
Les chercheurs de l'Université de Waterloo, dans l'Ontario, aux États-Unis, ont développé une nouvelle technique de Machine Learning intitulée "LO-Shot Learning". Elle permet d'entraîner un modèle d'intelligence artificielle avec une poignée de données seulement...
À l’heure actuelle, le Machine Learning ou apprentissage automatique requiert de vastes volumes de données. Pour entraîner une intelligence artificielle, il est nécessaire de la « nourrir » à l’aide de nombreuses données.
Par exemple, pour apprendre à reconnaître un chat, une IA devra analyser des milliers de photos de chats. C’est la raison pour laquelle cette technologie requiert une lourde puissance de calcul et nécessite du temps.
Il s’agit aussi d’une différence majeure entre l’intelligence humaine et l’intelligence artificielle. En effet, il suffit à un enfant de voir quelques exemples d’un objet pour pouvoir le reconnaître toute sa vie.
Pour combler ce fossé, une équipe de chercheurs de l’Université de Waterloo dans l’Ontario a décidé de développer une nouvelle méthode permettant à une IA de pouvoir reconnaître plus d’objets que le nombre d’exemples sur lesquels elle a été entraînée. Cette nouvelle méthode est intitulée « less than one-shot learning » ou « LO-shot learning ».
Dans le cadre d’une démonstration, les chercheurs ont utilisé l’ensemble de données MNIST dédié à la vision par ordinateur. Ce dataset rassemble plus de 60 000 images d’entraînement représentant des chiffres manuscrits de 0 à 9.
En utilisant une technique récemment présentée par le MIT, les chercheurs ont « compressé » MNIST en seulement 10 images, optimisées pour contenir une quantité d’informations équivalente à l’ensemble complet. Ainsi, en s’entraînant seulement sur ces dix images, le modèle a pu atteindre la même précision que s’il avait été entraîné sur le dataset complet.
Ils sont allés encore plus loin en réduisant le nombre d’images à 5. Pour ce faire, ils ont créé des images mêlant plusieurs chiffres ensemble. Ces images ont ensuite été fournies à l’IA avec des étiquettes « hybrides » capturant les caractéristiques partagées entre différents chiffres.
Par exemple, le chiffre 3 présente des similitudes avec le chiffre 8. Une image peut donc être étiquetée comme représentant à 60% le chiffre 3, à 30% le chiffre 8, et à 10% le chiffre 0.

Machine Learning : le LO-Shot Learning permet aux petites entreprises d'accéder à l'IA
Après cette première tentative réussie de LO-shot learning, les chercheurs ont tenté de trouver les limites de cette méthode. Ils se sont alors aperçus que même deux exemples peuvent suffire à encoder un nombre illimité de catégories distinctes.
Pour le démontrer, l’équipe s’est basée sur l’un des algorithmes de Machine Learning les plus simples : le k-nearest neighbor (kNN) ou méthode des k plus proches voisins. Cette méthode permet de classifier des objets en utilisant une approche graphique.
Une série de petits ensembles de données synthétiques a été créée, avec des étiquettes hybrides. L’algorithme a ensuite été capable de séparer le schéma en davantage de catégories qu’il n’y avait de points de données.
