Les architectures distribuées sont des systèmes d’informations distribuant et utilisant des ressources disponibles qui ne se trouvent pas au même endroit ou sur la même machine. Dans cet article nous allons expliquer en détail ce que sont ces architectures, nous verrons donc leur avantage par rapport aux autres architectures et comment on les utilise en pratique en Data Science.
Une architecture distribuée, c’est quoi ?
Avec l’évolution exponentielle de la technologie et la facilitation de l’accès à l’information, de plus en plus de systèmes informatiques comme des applications ou leur déploiement sont reliés entre eux par un réseau et communiquent des données. Ainsi, afin de réaliser un système complexe nécessitant l’exécution de plusieurs services interconnectés, les architectures monolithiques sont devenues inutilisables et obsolètes.
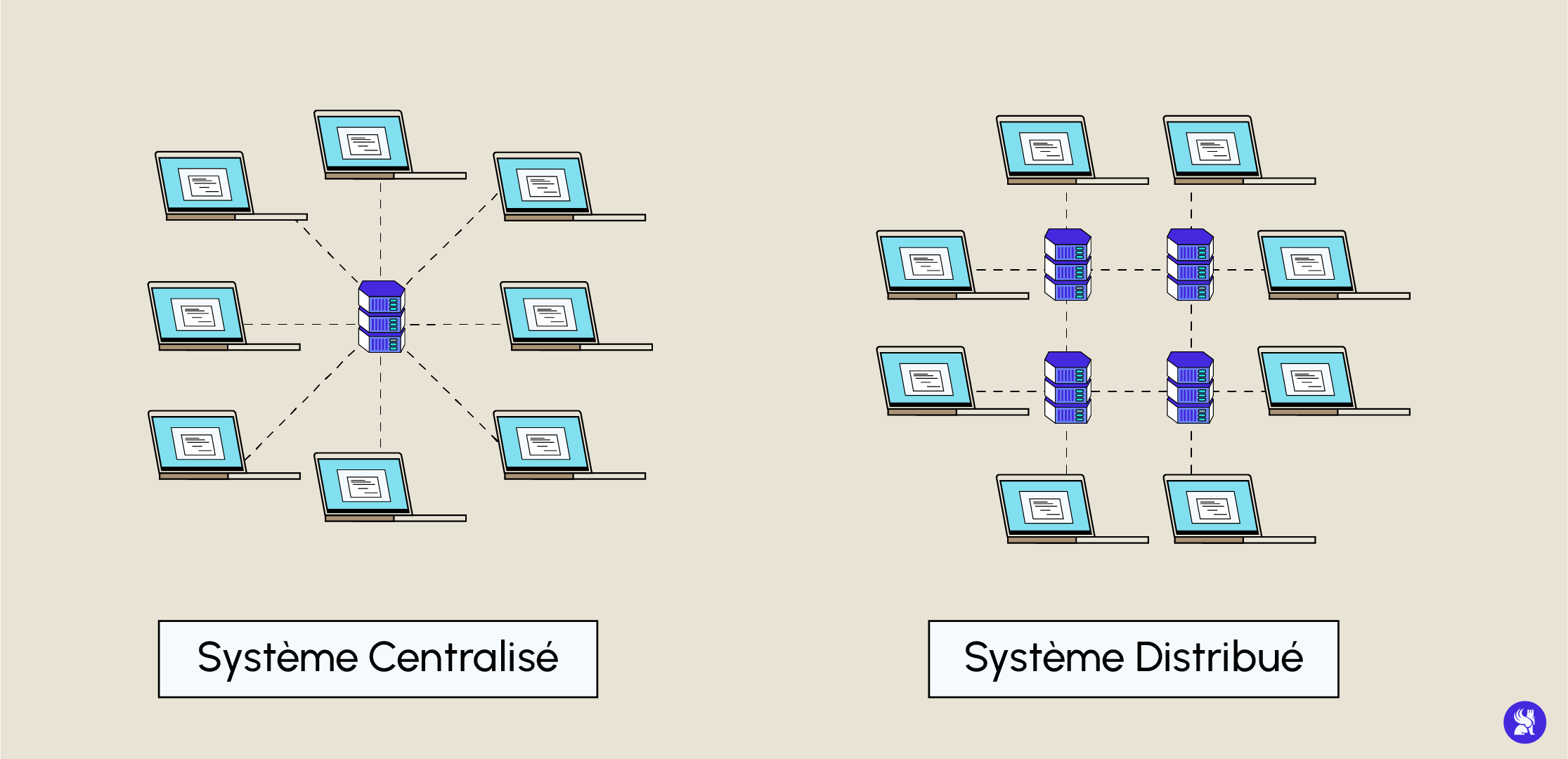
En effet, dans une telle architecture l’ensemble des ressources disponibles se trouvent au même endroit et sur la même machine et donc vouloir modifier une partie de celle-ci implique de devoir modifier toutes les parties (pour qu’elles restent cohérentes) ce qui n’est pas envisageable dans un système où potentiellement des milliers de services inter-communiquent.
