
“Ensemble on est plus fort” : On pourrait symboliser le bagging par cette citation. En effet, cette technique fait partie des méthodes d’ensemble, qui consiste à considérer un ensemble de modèles pour prendre la décision finale. Nous allons voir en détail le cas du bagging.
Tout d’abord, il est nécessaire de faire un travail sur les données. En effet, nous n’allons pas fournir les mêmes données à tous nos modèles, car nous voulons que nos modèles soient indépendants. Le problème étant que nous ne pouvons pas partitionner le jeu de données. Pour un nombre important de modèles, nos modèles ne seraient pas suffisamment entraînés et produisent des résultats médiocres.
La solution de nos maux : le bootstrap
Pour palier ce problème, nous réalisons un jeu de données bootstrap. Avec cette méthode, nous créons un nouveau jeu de données à partir du jeu de données initial. Le nouveau jeu de données est de même taille que celui de départ. Notons n la taille des échantillons et appelons E_1 le jeu de données initial et E_2 le jeu de données réalisé par bootstrap. De E_1, nous allons choisir un individu aléatoirement que nous allons placer dans E_2. Nous allons réitérer cette étape, jusqu’à que E_2 soit de taille n. Il est important de remarquer que les éléments choisis sont toujours dans E_1, nous pouvons sélectionner le même élément plusieurs fois. C’est cette particularité qui permet de produire des données différentes.
Regardons un exemple concret pour mieux comprendre, en reprenant les notations ci-dessus.
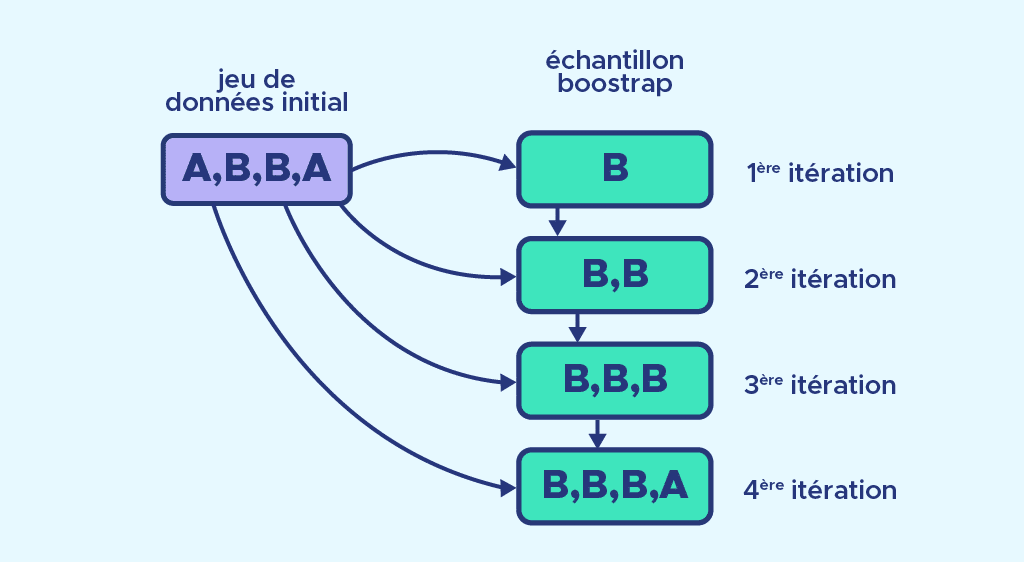
- Ici E_1 est composé de 2 éléments appelés A et de 2 éléments appelés B, E_2 est vide et n=4.
- À la première itération, on choisit aléatoirement un élément de E_1, on place B dans E_2.
- On répète ce processus jusqu’à que E_2 comporte 4 éléments.
- Finalement E_2 est composé de 3 éléments B et un élément A. Un élément B a été sélectionné 3 fois.
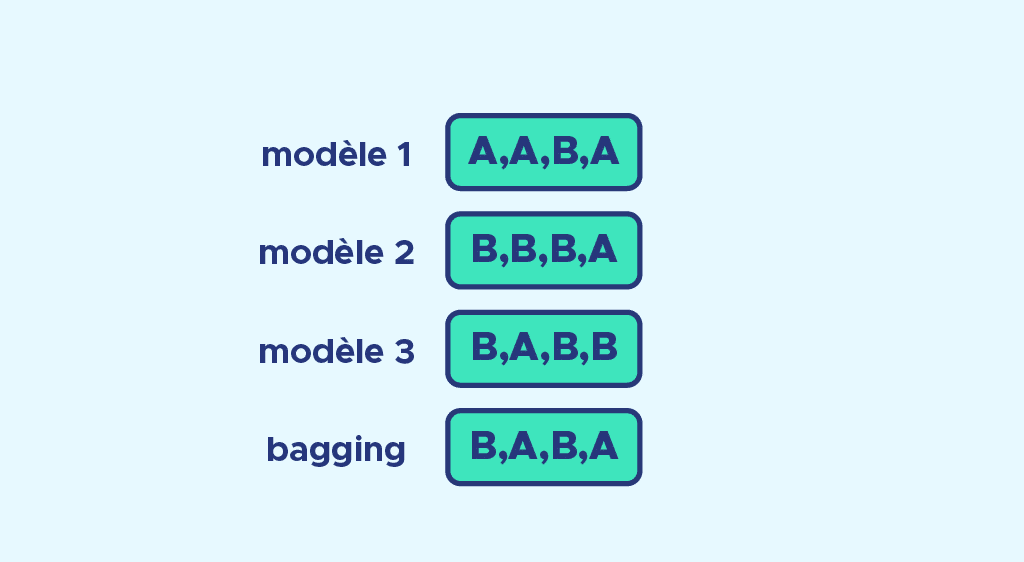
Maintenant que nous avons vu ce qu’était le bootstrap, nous décidons de faire 3 échantillons* de bootstrap. Pour chaque échantillon, on va attribuer un modèle différent. Il est courant d’utiliser des arbres de décision. Nous entraînons chaque modèle et nous faisons nos prédictions.
