
Modelle des maschinellen Lernens sind mächtige Werkzeuge zur Lösung komplexer Probleme, sei es zur Vorhersage von Börsentrends oder zur Diagnose von Krankheiten. Um das Beste aus diesen Modellen herauszuholen, muss man jedoch die Rolle der Hyperparameter verstehen und wissen, wie man sie für eine bessere Leistung optimieren kann.
In diesem Artikel befassen wir uns mit den verschiedenen Arten von Hyperparametern und den Techniken, mit denen sie optimiert werden können. Wir gehen auch darauf ein, wie wichtig es ist, die Beziehungen zwischen Hyperparametern und der Leistung des Modells zu verstehen und welche Kompromisse eingegangen werden müssen.
Was ist ein Hyperparameter?
Ein Hyperparameter ist ein Parameter, der verwendet wird, um ein Machine-Learning-Modell zu konfigurieren. Im Gegensatz zu den Parametern des Modells, die aus den Trainingsdaten gelernt werden, müssen Hyperparameter vom Benutzer festgelegt werden, bevor das Modell trainiert werden kann.

Hyperparameter werden normalerweise auf der Grundlage der gewünschten Leistung des Modells sowie seiner Eigenschaften und Grenzen ausgewählt.
Warum sind Hyperparameter wichtig?
Hyperparameter sind wichtig, da sie einen erheblichen Einfluss auf die Leistung des Modells haben können. Durch die Verwendung ungeeigneter Werte ist es dann z. B. möglich, die Trainingsdaten zu überlernen (overfitting) oder zu unterlernen (underfitting).
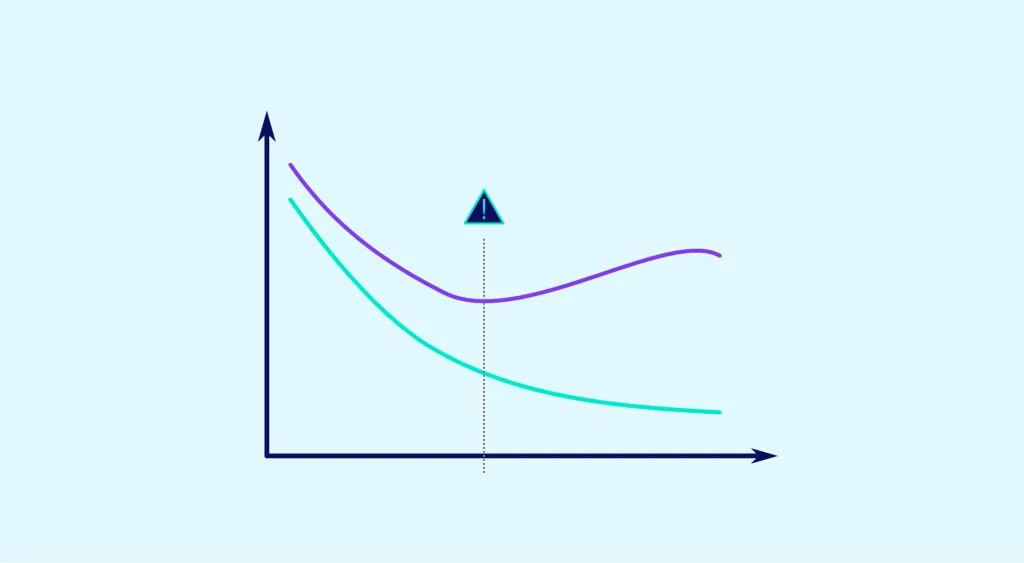
Overfitting wird auftreten, wenn sich das Modell zu eng an die Trainingsdaten anpasst und nicht gut auf die Testdaten verallgemeinert. Dies kann dazu führen, dass die Leistung des Modells bei den Testdaten sinkt.
