You Only Look Once oder YOLO ist ein Algorithmus, der Objekte auf den ersten Blick erkennen kann, indem er die Erkennung und Klassifizierung gleichzeitig durchführt. Hier erfährst du alles, was du über diesen revolutionären Ansatz für KI und Computer Vision wissen musst!
Im Bereich der Computer Vision ist die Erkennung von Objekten eine der wichtigsten Säulen. Die Fähigkeit, Objekte in Bildern und Videos zu erkennen und zu klassifizieren, ist für viele moderne Technologien unerlässlich.
Dies gilt für autonome Fahrzeuge, Überwachungssysteme, Robotik oder auch generative künstliche Intelligenz.
Nach jahrelanger Forschung zur Verbesserung der Leistung und Effizienz von Erkennungssystemen hat ein innovativer Algorithmus, der von Joseph Redmon eingeführt wurde, im Jahr 2016 alles verändert: YOLO, You Only Look Once.
Zurück zu den Ursprüngen der Objekterkennungssysteme
Die Objekterkennung ist eine grundlegende Aufgabe der Computer Vision. Sie ist die Grundlage für eine Vielzahl neuer Innovationen, wie z. B. Gesichtserkennung, Augmented Reality, automatisierte Überwachung und sogar autonomes Fahren.
Früher basierten die am häufigsten verwendeten Techniken hauptsächlich auf traditionellen, mehrstufigen Ansätzen. Diese Methoden waren zwar effektiv, hatten aber große Nachteile in Bezug auf die Verarbeitungsgeschwindigkeit.
Bei Region-Based Convolutional Neural Networks (oder R-CNN) ging es z. B. darum, zunächst Regionen von Interesse (Rols) aus dem Bild vorzuschlagen. Um dies zu erreichen, wurden hauptsächlich Algorithmen zur Segmentierung oder zur Erkennung von Wettbewerben verwendet.
Jede Rols wurde dann in der Größe verändert, um in einen Klassifikator wie z.B. ein Convolutional Neural Network (CNN) eingegeben zu werden. Das Ziel war es, zu bestimmen, ob sich ein Objekt in einer Region befand.
Diese Technik war damals ein bedeutender Fortschritt, litt aber aufgrund der großen Anzahl an zu bewertenden Kandidatenregionen an einer erheblichen Langsamkeit.
Um diese Einschränkungen zu überwinden, wurde Fast R-CNN ins Leben gerufen. Sie ermöglichte es, die Klassifizierung von ROls direkt von einer Karte mit gemeinsamen Merkmalen des CNN aus vorzunehmen, anstatt separate Klassifizierer zu verwenden.
Trotz des Geschwindigkeitsgewinns im Vergleich zu R-CNN blieb der Auswahlprozess langsam und komplex. Deshalb wurde der Faster R-CNN-Ansatz geschaffen, der den Vorschlag der Regionen von Interesse durch ein Netzwerk einführte.
Diese Entwicklung ermöglichte eine weitere Automatisierung und Beschleunigung der Rols-Generierung, blieb aber aufgrund der vielen sequentiellen Schritte, die für die Erkennung von Objekten erforderlich waren, hoffnungslos langsam.
Abgesehen von der fehlenden Geschwindigkeit hatten diese verschiedenen Methoden mehrere Mängel, wie z. B. die computertechnische Komplexität und die Schwierigkeit der Skalierung. Dies schränkte ihre Anwendbarkeit in Szenarien, die eine Echtzeit-Erkennung erforderten, stark ein.
Ihre Effektivität hing auch von der Qualität der vorgeschlagenen Regionen von Interesse ab, was zu Fehlern bei der Erkennung führen konnte, wenn wichtige Regionen verpasst wurden.
Aus all diesen Gründen war es höchste Zeit für eine neue Technik, die alles in diesem Bereich auf den Kopf stellt. Und genau das ist mit YOLO geschehen.

Was ist You Only Look Once ?
Der Grund, warum You Only Look Once einen Wendepunkt darstellte, war sein innovativer Ansatz. Indem es gleichzeitig die Erkennung und Klassifizierung von Objekten in einem einzigen Durchgang durch ein faltendes neuronales Netz durchführte, konnte es Echtzeitgeschwindigkeit und Genauigkeit miteinander verbinden.
Ihre Pipeline-Architektur in Verbindung mit Mechanismen für bestimmte Regionen von Interesse hat alle älteren Methoden übertroffen und sie überflüssig gemacht.
