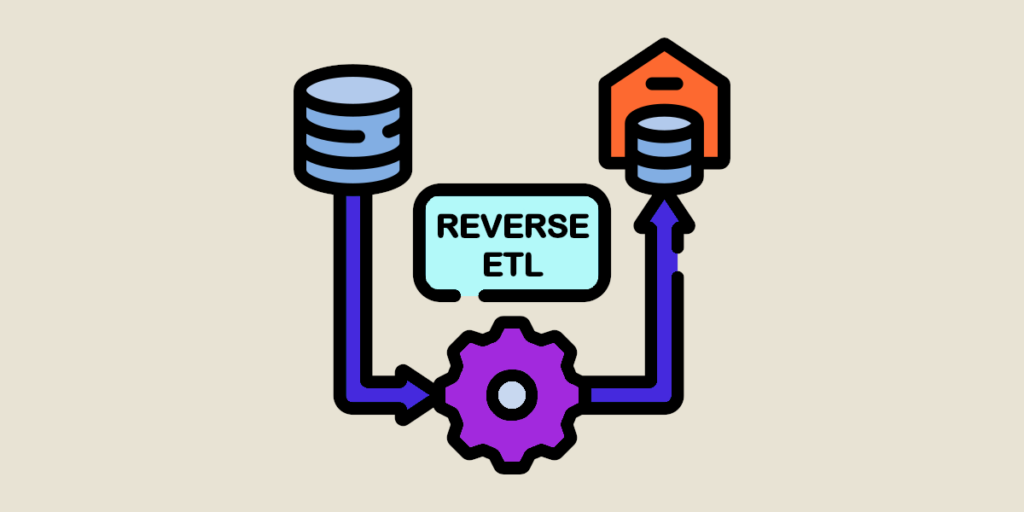
Si les données brutes se multiplient, les organisations doivent les transformer pour pouvoir exploiter les données disponibles et créer de la valeur. Traditionnellement, les entreprises suivaient le processus ETL pour traiter les données. Mais depuis quelques années, ce modèle change pour laisser place au reverse ETL. Alors de quoi s’agit-il ? Quelles sont les différences entre les deux méthodes ? Et quels sont les avantages du reverse ETL ? Les réponses sont dans cet article.
Qu'est ce que le Reverse ETL ?
- Extract : c’est l’extraction des données brutes depuis une multitude de sources (réseaux sociaux, CRM, site web, SIRH…)
- Load : c’est le chargement des données dans un entrepôt ou un lac de données.
- Transform : il s’agit de préparer et nettoyer les données pour les rendre propres à l’analyse. Les formats sont uniformisés, les doublons, les données obsolètes ou fausses sont supprimés.
Les outils de reverse ETL permettent de mieux valoriser les informations disponibles. En effet, les experts data peuvent extraire les données du data warehouse à des fins opérationnelles ou pour des applications métiers. Et comme une grande quantité de données est conservée au sein d’un espace de stockage, les capacités d’analyses sont plus poussées avec un modèle ELT.
Quelles différences entre les processus ETL et ELT ?
ETL, le processus de transformation traditionnelle
Le processus ETL (pour Extract, Transform, Load) est le modèle utilisé traditionnellement pour l’exploitation des données. La démarche est inversée, puisqu’il s’agit d’extraire, de transformer et de charger les données dans un lieu de stockage.
Le cloud data warehouse ne contient que des données préalablement nettoyées. Autrement dit, des données de qualité qui seront utilisées par les outils de business intelligence pour améliorer la prise de décision.
Si ce modèle était particulièrement efficace il y a quelques années, il ne permet plus forcément de répondre à l’augmentation des volumes de données. C’est pourquoi, les outils de reverse ETL sont apparus.
ELT, une évolution du process ETL
- Pour réaliser des analyses opérationnelles pertinentes, les équipes data ont besoin de quantités de données de plus en plus importantes. Ce qui n’était pas forcément le cas avec la stratégie Extract, Transform, Load.
- Mais surtout, les experts data avaient besoin de données en temps réel pour de nombreuses analyses. Or, avec le processus ETL, les données étaient d’abord transformées, puis stockées. Comme ce processus prenait du temps, les données disponibles se limitent simplement à l’analyse stratégique sur le moyen et long terme.
Le reverse ETL permet justement de pallier ces problèmes. Les experts data ont accès à des quantités exponentielles de données actualisées. En fonction des besoins des experts métiers à l’instant T, ils peuvent ainsi sélectionner les datasets les plus pertinents parmi un large éventail d’informations disponibles. Le reverse ETL permet ainsi de synchroniser des analyses opérationnelles avec des données de qualité. Et tout ça, depuis un espace centralisé et réutilisable.
Aujourd’hui, c’est l’un des composants incontournables d’un modern stack data.
Quels sont les avantages du reverse ETL ?
Le reverse ETL rencontre un véritable succès auprès des organisations grâce aux nombreux avantages qu’il offre.
La simplification du système d’information
La centralisation des données de qualité
Avec le reverse ETL, tous les collaborateurs de l’entreprise ont accès à une source unique de données : l’entrepôt ou le lac de données de l’entreprise. Et comme ces dernières sont transformées et nettoyées par les experts data, tout le monde doit pouvoir y accéder facilement. In fine, le processus ELT favorise la diffusion des données en libre-service.
La valorisation des données
Avec le modèle ETL traditionnel, les données stockées sont principalement utilisées pour les outils de BI. Autrement dit, elles n’étaient accessibles que par des experts qui maîtrisent ces solutions.
À l’inverse, le reverse ETL a pour objectif de favoriser l’analyse opérationnelle et les applications métiers. Au-delà des logiciels de business intelligence, les données stockées doivent pouvoir être exploitées par différents outils de gestion (RH, finance, marketing…). Ce faisant, les données peuvent apporter davantage de valeur ajoutée au sein de l’entreprise.
Le gain de productivité
En inversant le processus ETL, le modèle ELT permet de gagner un temps considérable dans le traitement des données. Et cela se répercute sur l’ensemble de l’organisation. D’une part, les experts data perdent moins de temps à chercher et transformer les informations pertinentes. D’autre part, les équipes opérationnelles (marketing, commerciales, RH…) ont plus rapidement accès aux données en temps réel.
Ce gain de productivité permet à l’entreprise d’être plus efficace, de prendre de meilleures décisions et de réduire les coûts.
Le développement d’une culture data driven
En simplifiant l’accessibilité et l’utilisation des données, le reverse ETL participe directement à la démocratisation des données. La data n’est plus seulement l’apanage des data analysts, data scientists, data engineer et autres experts. Tous les membres de l’organisation doivent pouvoir accéder aux données dont ils ont besoin.
Bien évidemment, le rôle des experts data reste indispensable pour implémenter le processus ELT. Grâce à leur connaissance des requêtes SQL, du mapping de données, de l’analytics, … ils aident l’ensemble des collaborateurs à valoriser les données.
Ce qu’il faut retenir
- Pour répondre à l’augmentation croissante des données, les outils de reverse ETL se développent.
- Ces derniers modifient le processus de traitement, puisqu’il s’agit d’extraire toutes les données brutes, de les intégrer dans l’espace de stockage et de les transformer pour améliorer leur qualité.
- Les organisations appliquant cette méthode bénéficient ainsi d’un accès aux données plus simple et plus rapide. Elles peuvent alors créer de la valeur plus facilement et prendre des décisions plus éclairées.