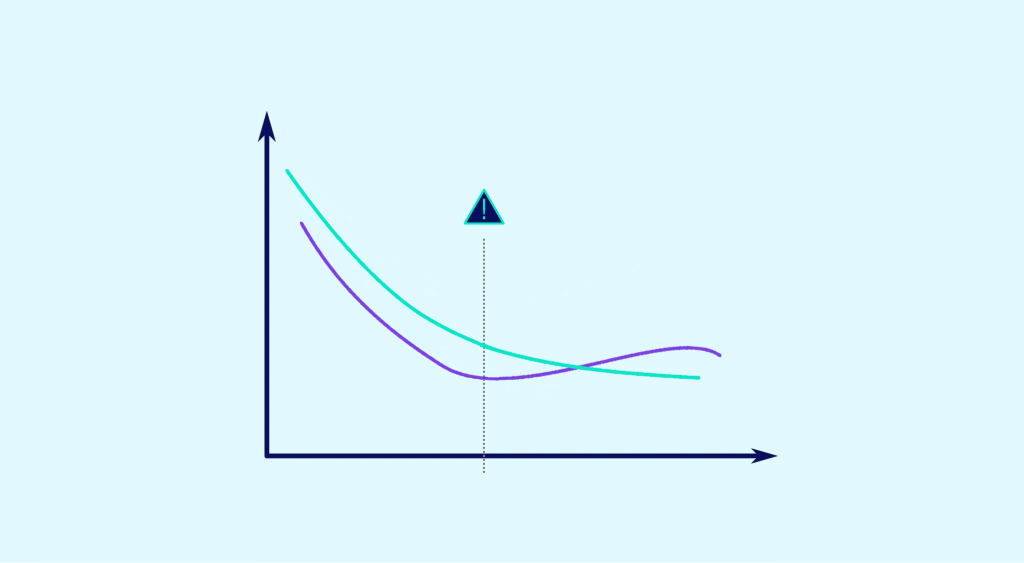
Underfitting hingegen tritt auf, wenn sich das Modell nicht ausreichend an die Trainingsdaten anpasst und die komplexen Beziehungen in den Daten nicht erfassen kann. Dies kann also zu einer schlechteren Leistung des Modells bei den Trainings- und Testdaten führen.
Zusammenfassend lässt sich sagen, dass es wichtig ist, die Hyperparameter so zu wählen, dass Overfitting und Underfitting vermieden werden, um ein leistungsfähiges Modell für die Testdaten zu erhalten.
Was sind die Unterschiede zwischen den Hyperparametern?
Es gibt verschiedene Methoden, um die Hyperparameter einer Vorlage auszuwählen. Hier sind einige Beispiele:
Rastersuche (grid search)
Diese Einstellung besteht darin, alle möglichen Kombinationen der Hyperparameter auszuprobieren, ein Modell für jede Kombination zu trainieren und die Kombination mit den besten Ergebnissen auszuwählen. Diese Methode kann sehr effizient sein, aber sie kann sehr zeitaufwendig sein, wenn du viele Hyperparameter und mögliche Werte ausprobieren musst. Außerdem kann sie in Bezug auf Rechenressourcen kostspielig sein, wenn du viele Modelltrainings benötigst, um die besten Kombinationen zu finden.
Trotz dieser Nachteile bleibt die Grid-Suche eine beliebte Methode zur Auswahl von Hyperparametern und kann in vielen Situationen sehr effektiv sein. Wenn du die Zeit und die nötigen Rechenressourcen hast, ist dies ein Ansatz, den du bei der Auswahl der Hyperparameter für dein Modell in Betracht ziehen solltest.
💡Auch interessant:
Random search
Bei der Zufallssuche werden verschiedene Kombinationen von Hyperparametern zufällig ausgewählt und für jede Kombination wird ein Modell trainiert. Diese Methode kann weniger effizient sein als die Rastersuche, hat aber den Vorteil, dass sie oft schneller umzusetzen ist und in bestimmten Situationen gute Ergebnisse liefern kann.
Bayesianische Optimierung
Besteht darin, eine Wahrscheinlichkeitsverteilung über die Hyperparameter zu verwenden und diese Verteilung anhand der Ergebnisse zu aktualisieren, die beim Trainieren des Modells erzielt werden. Diese Methode kann effizienter sein als die Raster- und Zufallssuche, erfordert aber in der Regel den Einsatz von Spezialwerkzeugen und kann komplizierter zu implementieren sein.

Experimentieren und Trial and Error
Besteht darin, iterativ verschiedene Werte für Hyperparameter auszuprobieren und die Hyperparameter entsprechend den Ergebnissen anzupassen. Diese Methode kann nützlich sein, wenn du ein gutes Verständnis der Hyperparameter und ihrer Auswirkungen auf das Modell hast, aber sie kann weniger effektiv sein als die anderen Methoden, wenn du nicht weißt, welche Hyperparameter am wichtigsten sind.
Letztendlich hängt die Wahl der Hyperparameter von vielen Faktoren ab, wie z. B. der Komplexität der Daten, der gewünschten Leistung und den verfügbaren Ressourcen. Es empfiehlt sich, verschiedene Ansätze zu testen, um die Hyperparameter zu finden, die für dein Modell die besten Ergebnisse liefern.
Fazit
Hyperparameter sind Parameter, die zur Konfiguration eines Machine-Learning-Modells verwendet werden und einen erheblichen Einfluss auf dessen Leistung haben können. Es ist wichtig, die Hyperparameter sorgfältig auszuwählen, um Overfitting und Underfitting zu vermeiden und ein leistungsstarkes Modell zu erhalten. Es gibt verschiedene Methoden zur Auswahl von Hyperparametern, die alle ihre eigenen Vor- und Nachteile haben. Letztendlich hängt die Wahl der Hyperparameter von vielen Faktoren ab und kann Versuch und Irrtum erfordern, um die besten Werte zu finden.







