Les expressions régulières (regex) sont des outils indispensables en informatique pour manipuler, rechercher, et transformer du texte. Leur puissance réside dans leur capacité à traiter efficacement des ensembles complexes de données textuelles. Dans cet article vous découvrirez un guide complet pour apprendre tout ce qu’il faut sur les regex, leurs usages, et leurs implications.
Qu’est-ce qu’une expression régulière ?
Une expression régulière est une séquence de caractères utilisée pour définir un motif (pattern). Ce motif permet de rechercher, extraire ou modifier des chaînes de caractères spécifiques au sein d’un texte. À l’instar d’un langage universel, les regex sont compatibles avec de nombreux environnements, comme JavaScript, Python, PHP, ou encore C#.
Par exemple :
- La regex \d{5} correspond à une suite de cinq chiffres.
- La regex ^Bonjour identifiera toute chaîne de caractères débutant par « Bonjour »

À quoi sert une expression régulière ?
Les regex ne sont pas réservées aux développeurs : elles trouvent leur utilité dans le web scraping, la validation de données (emails, numéros de téléphone), ou encore l’analyse SEO via des outils comme Google Analytics.
Les regex peuvent aussi servir pour :
- Rechercher et remplacer du texte : Par exemple, supprimer des balises HTML inutiles dans un fichier.
- Valider des entrées utilisateur : Vérification d’adresses email, de mots de passe ou de formats spécifiques.
- Automatiser des tâches répétitives : Extraire des données précises dans des fichiers volumineux.
- Améliorer le référencement naturel (SEO) : Configurer des filtres dans Google Search Console ou segmenter des rapports dans Looker Studio.
Voici un exemple d’une regex qui permet de vérifier un numéro de téléphone, conformes au standard E.164 :
- ^\+?[1-9]\d{1,14}$
Une technologie controversée ?
Bien que puissantes, les regex suscitent parfois des débats en raison de leur complexité apparente et de leur impact sur les performances lorsqu’elles sont mal utilisées.
Points forts :
- Polyvalence : Applicables dans des contextes variés (développement, data science, SEO).
- Compatibilité universelle : Fonctionnent sur la plupart des langages et outils.
- Efficacité : Réduction significative du temps de traitement pour des tâches complexes.
Limites :
- Courbe d’apprentissage : Les regex peuvent intimider par leur syntaxe.
- Performances : Une regex mal conçue peut entraîner des ralentissements notables.
- Compréhension : Leur lecture peut être difficile pour des non-initiés.
Controverse :
Les critiques envers les regex se concentrent souvent sur leur complexité syntaxique et leur aspect déroutant pour les débutants. Pourtant, avec des outils comme Regex101 ou des guides bien structurés, il est possible de s’initier rapidement à cette compétence.
Cas d'application d'une regex
Les expressions régulières (regex) sont des outils indispensables pour de nombreux professionnels, qu’il s’agisse de développeurs, de spécialistes en données ou d’experts en SEO. Pour comprendre leur capacité à traiter efficacement les données, voici quelques exemples d’utilisation.
Gain de temps pour la gestion de contenu
Les regex permettent d’automatiser de nombreuses tâches fastidieuses. Par exemple :
- Modifier simultanément plusieurs éléments dans des fichiers HTML ou CSS.
- Rechercher des balises obsolètes dans un site web et les remplacer en une seule opération.
- Identifier des doublons ou des erreurs dans un texte volumineux.
Ces capacités sont particulièrement utiles dans la gestion de blogs ou de bases de données, où chaque seconde compte.
Validation des données (emails, numéros de téléphone, etc.)
Les regex sont couramment utilisées pour vérifier que les données fournies respectent un format précis.
