Aujourd’hui, nous nous intéressons à l’Isolation Forest, un algorithme de Machine Learning destiné à résoudre des problèmes de classification binaires tels que la détection de fraude ou le diagnostic d’une maladie. Cette technique présentée à l’Eighth IEEE International Conference en 2008 est la première technique de classification dédiée à la détection d’anomalies basée sur l’isolation.
Le problème de l’Accuracy Paradox
Lorsqu’on fait face à un problème de classification de classes en Machine Learning, il arrive parfois que le jeu de données soit déséquilibré. Plus précisément, on constate une proportion bien plus grande d’une classe vis-à-vis de l’autre au sein de l’échantillon d’apprentissage. Ce problème est une caractéristique fréquente des problèmes de classification binaires. On pourrait en première approche, penser à appliquer un algorithme de classification classique, comme les arbres de décisions, les K-NN ou les SVM présentés sur notre blog. Toutefois, ces algorithmes ne sont en réalité pas en mesure de gérer ces jeux de données atypiques où les disparités entre les classes sont assez fortes. Ils tendent à maximiser par le biais de leur fonction de perte des quantités tel que l’accuracy, mais sans tenir compte de la distribution des données.
En pratique, cela se retrouve sur des modèles qui, entraînés sur un dataset dominé par une classe, vont rendre compte lors de la phase d’évaluation d’un taux de prédictions correctes, appelé « accuracy« , élevé mais ne seront pas pertinents à l’usage.
Prenons un exemple pour illustrer ce paradoxe. Considérons un problème de détection de fraude bancaire, une banque cherche à déterminer parmi un grand nombre de transactions, quelles sont les transactions frauduleuses à partir d’un certain nombre de variables explicatives. Ces transactions frauduleuses représentent environ 11% des transactions dans notre dataset. La classification à l’aide d’un modèle simple tel que le SVM à l’aide de scikit learn donne par exemple donne le score suivant :
Toutefois en jetant un œil à la matrice de confusion on remarque vite que le comportement de l’algorithme est assez naïf :

En effet, sur 219 transactions frauduleuses seules 25 ont bien été identifiées comme frauduleuses par notre modèle. Nous constatons ainsi que le pouvoir de prédiction du modèle n’est pas aussi puissant que ce que pourrait laisser croire l’accuracy. C’est une métrique qui est trop biaisé par un déséquilibre des classes, ce phénomène est appelé l’accuracy paradox.
Un modèle avec un score d’accuracy plus élevé peut avoir un pouvoir de prédiction plus faible qu’un modèle avec une accuracy plus faible.
L’Isolation Forest : c’est quoi ?
Mais alors comment faire face à ce problème qui vient ruiner les efforts de plusieurs algorithmes classiques rondement entraînés ? Il existe plusieurs solutions comme par exemple les méthodes de ré-échantillonnages comme l’undersampling ou l’oversampling qui sélectionnent aléatoirement des données afin d’équilibrer le ratio de classe. Toutefois, lorsque ces méthodes ne sont pas assez efficaces, il est d’usage de repenser le problème et de considérer la détection d’anomalies comme un problème de classification non supervisée. C’est là qu’intervient le tant attendu Isolation Forest !
Dans Isolation Forest, on retrouve Isolation car c’est une technique de détection d’anomalies qui identifie directement les anomalies (communément appelées “outliers”) contrairement aux techniques usuelles qui discriminent les points vis-à-vis d’un profil global « normalisé ».
Le principe de cet algorithme est très simple :
- On sélectionne une variable (feature) de façon aléatoire.
- Ensuite on réalise un partitionnement aléatoire du jeu de données selon cette variable de telle sorte à obtenir deux sous-ensembles de données.
- On répète les deux étapes précédentes jusqu’à ce qu’une donnée soit isolée.
- De manière récursive, on répète les étapes précédentes.

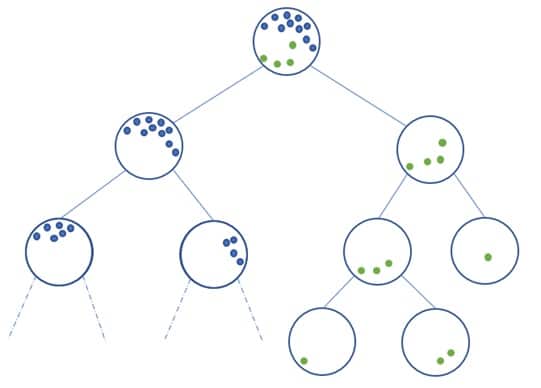
Comment alors obtenir le résultat sur un arbre ? C’est-à-dire comment définir si un point est une anomalie ou non ? La construction de l’algorithme donne lieu à une structure d’arbre, dont les nœuds sont les ensembles partitionnés durant les étapes de l’algorithme et les feuilles sont les points isolés. Intuitivement les anomalies auront tendance à être les feuilles les plus proches de la racine de l’arbre.
En fonction de la distance à la racine, on associe à chaque feuille d’un arbre un score d’anomalie, on moyenne ce score d’anomalie sur l’ensemble des arbres qui ont été construits récursivement et on obtient un résultat final. On peut alors selon la situation jouer sur les paramètres tels que le nombre d’arbres ou la proportion d’anomalies à considérer afin d’obtenir un résultat plus robuste.
L’Isolation Forest est très appréciée pour sa capacité à détecter des anomalies de manière non supervisée tout en obtenant des résultats satisfaisants dans de nombreux domaines. On peut y trouver des applications en fraude bancaire, diagnostic médical, ou bien en analyse de défaut structurel.
Si vous voulez en savoir plus, n’hésitez pas à jeter un œil à nos formations de Data Scientist, Data Analyst et Data Engineer.








