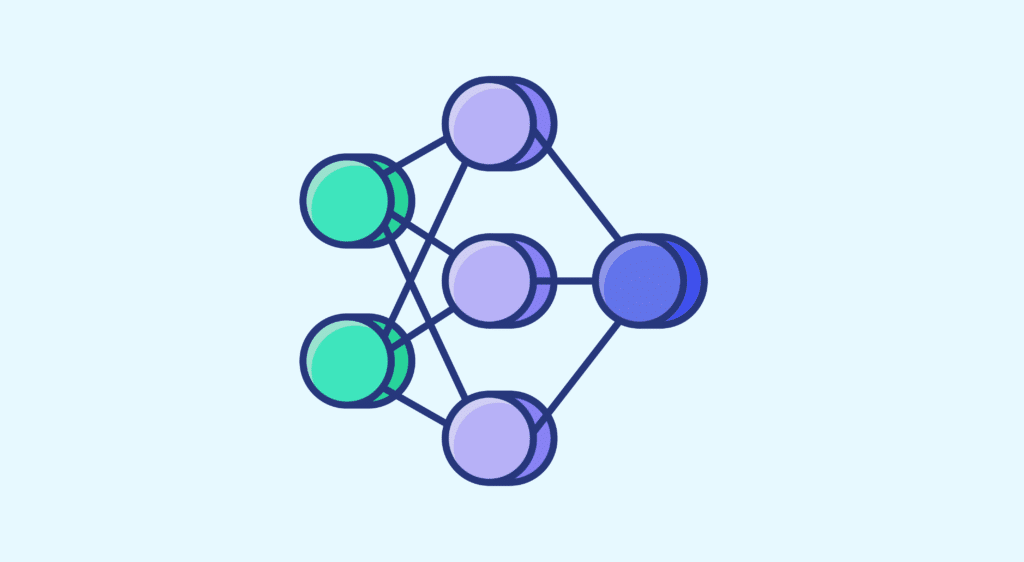
Les réseaux de neurones sont maintenant omniprésents dans le monde de la data, mais s’il y a bien un concept novateur qui a émergé ces dernières années, ce sont les réseaux GANs. Ces réseaux qui apprennent en s’affrontant sont particulièrement efficaces, et si ce concept est combiné avec l’état de l’art des techniques d’image processing, vous obtenez ce que nous allons aborder dans cet article, les DCGANs ou Deep Convolutional Generative Adversarial Networks.
Qu’est ce que le concept des GANs ?
Pour rappel, le concept des réseaux GANs réside dans l’affrontement de deux réseaux, le Générateur (G) et le Discriminateur (D). Le Générateur apprend à générer de toute pièce une image réaliste (similaire à celles d’un jeu de données) qui va être jugée par le Discriminateur qui a déjà rencontrée des images du jeu de données, si le réseau D est trompé, alors il va devoir apprendre de son erreur, si le réseau D a juste alors c’est le réseau G qui va devoir s’améliorer.
Cette méthode permet de se retrouver dans une situation de classification supervisée et l’apprentissage se fait à travers les loss functions (fonctions de pertes) des deux réseaux, comme pour des réseaux traditionnels.