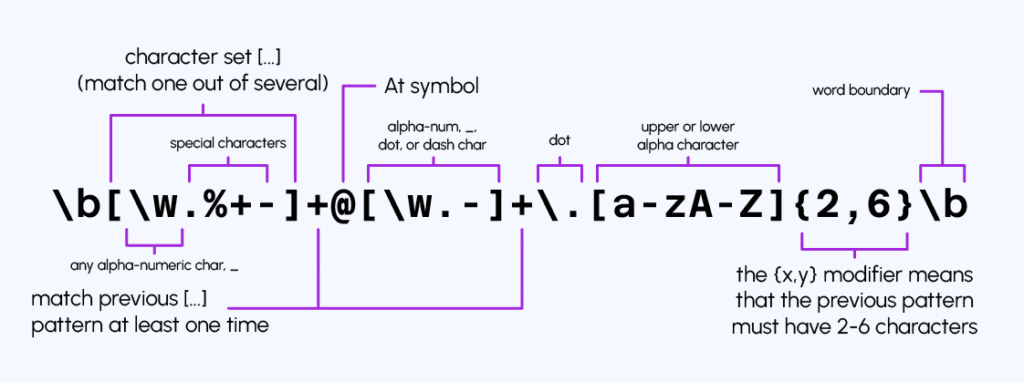
- Adresses email : ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
- Numéros de téléphone : ^\+?[1-9]\d{1,14}$
Recherche et remplacement de texte
Les regex sont particulièrement efficaces pour la recherche-remplacement à grande échelle.
- Remplacer tous les attributs style dans un code HTML : style= »([^ »]*) »
Extraction d’informations précises dans des fichiers volumineux
Dans des documents volumineux ou des bases de données complexes, les regex facilitent l’extraction de données spécifiques. Par exemple :
- Identifier les adresses email dans un fichier texte.
- Extraire les balises <title> et leurs contenus dans un document HTML.
- Collecter des données chiffrées, comme des prix ou des dates.
Cette application est essentielle dans des secteurs tels que la data science et le web scraping.
Applications dans le développement web et logiciel
Dans le développement, les regex sont omniprésentes. Elles permettent notamment de :
- Créer des systèmes de formulaires robustes en validant les entrées utilisateur (mots de passe, codes postaux, etc.).
- Générer des scripts d’automatisation pour manipuler du texte ou des données.
- Construire des API ou des outils d’analyse capables de détecter des motifs précis.
Les regex contribuent également à des projets plus complexes comme le traitement automatique du langage naturel (NLP) et la reconnaissance de motifs dans l’intelligence artificielle.
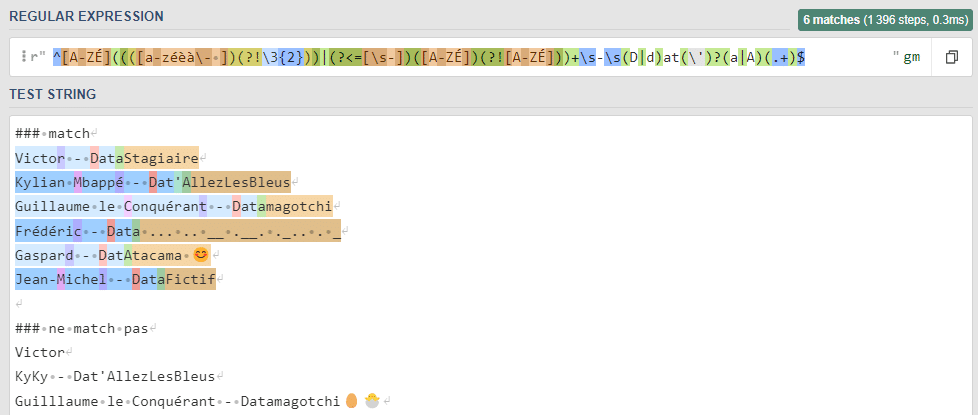
Comment fonctionne la syntaxe des regex ?
La syntaxe des expressions régulières (regex) peut sembler complexe au premier abord, mais elle repose sur un ensemble de règles simples et universelles. Apprendre ces bases est essentiel pour tirer pleinement parti des regex dans vos projets. Voici un guide détaillé pour vous accompagner.