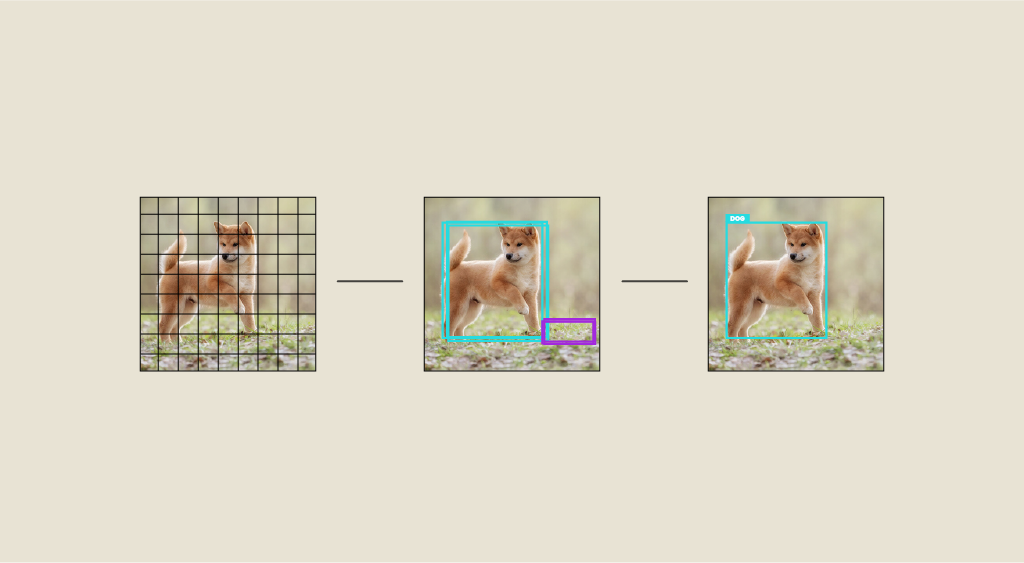
Tatsächlich unterscheidet sich ihre Struktur grundlegend von herkömmlichen Techniken. Anstatt in einem ersten Schritt Regionen von Interesse vorzuschlagen, teilt sie das Eingabebild in ein Gitter von Zellen auf, von denen jede dafür verantwortlich ist, die Koordinaten der Bounding Boxes für die erkannten Objekte und die Wahrscheinlichkeit, dass sie zu verschiedenen Klassen gehören, vorherzusagen.
Vereinfacht gesagt, sagt jede Zelle einen Satz von Bounding Boxes und die entsprechenden Konfidenzwerte für jede Klasse voraus, wobei diese Vorhersagen direkt aus den vom CNN extrahierten Merkmalen abgeleitet werden. Dadurch entfällt die Notwendigkeit, das Bild mehrmals zu durchlaufen.
Diese Verwendung eines faltenden neuronalen Netzes zur Extraktion von Merkmalen aus dem Eingabebild ist das Herzstück von YOLO. Das CNN besteht aus mehreren Faltungsschichten und Unterabtastung (Pooling), um nützliche Muster und Merkmale auf verschiedenen räumlichen Skalen zu erfassen.
Dadurch können relevante Darstellungen von Objekten automatisch erlernt und Faltungsoperationen effizient durchgeführt werden, wodurch die Rechnungskosten stark reduziert werden.
Ein weiteres Schlüsselmerkmal ist die Verwendung von „Regionen von Interesse“ oder „Anchors“, die vordefinierte, umschließende Boxen unterschiedlicher Größe und Form sind, die als Referenz für Vorhersagen dienen.
Jede Gitterzelle ist mit einer bestimmten Anzahl von Anchors verknüpft, was YOLO dabei hilft, die Erkennung über verschiedene Objekttypen und Maßstäbe hinweg zu verallgemeinern. Dadurch wird die Erkennungsgenauigkeit erheblich gesteigert.
💡Auch interessant:
| Was genau ist ein Deep Neural Network? |
| Recurrent Neural Network (RNN): Was genau ist das? |
Was sind die Vorteile?
Offensichtlich bietet You Only Look Once mehrere wichtige Verbesserungen im Vergleich zu früheren Methoden der Objekterkennung.
Dadurch wurde es zu einem der am häufigsten verwendeten Algorithmen für die Computer Vision.