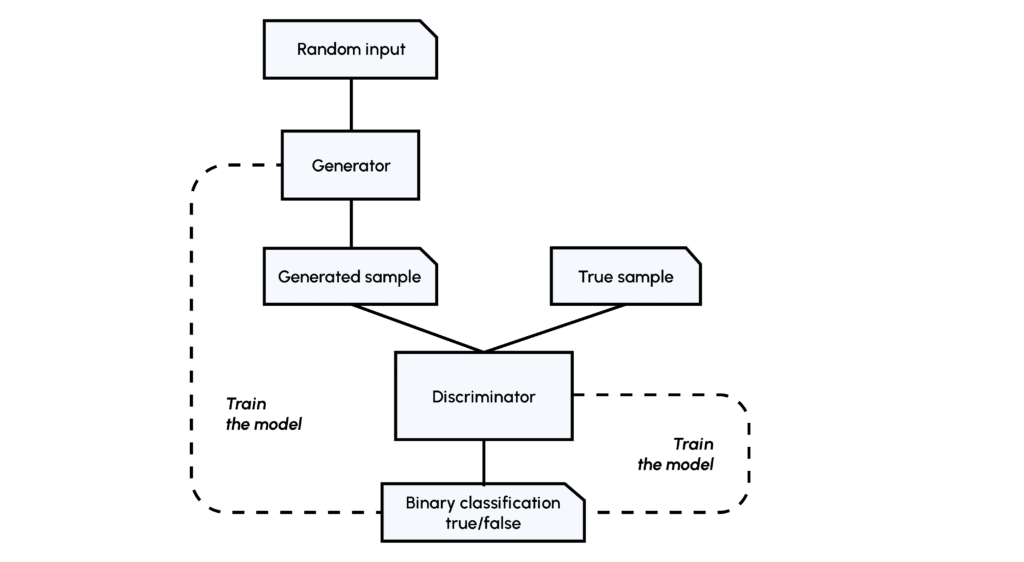
Si vous souhaitez en savoir plus, nous avons un article sur le concept des GANs et leurs utilisations.
Rapidement ont été présentées les limites de cette méthode, les images générées n’étaient pas assez réalistes, notamment quand on essayait d’augmenter la qualité ou la finesse de celles-ci. Cette limite est due à la structure elle-même des réseaux Générateur et Discriminateur, de simples réseaux denses (feed-forward ou fully connected en anglais) ne permettent pas d’exploiter au mieux toutes les spécificités d’une image. Pour cela il faut utiliser des réseaux plus complexes appelées réseaux de convolutions (CNNs ou ConvNets pour Convolutional Neural Networks).
Avant d’entrer dans le détail de l’implémentation du DCGAN, il est nécessaire de comprendre les concepts clés qui composent les CNNs. En particulier les convolution layers, si ceux-ci vous sont étrangers vous pourrez les retrouver dans l’un de nos articles.
Comment construire le discriminateur ?
Dans notre DCGAN, le réseau Discriminateur doit, à partir d’une image réelle ou fausse, établir une classification. On pourrait donc se ramener à un CNN classique type LeNet, mais il a été établi par les créateurs de l’architecture DCGAN que certains paramètres spécifiques étaient plus intéressants, passons les en revue.
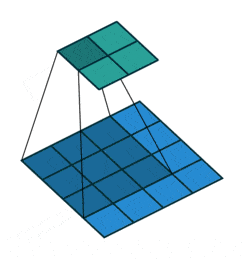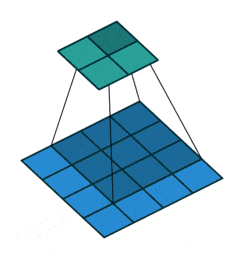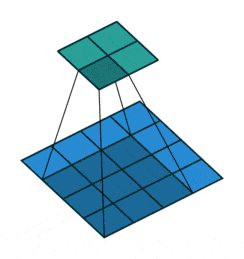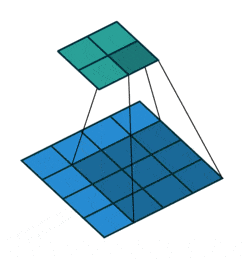
- Downsampling : pour réduire progressivement les dimensions de nos couches de convolutions et éviter le sur-apprentissage, il est d’usage d’utiliser les couches de pooling. Ici se sont révélées plus efficaces des couches de convolution avec stride, c’est-à-dire que le filtre de convolution va se déplacer de plus qu’une 1 case à chaque fois, voici une représentation permettant de mieux comprendre le fonctionnement de celles-ci :
- Batch Normalization : cette normalisation des poids après chacune des couches de convolution (par stride donc) permet un apprentissage plus stable et plus rapide du réseau, par conséquent il n’est pas nécessaire d’utiliser de biais dans nos différentes couches !
