
Les caractères japonais sont principalement répartis en 2 catégories :
- Kanji : dérivés du chinois et servent à lire et écrire une partie du japonais en étant associés à des kanas
- Les kanjis comportent entre 2000 et 4000 caractères
- Kana : servent à noter phonétiquement la langue japonaise et sont constitués de 2 sous-groupes
- Hiragana : 48 caractères
- Katakana : 48 caractères
Étant dans un problème d’apprentissage supervisé et au regard de la puissance de calcul que nous avions à disposition, nous nous sommes limités à la reconnaissance des kana.
Pour les besoins de notre étude, nous nous sommes basés sur le jeu de données du site ETL Character Database qui nous fournissait des images de kanas compressées, toutes en niveaux de gris.
Nous avions donc à disposition environ 6100 Hiragana et 10600 Katakana écrits respectivement par 120 et 106 personnes qui devaient écrire 2 ou 3 fois chaque kana.

Fig. 2.1 Extrait de la base de données brutes Hiragana
Les caractères de la base étaient concaténés dans des images que nous avons dû séparer, ainsi nous avons pu faire le travail de reconnaissance sur chaque kana individuellement.
Après observation détaillée des bases de données brutes des Hiragana et Katakana, nous avons remarqué que notre set d’étude était assez bruité, comme nous pouvons le voir ci-dessous :

Fig. 2.2 Extraits de Hiragana bruts
Initialement nous pensions que le bruit pourrait biaiser notre étude, donc nous avons appliqué nos algorithmes sur nos données brutes et filtrées afin d’évaluer ce biais. Ci-dessous, voici des extraits de nos kanas filtrés :

Fig. 2.3 Extraits de Katakana filtrés
Ci-dessous, nous pouvons voir que notre jeu de données était assez équilibré pour les Hiragana et Katakana :
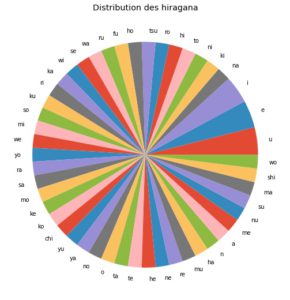
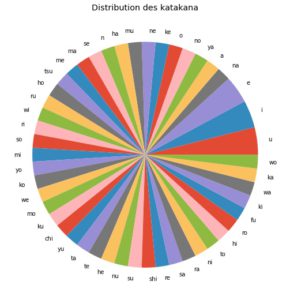
Fig. 2.4 Distribution des Hiragana et Katakana dans la base d’images
Nous avons retenu 4 modèles classiques de Machine Learning, conjugués d’un Voting Classifier afin de résoudre notre problème de classification :
Nous avons tenté d’optimiser ces modèles indépendamment les uns des autres et réaliser ce travail sur nos données brutes et filtrées avec Canny (extracteur de contours), ainsi avons-nous pu voir si la réduction du bruit en entrée influe sur les performances des modèles. Puis nous avons combiné chaque modèle avec ses meilleurs paramètres pour le Voting Classifier.
Nous avons utilisé 80% des données pour l’entraînement, et 20% des données restantes pour le test. Afin de pouvoir comparer les performances des divers modèles, nous avons fixé ces ensembles d’entraînement et de test.
