im Jahr 2017 stand Everoad am Anfang seines Geschäfts und hatte noch nicht seine A-Serie gemacht. Das Unternehmen nutzte einen einfachen Bot auf Slack, um täglich eine csv-Datei abzurufen, die Informationen über die Aktivitäten des Vortags enthielt, es gab keine Visualisierung, keine Echtzeit-Sammlung.
Das Sammeln von Informationen ermöglichte es, ein grundlegendes Verständnis der durchgeführten Transportvorgänge zu erlangen, was in der Wachstumsphase ausreichend war.
Diese Lösung erlaubte es den Nutzern nicht, selbstständig zu arbeiten.
- Schritt 1: Aktiviere den Hebel zur Datenverteilung
Das nächste Ziel ist es, die Problematik der Verteilung von Daten in Berichtstools zu lösen. Dieser Schritt basiert auf Google sheets, mit denen man Skripte erstellen kann, um Daten automatisch von einer Datei in eine andere zu senden.
Zu diesem Zeitpunkt hatte Everoad noch keine Data Scientists eingestellt. Alexandre war Operations Manager, seine Aufgabe war es, die Aktivitäten zu analysieren und einen Überblick über die Operationen zu bekommen. Data war noch keine Priorität, bis zu einem bestimmten Punkt, an dem das Spreadsheet-System angesichts der wachsenden Datenmenge, die verarbeitet werden musste, nicht mehr ausreichte.
Dieses System war funktional und konnte die grundlegendsten Berichtsanforderungen erfüllen, aber es basierte auf einer einzigen Datenquelle und ermöglichte es, diese Daten aus einem einzigen analytischen Blickwinkel zu betrachten.
- Schritt 2: Tool für Datenbankabfragen
Der nächste Schritt ist die Einführung eines Tools, um Abfragen in verschiedenen Datenbanken durchzuführen und verschiedene Analysewinkel zu liefern.
Everoad entschied sich für Redash (inzwischen von Databricks aufgekauft), um diese Abfragen durchzuführen und die Daten in verschiedene Google Sheets zu senden.
Dieses Tool ermöglichte es, Werte aus mehreren Datenquellen zu extrahieren, flexiblere Abfragen durchzuführen und unabhängiger von den technischen Mitarbeitern zu sein, die jedoch für die eingeführten Prozesse unerlässlich waren. Die Daten wurden alle 2/3 Stunden automatisch aktualisiert.
Ein Data Analyst schloss sich dem Team an und verschiedene Berichte wurden erstellt (kommerziell und operativ). Diese Arbeitsweise dauerte 8 Monate, bevor sie angesichts des Wachstums von Everoad zu schwach wurde.
- Schritt 3: Data Warehouse
Schritt 3 ist die Integration von Airflow und Big Query, um die Datenschichten zu verwalten: Speicherung, Verarbeitung und Weitergabe der Daten an die Benutzer. Dieser Schritt stellt einen Wendepunkt in der Datenverarbeitung für Everoad dar, da drei Data Analysts und ein Data Engineer eingestellt wurden, was das Interesse des Unternehmens an seinen Daten zeigt.
Das Datenteam konnte nun Modellierung und Datenmodellierung auf seinen Datenbanken durchführen. Berichte wurden automatisiert und Produktanalysen konnten erstellt werden.
Es gab jedoch noch keine analytische Visualisierungsplattform und die Business-Intelligence-Tools waren schwach, das Unternehmen nutzte noch Spreadsheets und Google Data Studio.
Die Teams befassten sich noch nicht mit Governance-Themen, d. h. mit der Verwaltung des Zugriffs auf die Daten und ihrer Verteilung innerhalb des Unternehmens. Diese Phase dauerte zwei Jahre bis zur Fusion mit sennder.
- Schritt 4: Governance, Data Mart und Data Library
Nach dem Beitritt zu sennder hat das Unternehmen vier Dateningenieure eingestellt und sein Tool-Stack hat sich stark weiterentwickelt. Data Governance wurde mit Looker eingeführt, der Datenstrom kommt in Echtzeit an und kann direkt verwertet werden. Die Datenbanken werden alle 30 Minuten automatisch aktualisiert.
Das Datenteam deckt 100 % des Geschäfts ab: Alle Abteilungen erhalten analytische Berichte über ihre Aktivitäten mit KPIs, die für sie relevant sind, so dass 600 Benutzer Daten innerhalb des Unternehmens konsumieren.
Das Unternehmen hat einen Data Mart (oder Datenspeicher), in dem festgelegt wird, wer welche Daten braucht und wie sie verteilt werden. Es wurden auch Trainingsmodule eingerichtet, damit die Nutzer ihre Fähigkeiten verbessern können.
Die zu befolgenden Datenprozesse wurden definiert, mit „Best Practices“ und einer Datenbibliothek, um zu dokumentieren, was mit den Daten gemacht wird, immer mit dem Ziel, drei Arten von Nutzern zu bedienen:
- Business User
- Product User
- Data Team User
Fazit
Die Auswertung der gesammelten Daten ist in Unternehmen mittlerweile unverzichtbar und stellt einen beträchtlichen Wachstumshebel dar. Die Priorität der Datenverarbeitung hängt jedoch zum einen von der Branche und zum anderen von der Reife des Unternehmens ab.
So kommt das Interesse an Daten je nach Startup mehr oder weniger früh in ihrem Wachstum zum Tragen, wie die von Alexandre für Everoad und sennder beschriebenen Etappen zeigen.
In diesem Webinar hat uns Alexandre Laloo gezeigt, dass man sich für Daten interessieren, mit der Integration von Datenbanken beginnen und erste grundlegende Analysen ohne Budget, mit kostenlosen oder Freemium-Tools liefern kann. Der Prozess, der sennder zu seinem heutigen Betrieb geführt hat, war schrittweise und hat immer auf die Bedürfnisse reagiert, die durch sein Wachstum ausgelöst wurden.
Dies ist eine ermutigende Botschaft für Startups, deren Budget keinen Platz für Daten hat, denn eine einfache Verarbeitung ihrer Daten kann es ihnen ermöglichen, ihre Produkte und Dienstleistungen zu optimieren, ohne viele Ressourcen zu beanspruchen.
DataScientest dankt Alexandre Laloo herzlich für seine Zeit und die Qualität seiner Präsentation bei diesem Webinar, das uns gezeigt hat, dass die Nutzung von Data Science mittlerweile alle Branchen betrifft, von der Finanzbranche über die Lebensmittelindustrie bis hin zum Straßengüterverkehr.