- Activation Function : la fonction ReLU semblait, dans le cadre de l’entraînement du Discriminateur, converger vers un état où tous les poids du réseau étaient inactifs, on utilise donc une variante de cette fonction appelée LeakyReLU
Construction du Générateur
Le rôle du réseau Générateur est de passer d’un vecteur aléatoire à une image capable de tromper le Discriminateur, il faut donc utiliser de nouvelles techniques qu’on pourrait décrire comme un réseau convolutif inversé :
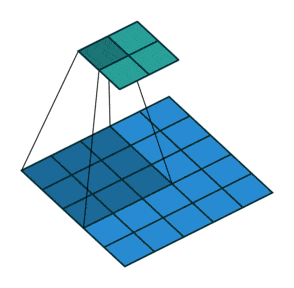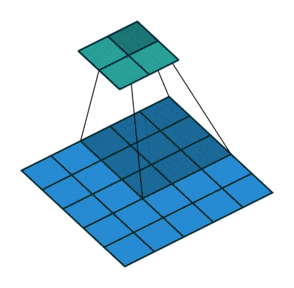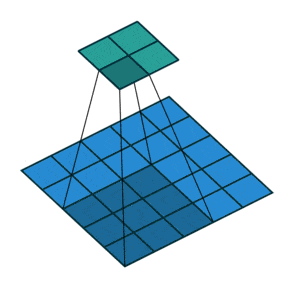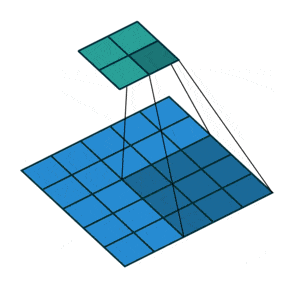
- Upsampling : pour augmenter la dimension de notre vecteur vers une image, il faut utiliser ce qu’on appelle des convolutions transposées comme ci-dessous :
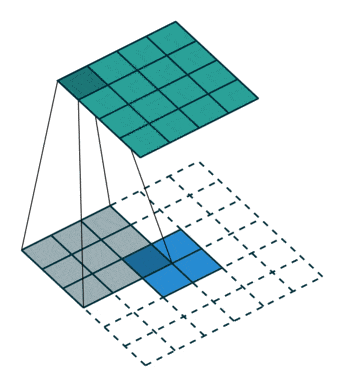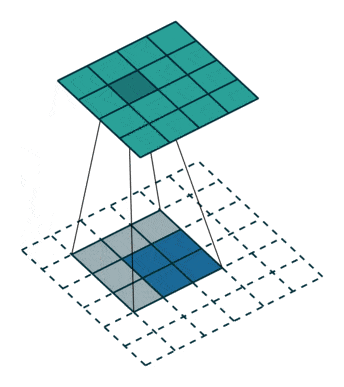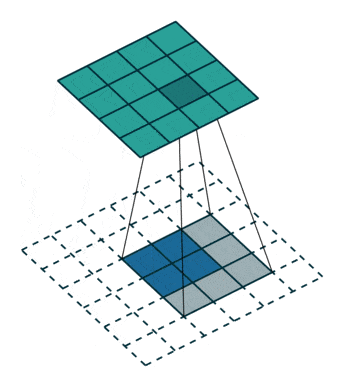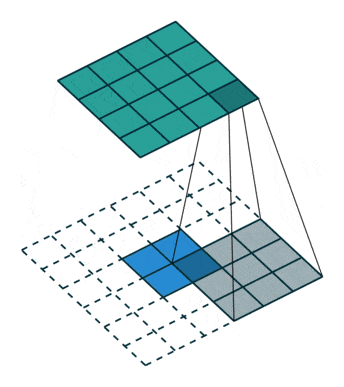
- Batch Normalization : la même logique est appliquée que pour le Discriminateur
- Activation Function : ici on utilise la fonction ReLU dans toutes les couches sauf la dernière où on utilise une fonction tanh, parce qu’il est plus efficace d’utiliser des images normalisées en input du Discriminateur !