Enfin, nous avons obtenu les scores de prédictions ci-dessous :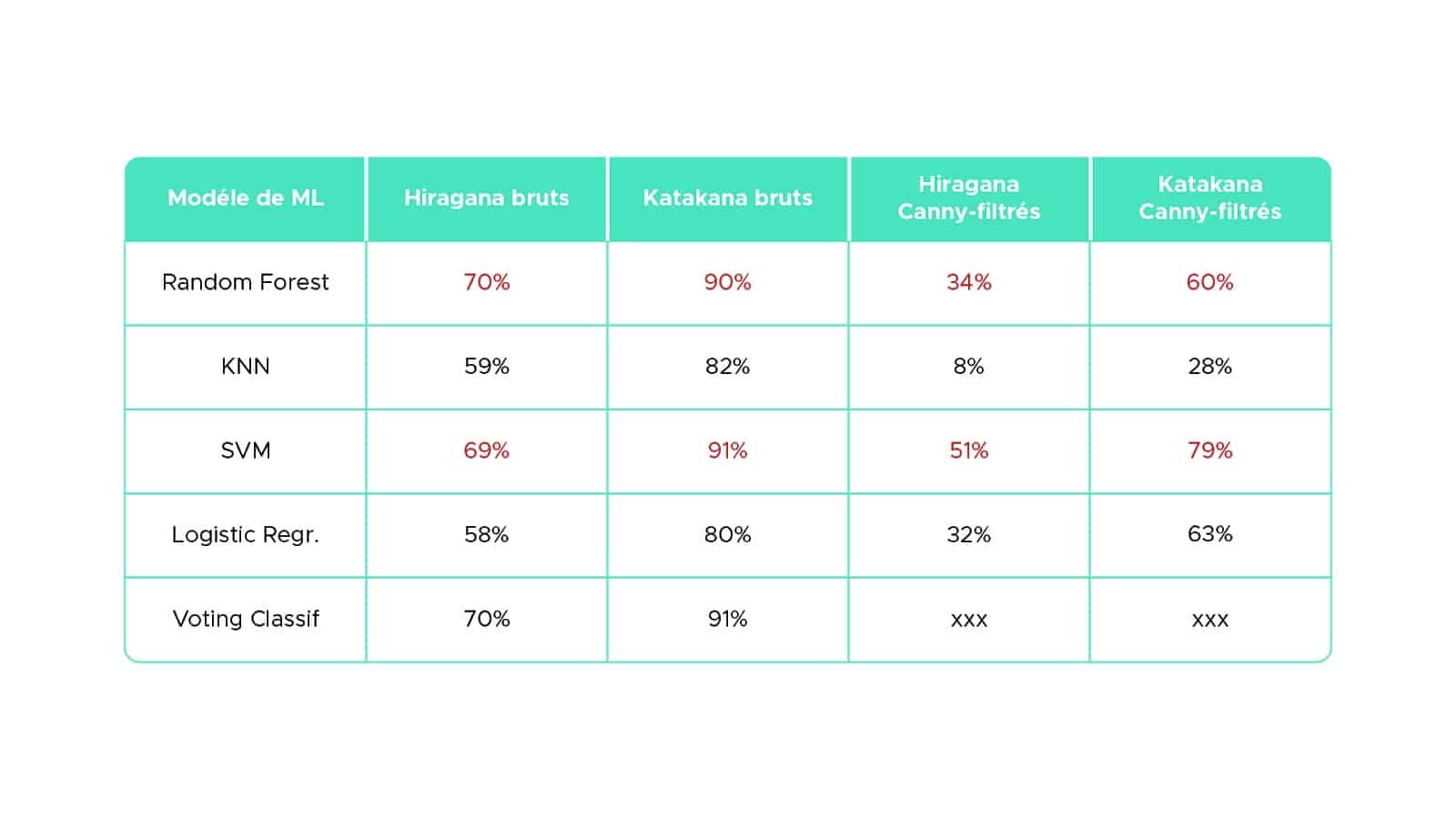
Les scores de prédictions
La première remarque intéressante que nous pouvons faire est que contrairement à l’hypothèse que nous avions formulée au début, le filtrage de nos images dégrade la qualité de nos prédictions.
Ensuite, le modèle SVM semble donner les meilleurs résultats en termes de prédiction, ce qui est cohérent avec le fait qu’il soit réputé performant pour les problématiques de classification d’image. Nous avons ensuite utilisé le Voting Classifier pour tenter d’optimiser les résultats. Cependant, le gain de score obtenu est trop faible par rapport au temps de calcul nécessaire. Si l’on reste à ce niveau-là d’étude, les modèles les plus efficaces de Machine Learning à utiliser sont le Random Forest ou le SVM pour la reconnaissance de kanas.
Enfin, les Katakana semblent plus faciles à prédire que les Hiragana. En s’intéressant plus précisément à la forme de ces kanas, cela semble logique, car la forme des Hiragana est bien plus “arrondie” et complexe que celle des Katakana (cf. figures 2.2, 2.3).
Devant les limites observées par les algorithmes de Machine Learning pour notre étude, nous avons embrayé sur du Deep Learning avec des réseaux de neurones CNN (Convolutional Neural Network).