Les bases d’une regex
Une regex est composée de caractères et de symboles spéciaux permettant de définir un modèle (pattern). Ce modèle peut correspondre à une chaîne de caractères précise ou à un ensemble plus large. Voici les éléments fondamentaux :
Les ancres (ex. ^, $)
Les ancres permettent de définir la position d’un motif dans une chaîne de caractères :
- ^ : Correspond au début d’une chaîne.
Exemple : ^Bonjour trouve toutes les chaînes commençant par « Bonjour ». - $ : Correspond à la fin d’une chaîne.
Exemple : fin$ trouve toutes les chaînes se terminant par « fin ». - ^mot$ : Correspond exactement à la chaîne « mot ».
Les quantificateurs (ex. , +, ?)
Les quantificateurs indiquent le nombre de fois qu’un élément doit apparaître dans une chaîne :
- * : Zéro ou plusieurs occurrences.
Exemple : abc* trouve « ab », « abc », « abcc », etc. - + : Une ou plusieurs occurrences.
Exemple : abc+ trouve « abc », « abcc », mais pas « ab ». - ? : Zéro ou une occurrence.
Exemple : abc? trouve « ab » et « abc ». - {n} : Exactement n occurrences.
Exemple : a{3} trouve « aaa ». - {n,} : Au moins n occurrences.
Exemple : a{2,} trouve « aa », « aaa », etc. - {n,m} : Entre n et m occurrences.
Exemple : a{2,4} trouve « aa », « aaa », « aaaa ».
Les opérateurs logiques (ex. |)
Les opérateurs permettent d’ajouter de la flexibilité :
- | : Correspond à l’une des options spécifiées.
Exemple : chien|chat trouve « chien » ou « chat ». - () : Les parenthèses peuvent être utilisées pour grouper des options.
Exemple : (chien|chat)s trouve « chiens » ou « chats ».
Les classes de caractères (ex. [a-z], \d)
- Les classes de caractères permettent de définir des ensembles ou des types de caractères :
- [a-z] : Toutes les lettres minuscules.
- [A-Z] : Toutes les lettres majuscules.
- \d : Tous les chiffres (équivalent à [0-9]).
- \w : Tous les caractères alphanumériques (lettres, chiffres et _).
- \s : Tous les espaces (y compris les tabulations et sauts de ligne).
- . : Tout caractère (sauf les retours à la ligne).
Les groupes (capturant et non-capturant)
Les groupes permettent d’isoler des parties spécifiques d’une chaîne :
- Groupes capturant : Enfermés entre parenthèses (…). Ils enregistrent le contenu pour un traitement ultérieur.
Exemple : (ab)c capture « ab » et trouve « abc ». - Groupes non-capturant : Préfixés par ?: pour ne pas enregistrer le contenu.
Exemple : (?:ab)c trouve « abc » sans capturer « ab ».
Fonctionnement des groupes lors d’un remplacement
Les groupes capturant sont souvent utilisés avec des opérations de remplacement. Chaque groupe est identifié par un numéro ($1, $2, etc.), correspondant à son ordre dans la regex.
Exemple :
- Regex : (h[ae]llo)
- Texte : « hello world »
- Remplacement : $1 world
- Résultat : « hello world ».
Les opérations de recherche-remplacement
Les regex sont extrêmement puissantes pour la recherche-remplacement dans des fichiers ou du code.
Exemple simple : Supprimer tous les attributs style d’un code HTML :
style= »([^ »]*) »
- Cette regex identifie tous les attributs style et leur contenu.
Exemple complexe : Modifier tous les titres de niveau 2 (<h2>) :
(<h2.*?>).*?(</h2>)
- Cette regex capture le contenu des balises <h2> et permet de le remplacer sans affecter la structure.