Voici plusieurs illustrations de fonctions d’activation :
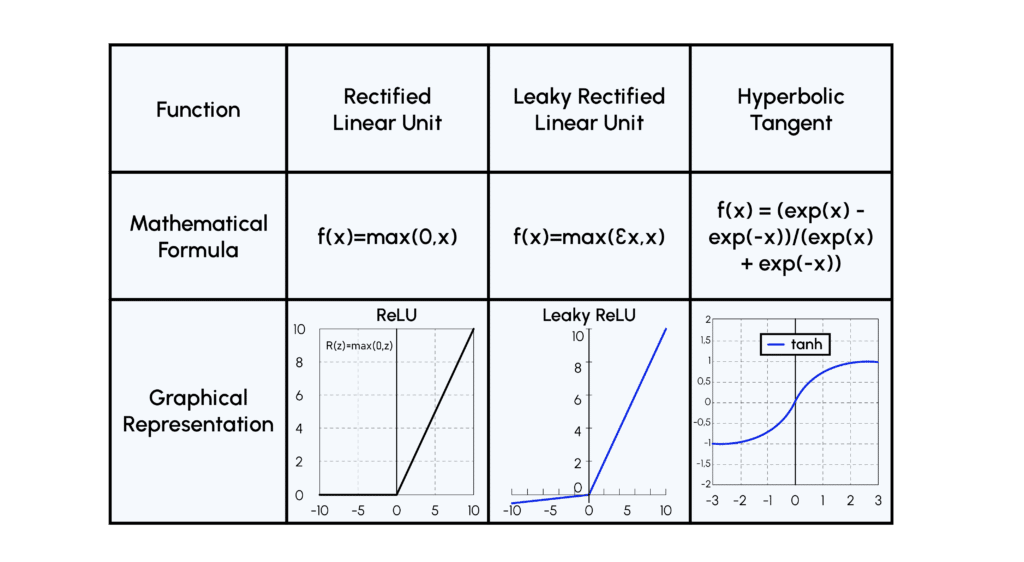
Par ailleurs, les constructions particulières des Discriminateurs et Générateurs rendent inutiles les couches denses qu’on retrouve habituellement dans les CNNs.
Entraînement ou training loop
Si vous avez bien suivi jusqu’ici vous avez remarqué qu’il y a une étape essentielle dont nous n’avons pas encore parlé, c’est la training loop, ou phase d’entraînement. Si vous êtes déjà familier avec le training des réseaux de neurones vous savez qu’il existe un nombre quasi-infini d’hyperparamètres à tester. Cette problématique est logiquement 2 fois plus présente avec l’entraînement des DCGANs, c’est pourquoi il est d’usage d’utiliser des paramètres empiriquement prouvés comme efficaces, notamment par les auteurs du papier.
Nous présenterons ici simplement les grandes lignes :
- Initialisation : tous les poids sont initialisés suivant une distribution Gaussienne spécifique permettant d’éviter des problèmes de convergences durant l’apprentissage.
- Descente de gradient : celle-ci se fait de manière stochastique sur des mini-batch, pour la même raison que l’initialisation : cela stabilise l’entraînement.
- Optimizer : on utilise l’optimizer Adam qui permet une mise à jour en continu du taux d’apprentissage. Des paramètres spécifiques pour le momentum β1 et l’initialisation de la learning rate sont utilisés pour stabiliser l’entraînement.
Beaucoup de détails techniques ont été évoqués, cependant ce sont des paramètres de plus en plus utilisés en Deep Learning. Par exemple, les convolutions transposées ou à stride sont utilisées dans de nombreuses applications d’apprentissage profond telles que l’image inpainting, la segmentation sémantique ou la super-résolution d’images. De même, l’optimizer Adam est un optimizer très robuste et omniprésent en Deep Learning.
La “simplicité” du DCGAN contribue à son succès. Cependant, un certain goulot d’étranglement a été atteint : l’augmentation de la complexité du générateur n’améliore pas nécessairement la qualité de l’image. C’est pourquoi il y a eu de nombreuses améliorations récentes : les cGANs, les styleGANs, cycleGANs etc..
Vous pouvez retrouver les GANs, les DCGANs et les améliorations qui ont depuis été apportées à ces réseaux dans le module “Generative Adversarial Network” de notre formation Deep Learning for Computer Vision.