Modèle CNN utilisé
Nous avons développé l’architecture CNN ci-après (Fig. 2.5) :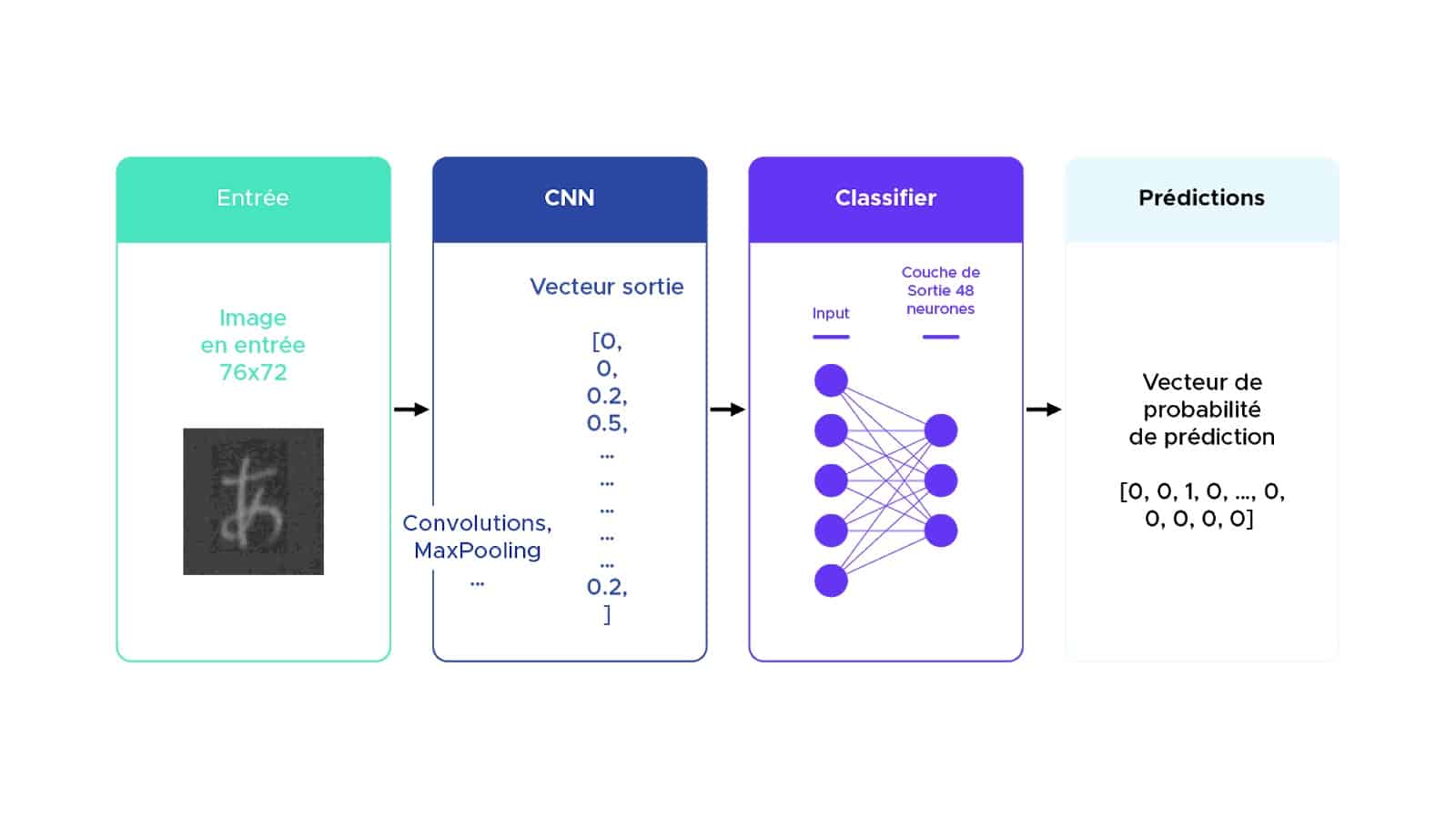
Fig. 2.5 : Architecture du modèle CNN utilisé
Ci-après le détail des couches constituant le modèle CNN utilisé (Fig. 2.6) :
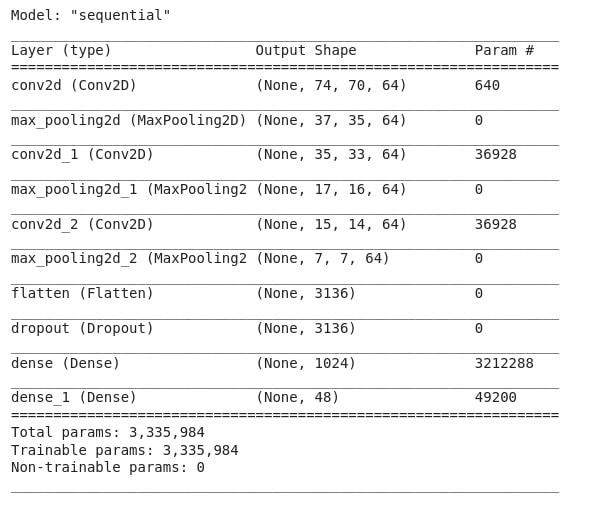
Fig. 2.6 Résumé du modèle CNN utilisé
Avec ce modèle CNN, nous obtenions :
| Métrique | Hiragana | Katakana |
| Score | 89% | 99% |
Pour les Hiragana, nous avons obtenu des résultats assez satisfaisants 89% et une courbe qui converge vers un maximum et s’est stabilisée vers cette valeur, après un entraînement de 50 epochs.