*le choix de 3 est arbitraire
Que pouvons-nous faire à présent avec 3 prédictions ?
Nous avons besoin d’une unique valeur pour notre problème, c’est là que nous faisons de l’agrégation de données. Pour des modèles de classification, nous allons appliquer un système de vote et pour des modèles de régression, nous allons faire une moyenne de la valeur prédite. En se référant à la citation de départ, nous construisons un modèle final à partir de plusieurs modèles.
Nous pouvons voir un exemple de système de vote où on doit prédire A ou B, avec l’exemple ci-dessous :
Pour retenir ce qu’est le bagging, nous pouvons se rappeler qu’il s’agit d’une combinaison de bootstrap et de aggregating. Un célèbre algorithme de bagging est le fameux random forest, que vous pouvez retrouver ici. Par ailleurs, vous pouvez vous renseigner sur une autre technique d’ensemble connu qu’est le boosting dans cet article
Bagging = Bootstrap + aggregating
Un des atouts de cette méthode est de pouvoir réduire la variance, en effet même si les modèles ne sont pas entraînés sur le même jeu de donnée, les échantillons de bootstrap partagent des tuples en commun, ce qui produit du biais. Ce biais produit fait réduire la variance.
Un deuxième atout est de corriger les erreurs de prédictions. Observons l’image ci-dessous. Chaque modèle fait une erreur de prédictions de classification, mais chaque erreur est corrigée par le système de vote.
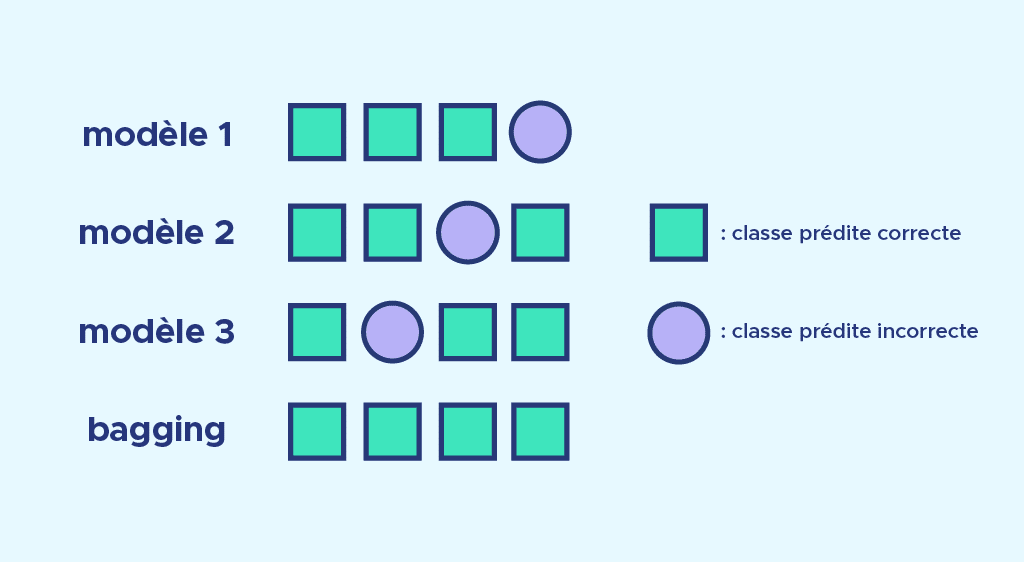
Nous avons vu en quoi, le bagging rejoint les techniques d’ensemble. Comme énoncé en introduction, nous utilisons plusieurs modèles dont nous agrégeons les prédictions pour avoir une prédiction finale. Pour calibrer nos différents modèles, nous créons différents jeux de données par bootstrap sur l’échantillon de départ.
Si vous voulez le mettre en pratique, n’hésitez pas à vous inscrire à notre formation Data Scientist.