Seine größte Stärke ist seine Fähigkeit, Objekte sofort zu erkennen und die Gesamtzahl der erforderlichen Berechnungen zu reduzieren.
Die Ressourcennutzung wird optimiert, da gemeinsam genutzte Merkmale nur einmal berechnet werden.
Darüber hinaus zeichnet sich YOLO auch durch seine Leistung und Genauigkeit aus. Sein Pipeline-Ansatz ermöglicht es ihm, auf Objekte mit unterschiedlichen Formen zu verallgemeinern, was ihn robust gegenüber einer Vielzahl von Szenarien macht.
Es eignet sich auch hervorragend für die Verarbeitung von hochauflösenden Bildern, da seine effiziente Architektur es ermöglicht, größere Bilder zu verarbeiten, ohne dabei an Geschwindigkeit einzubüßen. Dies ist ein großer Vorteil für Anwendungen wie Luft- und Satellitenortung.

Wozu dient es? Welche Anwendungen gibt es?
You Only Look Once hat sich aufgrund seiner Flexibilität und Effizienz in einer Vielzahl von Bereichen und Anwendungsgebieten etabliert, z. B. in autonomen Fahrzeugen, um Fußgänger, andere Fahrzeuge, Verkehrsschilder und andere potenzielle Hindernisse auf der Straße in Echtzeit zu erkennen und zu verfolgen. Dadurch können die Steuerungssysteme sofort auf Veränderungen reagieren, um ein sicheres Fahren zu gewährleisten.
Bei der Videoüberwachung kann YOLO verdächtige Aktivitäten, Eindringlinge oder zurückgelassene Gegenstände selbst in einer Menschenmenge erkennen. Ebenso kann es verwendet werden, um Menschen oder Tiere aufzuspüren, die sich an schwer zugänglichen Orten verirrt haben. Sie kann auch für Sicherheitskontrollen in Flughäfen, Bahnhöfen und anderen Einrichtungen eingesetzt werden.
Seine Fähigkeit zur Aktivitätserkennung kann auch nützlich sein, um die Bewegungen von Personen in Videosequenzen zu erkennen und zu verfolgen. Dies ist ein relevanter Anwendungsfall für die Überwachung großer Bereiche wie Stadien, Einkaufszentren oder bei großen Sportveranstaltungen.
Ein weiteres Anwendungsbeispiel ist die Steuerung des Autoverkehrs. Der Algorithmus kann für die automatische Erkennung von Nummernschildern und Gesichtern verwendet werden.
Im Bereich der Medizin wird You Only Look Once zur Erkennung von Anomalien oder bestimmten Objekten in medizinischen Bildern wie Röntgenaufnahmen, MRTs oder CTs verwendet.
Es kann dazu beitragen, Krankheiten frühzeitig zu diagnostizieren, indem es den Prozess der Bildanalyse beschleunigt. Dies kann sich in medizinischen Notfallsituationen als lebenswichtig erweisen.
Fazit: YOLO, eine der treibenden Kräfte der neuen KI-Welle
Indem You Only Look Once zum ersten Mal eine sofortige Objekterkennung ermöglichte, eröffnete es unzählige neue Möglichkeiten für die Computer Vision. Es ist eine der Innovationen, die die KI in ein neues Zeitalter geführt haben.
Um zu lernen, wie man mit den besten Algorithmen der künstlichen Intelligenz umgeht, kannst du dich für DataScientest entscheiden. Unsere verschiedenen Kurse in Data Science beinhalten Module, die sich mit KI und ihren verschiedenen Zweigen beschäftigen.
Dazu gehören Machine Learning, Reinforcement Learning, neuronale Netze und Tools wie Keras, TensorFlow und PyTorch.
In unseren Kursen kannst du alle Fähigkeiten erwerben, die du brauchst, um Data Analyst, Data Scientist, Data Engineer, Data Product Manager oder Machine Learning Engineer zu werden.
Alle unsere Kurse werden im Fernunterricht durchgeführt und sind durch den Bildungsgutschein förderfähig. Am Ende des Kurses kannst du ein staatlich anerkanntes Zertifikat „Projektmanager für künstliche Intelligenz“, ein Diplom von Mines ParisTech PSL Executive Éducation und ein Zertifikat unserer Cloud-Partner AWS und Microsoft Azure erwerben. Entdecke DataScientest!