Pour lutter contre les limites de l’architecture monolithique on peut utiliser une architecture distribuée, mais qu’est-ce que c’est exactement ?
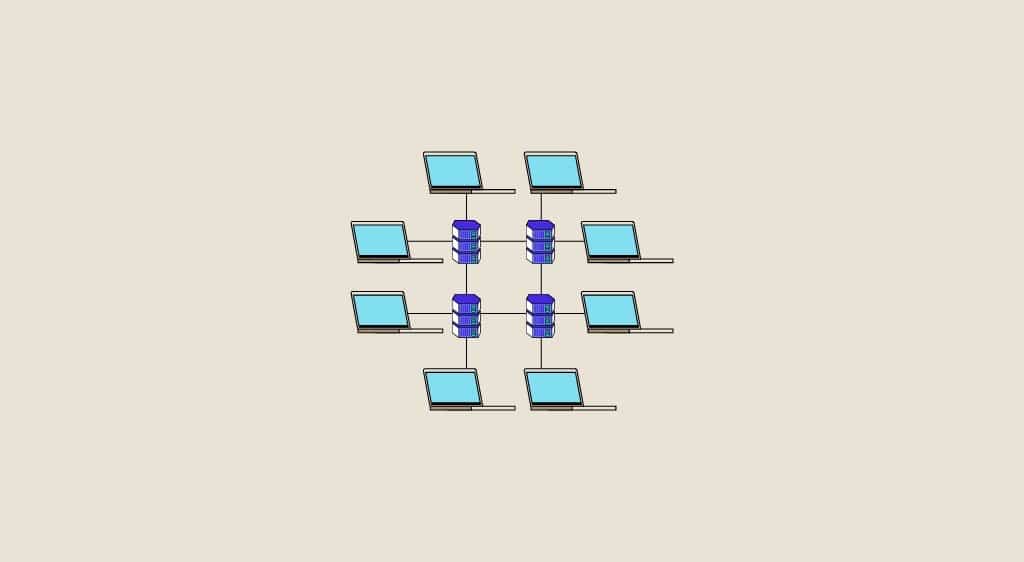
Une architecture distribuée est une architecture s’organisant exactement à l’opposé d’une architecture monolithique. En effet, là où l’architecture monolithique va centraliser toutes ses ressources et ses systèmes au même endroit et sur la même machine, l’architecture distribuée va se servir de ressources disponibles sur différentes machines réparties à différents endroits. Une telle architecture peut être à la fois un système d’information ou un réseau ou les deux. Internet est un exemple de réseau distribué puisqu’il ne possède aucun nœud central et accède à différentes ressources réparties sur plusieurs nœuds (réparties sur le réseau) qui communiquent par messages au travers du réseau. Une des caractéristiques des architectures distribuées est que chaque nœud peut fournir des fonctionnalités client serveur, c’est-à-dire qu’il peut agir à la fois comme fournisseur et consommateur de services ou de ressources. On a donc accès à un partage de ressource total.