Sur les Katakana, sur le jeu de données de test, nous avons obtenu des résultats très suffisants de 99% et une courbe qui converge vers un maximum et s’est stabilisée vers cette valeur, après un entraînement de 50 epochs.
Nous pouvons noter que nous avons déjà un gros gain de score par rapport aux modèles de Machine Learning utilisés.
Bien que les résultats obtenus étaient assez satisfaisants avec le modèle CNN utilisé, nous avons voulu optimiser cette approche en faisant de la data augmentation : ceci est un moyen permettant à partir d’un jeu de données de multiplier les données disponibles pour l’entraînement du réseau afin de permettre d’avoir plus de données pour réaliser l’entraînement et la mise à jour des poids du réseau.
Avec la data augmentation, nous obtenions :
| Métrique | Hiragana | Katakana |
| Score | 95% | 99% |
Ce réseau est très performant :
- Sur les Katakana, un score supérieur à 99% pour la reconnaissance des caractères
- Sur les Hiragana, un score supérieur à 95% pour la reconnaissance des caractères
Par manque de temps, nous n’avons pas pu exploiter toutes les pistes afin d’améliorer et optimiser notre modèle, voire faire un modèle pour chaque type de kana, un spécifique pour les Hiragana et un autre pour les Katakana.
1. Modèles de Machine Learning
Afin d’améliorer la précision des algorithmes de Machine Learning utilisés, nous pouvons envisager :
- Transfer Learning
Création d’un modèle hybride combinant les meilleurs modèles de Machine Learning (SVM et Random Forest) ou Machine/Deep Learning, notamment pour augmenter les performances sur les Hiragana
- Autre méthode d’élimination du bruit
Nous n’avons eu le temps que de tester le filtre Canny pour faire la suppression de bruit sur nos caractères en entrée, mais celui-ci n’est peut-être pas adapté à notre problématique. L’utilisation d’un autre filtre donnerait peut-être de meilleurs résultats.
- “Généralisation” du modèle
Dans le cadre de notre projet, nous n’avons utilisé que des modèles permettant de faire de la reconnaissance sur un seul caractère à la fois. L’utilisation de modèles fonctionnant sur des séquences de caractères donnerait une dimension beaucoup plus grande à notre projet en termes d’applications.
2. Modèle de Deep Learning
Afin d’améliorer notre modèle CNN (déjà performant), nous pouvons envisager :
- Optimisation de l’architecture réseau
- Nombre de couches de Convolutions / Pooling
- Paramètres associés aux couches de Convolutions et de Pooling (strides, filters, kernel_size…)
- Couches de Regularization (limitation de l’over-fitting)
- Optimisation du traitement des données
- Paramètres de transformation d’images (rotation, zoom, flip …)
- Nombre de transformations
- Nombre d’images d’entraînement
- Assemblage de modèles
- Il est possible d’assembler plusieurs modèles différents
- Les prédictions sont alors moyennées entre les différents modèles
- “Généralisation” du modèle
Dans le cadre de notre projet, nous n’avons utilisé que des modèles permettant de faire de la reconnaissance sur un seul caractère à la fois. L’utilisation de modèles fonctionnant sur des séquences de caractères donnerait une dimension beaucoup plus grande à notre projet en termes d’applications.