Les caractères génériques (wildcards)
Les caractères génériques ou jokers permettent de matcher une large gamme de motifs :
- . : Représente tout caractère unique (lettre, chiffre ou symbole).
Exemple : a.c trouve « abc », « a1c », mais pas « ac ». - * : Correspond à une séquence quelconque (incluant zéro caractère).
Exemple : .* trouve tout, de « » (vide) à des textes très longs. - ? : Correspond à un caractère optionnel.
Exemple : colo?r trouve « color » et « colour ».
Quels outils pour maîtriser les regex ?
Maîtriser les expressions régulières (regex) nécessite non seulement une bonne compréhension de leur syntaxe, mais aussi l’utilisation d’outils adaptés et quelques astuces pratiques. Voici les ressources et conseils indispensables pour devenir un expert en regex.
regex101 : une plateforme incontournable
Regex101 est une plateforme en ligne gratuite qui simplifie grandement l’apprentissage et l’utilisation des regex. Elle permet de :
- Tester vos regex en temps réel.
- Identifier rapidement les erreurs grâce à des explications détaillées.
- Visualiser les groupes capturant et leurs correspondances.
- Choisir parmi différentes saveurs de regex (JavaScript, Python, PHP, etc.).
Autres outils (Regex Generator, Regex Tester, etc.)
Outre regex101, plusieurs autres outils peuvent vous aider à perfectionner vos compétences en regex :
- Regex Generator : Idéal pour générer automatiquement des regex en fonction des critères définis.
- Regex Tester : Permet de tester des regex sur des textes longs et complexes, tout en offrant des fonctionnalités de prévisualisation.
- Expresso : Un logiciel téléchargeable qui combine test et débogage.
- Notepad++ et VSCode : Ces éditeurs de texte intègrent des fonctionnalités regex natives pour la recherche et le remplacement.
Ces outils sont parfaits pour optimiser vos workflows, notamment dans le cadre de la gestion de contenu ou du développement logiciel.
Astuces et bonnes pratiques
1 - La combinaison point, étoile et point d’interrogation (.*?)
La séquence .*? est l’un des motifs les plus importants en regex. Elle correspond à n’importe quelle séquence de caractères (incluant zéro caractère) de manière non-greedy, c’est-à-dire qu’elle s’arrête dès qu’une correspondance est trouvée.
Exemple :
<h1>.*?</h1>
Cette regex capture toutes les balises <h1> avec leur contenu, peu importe leur complexité.
2 - Tester vos regex encore et encore
La pratique est essentielle pour éviter les erreurs. Testez vos regex dans différents scénarios et adaptez-les en fonction des spécificités de vos données. Par exemple :
- Tester avec des chaînes en plusieurs langues pour vérifier la compatibilité.
- Essayer sur des formats variés, comme des numéros de téléphone internationaux.
3 - Anticiper les exceptions
Certaines données ou structures textuelles peuvent contenir des exceptions. Adoptez une approche proactive pour éviter les erreurs :
- Utilisez des lookaheads et lookbehinds pour inclure ou exclure des motifs spécifiques.
- Créez des règles précises pour ignorer les doublons ou traiter des cas uniques.
Exemple :
\b(\w+)\b(?=.*\1)
4 - Attention à la casse
Les regex sont sensibles à la casse par défaut. Si vous devez effectuer une recherche insensible à la casse, ajoutez le modificateur /i à votre regex.
Exemple :
bonjour /i
Cette regex trouvera « bonjour », « Bonjour », ou « BONJOUR ».
5 - Clarté et concision
Une regex concise est plus lisible et facile à maintenir. Évitez les séquences inutiles :
- Longue : [0-9][0-9][0-9]
- Optimisée : [0-9]{3} ou simplement \d{3}
Conservez vos regex fréquentes dans un document ou un outil comme Notion pour un accès rapide.

Qu’est-ce qu’une saveur de regex ?