Il y a une cinquantaine d’années, faire dialoguer deux machines au travers du réseau demandait une connaissance précise des protocoles réseaux et parfois même du matériel réseau. Avec la création de la programmation orientée objet, les architectures monolithiques ont laissé place aux architectures distribuées désormais viables grâce aux nouvelles bibliothèques de haut-niveau permettant à différentes machines de faire dialoguer plusieurs objets qui s’exécutent sur des machines différentes.
Ainsi, les architectures distribuées reposent sur la possibilité d’utiliser des objets distribués sur le réseau. Les objets distribués sur le réseau (et qui ne se trouvent pas au même endroit) communiquent par messages en s’appuyant sur des technologies spécifiques comme Common Object Request Broker Architecture ou CORBA qui permet à différents objets écrits en différents langages tels que C++ ou Java de communiquer entre eux. Un autre outil connu est le logiciel Java EE qui permet de faire communiquer plusieurs objets dans une architecture distribuée à l’aide de son catalogue de librairies spécialisées.
Aujourd’hui, un des inconvénients de ce type d’architecture provient paradoxalement de son atout initial : l’isolement des différents services et donc des équipes de développeurs travaillant sur ceux-ci de façon indépendante. En effet, à cause d’un potentiel éloignement géographique, de l’hétérogénéité des tâches abordées et de l’isolement des responsabilités techniques, l’architecture distribuée est sensible à une mauvaise maintenabilité qui peut générer des conséquences sérieuses sur les coûts ou encore la fonctionnalité des services. À force d’empiler des « blocs » de construction non maîtrisés et de façon indépendante, des risques de dérives exponentielles sont à craindre. L’architecture perdrait alors instantanément sa faculté à comprendre rapidement les différents services développés et leurs interconnexions.
Relation entre Big Data et architecture distribuée
Il est important de savoir que dans une architecture big data, la distribution est un élément clé. Avant, nous étions dans un système de scalabilité verticale, c’est-à-dire que l’on rajoutait de la RAM, du CPU, etc. pour résoudre tous problèmes liés au stockage ou à la puissance de calcul des ordinateurs. Le problème était que cela est très cher et que l’on utilisait des hardwares qui étaient voués à être jetés.
Depuis l’émergence du big data, nous sommes passés à une architecture de scalabilité horizontale pour résoudre ce problème. Cela signifie que l’on privilégie d’ajouter des ordinateurs dans une architecture pour résoudre les problèmes de big data. Cette architecture présente des avantages. Tout d’abord, il faut savoir que toutes les données sont répliquées à un certain facteur de réplication et partitionnées sur les différentes machines. Cela permet d’avoir une sécurité accrue au niveau des données. De plus, puisque nous utilisons différentes machines, les calculs sont parallélisables dans une architecture distribuée donc nous gagnons de la rapidité de calcul et la puissance de calcul est accrue. Enfin, le passage à l’échelle est plus facile. Imaginons que nous n’ayons plus de stockage dans nos machines, au lieu de changer d’ordinateur contre un ordinateur plus puissant (scalabilité verticale), nous pouvons rajouter une machine à notre architecture, ce qui permet de résoudre le problème de stockage.
Plus particulièrement, en Data Science, pour réussir à effectuer des calculs avec une architecture distribuée et à gérer le stockage entre les différents nœuds de cette architecture distribuée, on utilise principalement Hadoop. Ce framework est composé de trois sous-frameworks : HDFS, MapReduce et YARN.
HDFS est le gestionnaire de stockage dans Hadoop. Il permet de stocker les différents blocs de partitions sur les différents nœuds de l’architecture distribuée.
MapReduce est le système de calcul dans une architecture distribuée. Il effectue des calculs en parallèle sur les différents nœuds de l’architecture pour en ressortir un résultat final. Il fonctionne sous forme de clé/valeur comportant différentes étapes. La première est la phase de mapping qui va agréger la requête demandée en fonction d’une clé sur tous les blocs de notre document. Ensuite, il y a la phase de shuffle qui va trier les résultats des différentes agrégations en fonction de cette clé. Puis, il y a la phase de reducing qui va appliquer la requête (par exemple une somme) à nos différentes clés triées. Enfin, il y a la phase finale, qui va consister à faire une nouvelle agrégation en un seul nœud de nos reducing différents.