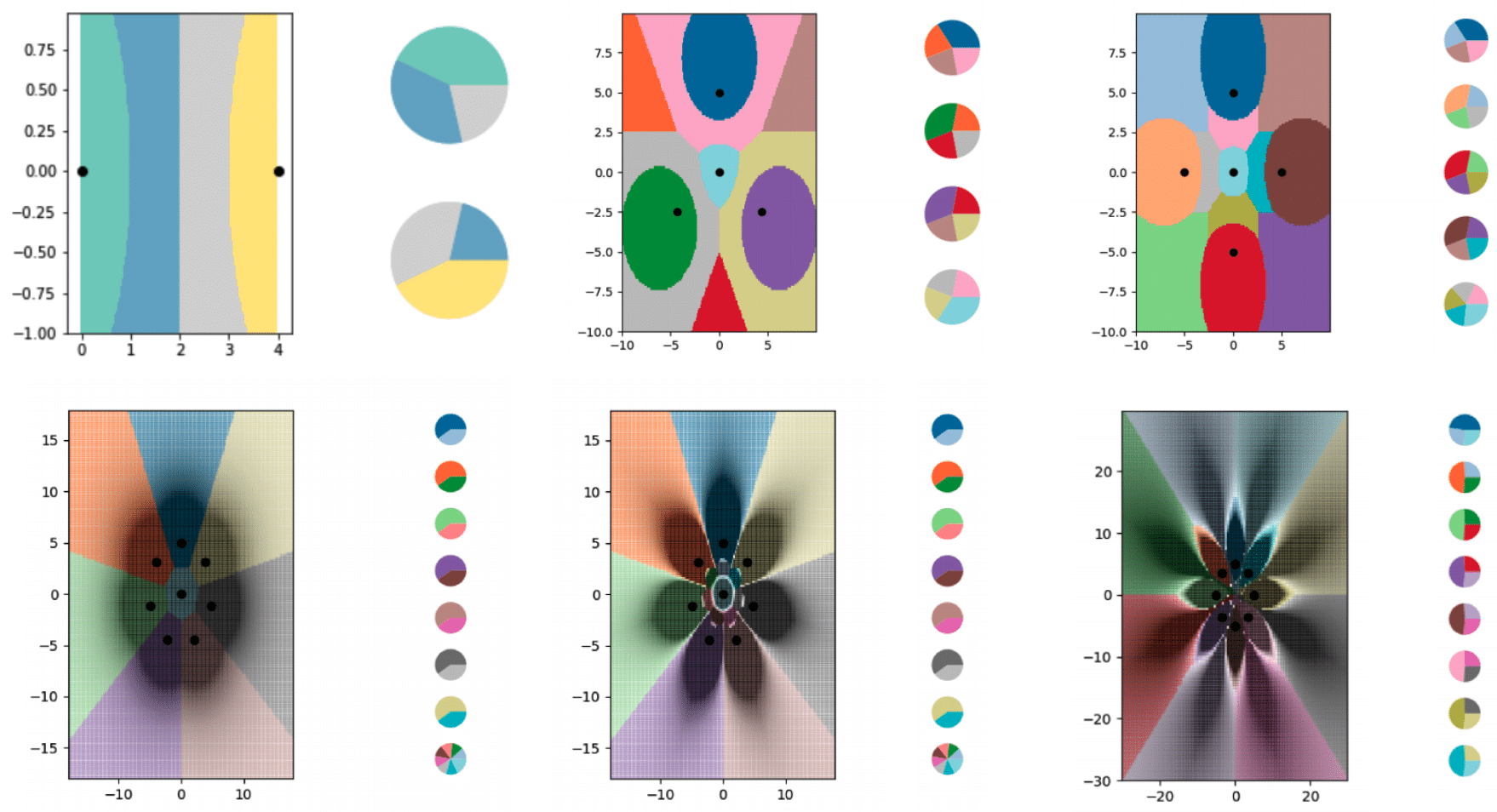
Néanmoins, le concept de LO-shot learning présente encore des faiblesses. S’il est applicable à un algorithme visuel et interprétable comme le kNN, les réseaux de neurones sont bien plus complexes. Il est donc très difficile de concevoir les étiquettes.
Par ailleurs, la méthode de distillation des données requiert un vaste ensemble de données initial pouvant être compressé. À présent, les chercheurs travaillent à une technique permettant l’ingénierie de ces Data Sets synthétiques, manuellement ou à l’aide d’un autre algorithme.
Malgré ces limites, le LO-shot learning pourrait s’avérer très utile pour réduire la puissance de calcul, le temps et la quantité de données nécessaires à l’entraînement des modèles d’intelligence artificielle. Ainsi, l’IA pourrait devenir accessible aux entreprises et aux industries jusqu’à présent freinées par ces exigences.
Vous savez désormais ce qu’est le LO-shot Learning. Pour plus d’informations sur le même sujet, découvrez notre dossier complet sur le Machine Learning et notre focus sur l’algorithme des k-moyennes.