Les expressions régulières (regex) sont universelles, mais elles présentent des variations en fonction des environnements dans lesquels elles sont utilisées. Ces différences, appelées « saveurs » (flavors), définissent les spécificités syntaxiques et fonctionnelles des regex dans différents langages ou outils. Comprendre ces nuances est essentiel pour tirer le meilleur parti des regex dans vos projets.
Une saveur de regex fait référence à la variante syntaxique et aux fonctionnalités prises en charge par un langage ou un outil spécifique. Bien que les concepts de base soient généralement les mêmes (comme les classes de caractères ou les quantificateurs), chaque saveur a ses propres particularités.
Par exemple :
- Certains langages prennent en charge les lookbehinds (regarder en arrière), tandis que d’autres non.
- Les modificateurs comme /i (insensibilité à la casse) ou /g (global) varient en syntaxe selon les environnements.
Les saveurs les plus courantes sont utilisées dans des langages tels que JavaScript, Python, PHP, ou dans des outils comme Excel et Google Sheets.
Différences entre les saveurs
Regex en JavaScript
Le langage JavaScript utilise une saveur de regex largement utilisée dans le développement web. Elle est idéale pour valider des formulaires, manipuler des chaînes de caractères et travailler avec des APIs.
Caractéristiques principales :
- Syntaxe : Les regex sont définies entre deux barres obliques /…/.
- Modificateurs : /i (insensible à la casse), /g (recherche globale), /m (multilignes).
const regex = /^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$/; console.log(regex.test(« email@example.com »)); // Retourne true
Regex en Python
Python propose une bibliothèque dédiée, appelée re, qui offre une grande flexibilité pour travailler avec des regex.
Caractéristiques principales :
- Syntaxe : Les regex sont définies comme des chaînes brutes avec un préfixe r.
- Méthodes : re.match(), re.search(), et re.findall() pour diverses opérations.
import re
regex = r »^[A-Z][a-z]+$ »
if re.match(regex, « Bonjour »):
print(« Correspondance trouvée »)
Regex en PHP
Le langage PHP utilise la fonction preg_match() pour travailler avec les regex. Il est souvent utilisé dans des contextes de développement web.
Caractéristiques principales :
- Syntaxe : Les regex sont définies entre des barres obliques /…/.
- Fonctionnalités avancées : Support des lookbehinds et des groupes capturant.
$pattern = « /\d{3}-\d{2}-\d{4}/ »;
$string = « Mon numéro est 123-45-6789. »;
if (preg_match($pattern, $string)) {
echo « Correspondance trouvée »;
}
Regex en Excel
Excel ne supporte pas directement les regex, mais des solutions existent via :
- Power Query : Pour manipuler des chaînes de texte avec des expressions similaires aux regex.
- VBA (Visual Basic for Applications) : Pour intégrer des regex via des scripts personnalisés.
Dim regex As Object
Set regex = CreateObject(« VBScript.RegExp »)
regex.Pattern = « ^\d{5}$ »
If regex.Test(« 75001 ») Then
MsgBox « Correspondance trouvée »
End If
Regex en Java
En Java, les regex sont intégrées dans la bibliothèque java.util.regex. Elles sont couramment utilisées pour manipuler des fichiers texte ou valider des données.
Caractéristiques principales :
- Syntaxe : Basée sur des méthodes comme Pattern et Matcher.
import java.util.regex.*;
Pattern pattern = Pattern.compile(« ^[0-9]{4}$ »);
Matcher matcher = pattern.matcher(« 2023 »);
if (matcher.find()) {
System.out.println(« Correspondance trouvée »);
}
Les expressions régulières (regex) sont des outils incontournables pour manipuler, analyser, et transformer du texte. Elles s’intègrent dans une multitude d’applications, allant de la validation de données à l’automatisation de tâches complexes. Toutefois, leur utilisation nécessite une bonne compréhension des concepts de base et des meilleures pratiques.