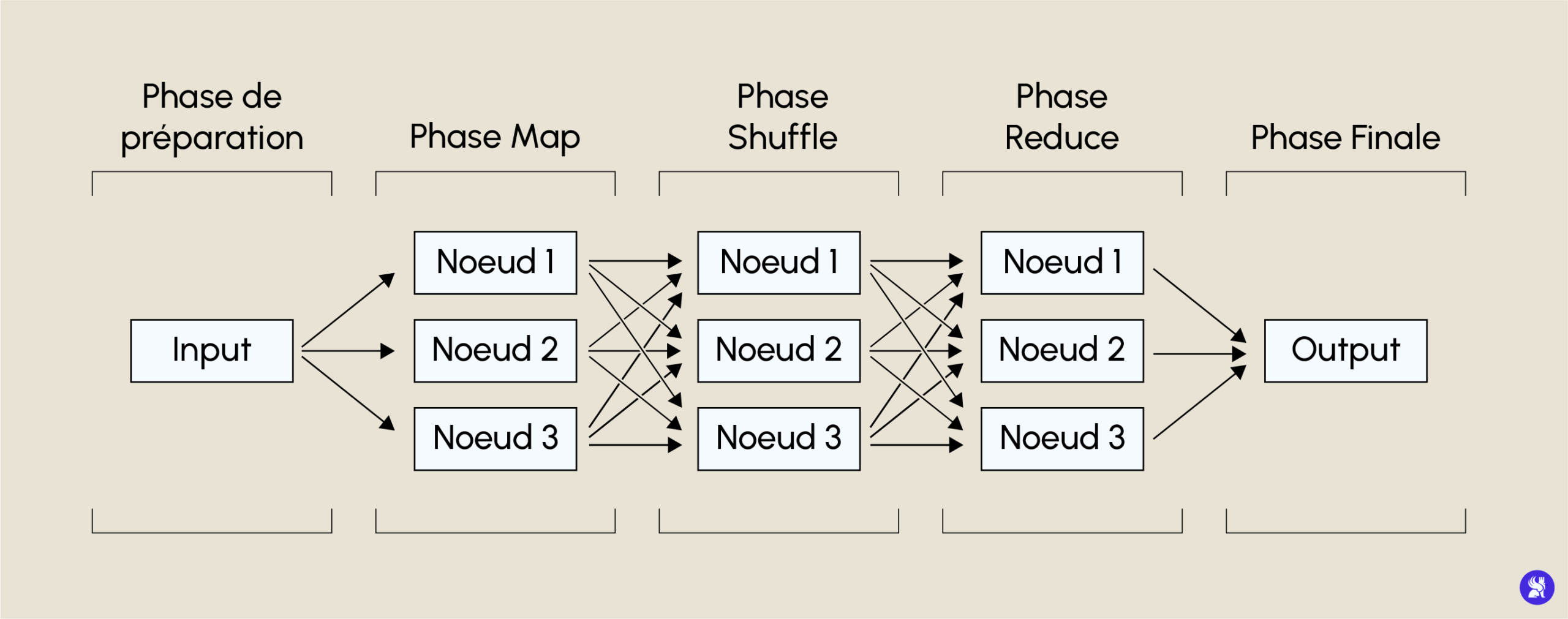
Le troisième sous-framework, YARN, est le gestionnaire d’orchestration de Hadoop. C’est lui qui va savoir comment répliquer les données, comment envoyer les différents blocs sur les différents nœuds et quelle partition utiliser pour effectuer le MapReduce.
Hadoop est évidemment un seul des nombreux outils qui existe pour construire des architectures distribuées, un autre outil beaucoup utilisé s’intitule Spark et est disponible en plusieurs langages de programmation : Scala, Python, Java et R.
Si vous voulez en savoir plus sur les architectures distribuées et comment les utiliser, n’hésitez pas à prendre RDV avec nos experts pour en apprendre davantage en Data Science et pour avoir des informations sur notre formation de Data Engineer dont vous pouvez retrouver la brochure ici !






